考完試了,老師考試范圍就是他的PPT(雖然我比較菜看不懂其中公式),造福學弟學妹攢人品,大家取需~
題型:單選20‘多選15’判斷10‘論述30’
必考:
計算題:
卷積網路計算(考了)
pooling計算
論述題:
過擬合解決方法(重點,一道多選一道簡答)
- dropout
- 降低維度,減小寬度,降低模型復雜度
- 引數正則化
- data augmentation
- early stopping
資料預處理一般方法:中心化、歸一化、白化、維數約簡
目標檢測RPN網路定義,在faster-RCNN中的作用(PPT上寫的我沒看懂,網上搜搜看吧)
pooling定義和作用: - 降維
- 實作非線性
- 擴大感受野
- 實作不變性
常用的CNN模型,簡述特點 - LeNet
- AlexNet
- VGG-16
- GoogleNet
- ResNet
- DenseNet
深度學習訓練一般步驟
沒考:
KNN,SVM原理
聚類學習Kmeans
梯度下降
目標檢測
LSTM:遺忘門,輸入門,輸出門
GRU有一個重置門和一個更新門(電梯門),重置門決定了如何把新的輸入與之前的記憶相結合,更新門決定多少先前的記憶起作用,GRU將LSTM里面的遺忘門和輸入門合并為更新門
課后習題:
- 假設有1000張5種不同動物的照片,分別簡述在監督學
習和無監督學習的條件下完成此項任務
監督學習:SVM,KNN,神經網路,決策樹
無監督學習:Kmeans進行聚類切割,k=5
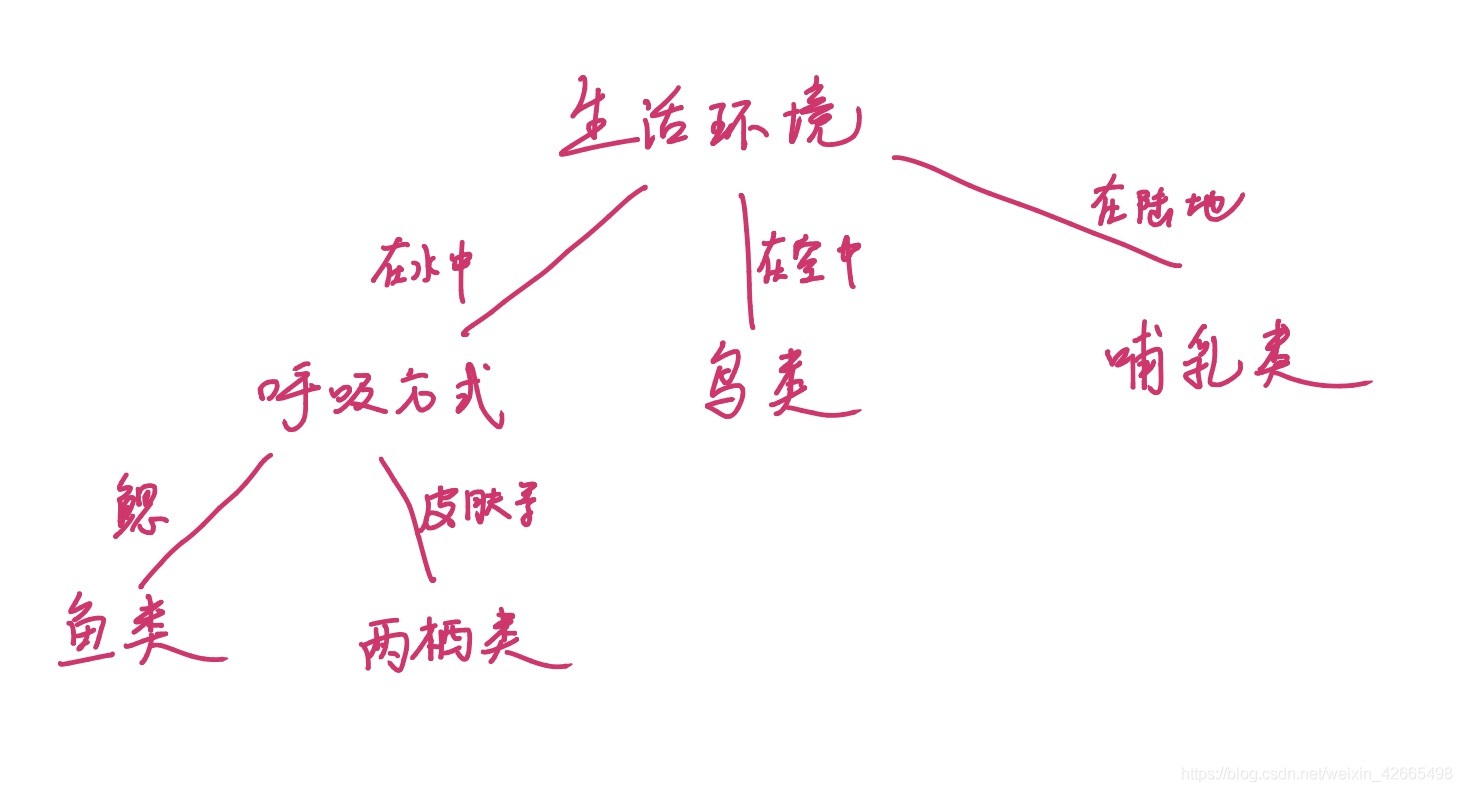
- 已知資料集中樣本為{貓,狗,虎,鯉魚,鯊魚,麻雀,
鷹,青蛙},請從生活環境、呼吸器官等角度構建決策樹,
將樣本分為哺乳類、鳥類、兩棲類、魚類等不同型別
選擇題
考試題
CNN中1x1 kernel 作用
聚合學習中單個模型直接相關度高還是低
SPPNet性能(多選)
監督學習CNN最后一層神經元和分類數相同,對嗎
如果把imagenet上訓練好的模型拿出,輸入一張白色圖片,那么它在所有分類上概率相等?
如果隨機初始化權重全部設為0,會出現什么結果?
決議:我們在線性回歸,logistics回歸的時候,基本上都是把引數初始化為0,我們的模型也能夠很好的作業,然后在神經網路中,把w初始化為0是不可以的,這是因為如果把w初始化0,那么每一層的神經元學到的東西都是一樣的(輸出是一樣的),而且在bp的時候,每一層內的神經元也是相同的,因為他們的gradient相同,
1、在實作前向傳播和反向傳播中使用的“cache”是什么?(D)
A.它用于跟蹤我們正在搜索的超引數,以加速計算,
B.用于在訓練期間快取代價函式的中間值,
C.我們使用它傳遞反向傳播中計算的變數到相應的前向傳播步驟,它包含對于前向傳播計算導數有用的變數,
D.我們使用它傳遞前向傳播中計算的變數到相應的反向傳播步驟,它包含對于反向傳播計算導數有用的變數,
決議:“快取”記錄來自正向傳播單元的值,并將其發送到反向傳播單元,這是鏈式求導的需要,
2、以下哪些是“超引數”?(ABEF)
A.隱藏層的大小
B.神經網路的層數
C.激活值
D.權重
E.學習率
F.迭代次數
G.偏置
3、下列哪個說法是正確的?(A)
A.神經網路的更深層通常比前面層計算更復雜的輸入特征,
B.神經網路的前面層通常比更深層計算更復雜的輸入特性,
4、下面關于神經網路的說法正確的是:A
A.總層數L為5,隱藏層層數為3,
B.總層數L為3,隱藏層層數為3,
C.總層數L為4,隱藏層層數為4,
D.總層數L為5,隱藏層層數為4,
決議: 網路層數按隱藏層數+2計算,輸入和輸出層不算作隱藏層,
5、在前向傳播期間,在層l的前向傳播函式中,您需要知道層l中的激活函式(Sigmoid,tanh,ReLU等)是什么, 在反向傳播期間,相應的反向傳播函式也需要知道第l層的激活函式是什么,因為梯度是根據它來計算的,這樣描述正確嗎?(A)
A.正確
B.錯誤
決議: 不同激活函式有不同的導數,在反向傳播期間,需要知道正向傳播中使用哪種激活函式才能計算正確的導數,
6、有一些功能具有以下屬性:
利用淺網路電路計算一個函式時,需要一個大網路(我們通過網路中的邏輯門數量來度量大小),但是(ii)使用深網路電路來計算它,只需要一個指數較小的網路,真/假?(A)
A.正確
B.錯誤
決議: 深層的網路隱藏單元數量相對較少,隱藏層數目較多,如果淺層的網路想要達到同樣的計算結果則需要指數級增長的單元數量才能達到,
7、前面的問題使用了一個特定的網路,一般情況下, 與層l有關的權重矩陣W[l]的維數是多少?(A)
A.W[l]的維度是 (n[l], n[l?1])
B.W[l]的維度是 (n[l-1], n[l])
C.W[l]的維度是 (n[l+1], n[l])
D.W[l]的維度是 (n[l], n[l+1])
決議: 一般來說W[l]的形狀是(n[l],n[l-1]),b[l]的形狀是(n[l],1)
北航2019機器學習考試題(部分)
-
貝葉斯決策,基于最小風險和最小方差的決策
-
svm的基本思想,模型運算式,軟間隔和硬間隔的物理含義,如何用來解決非線性問題
-
什么是過擬合,解決方法有哪一些
過擬合指模型過于復雜,在訓練集上表現好而在測驗集上表現不好,
解決方法:
簡化模型結構(減小深度/降低寬度);
dropout(深度學習常用)
引數正則化:降低復雜度,提升穩定度
data augmentation:以CV為例,在訓練集中裁剪旋轉、添加噪點,
early stopping:在每個epoch中,當accuracy不變時停止訓練, -
pca演算法基于最小均方誤差的思想,
-
給出一個4X4X4X3的全連接神經網路,推導反向傳播演算法,以第二層的第三個節點為例
-
給出機器學習和深度學習的聯系,各有什么優缺點,你認為未來深度學習會如何發展,
北航2019機器學習考試題https://www.csdn.net/gather_2d/MtjaYg5sMDcyODMtYmxvZwO0O0OO0O0O.html
深度學習測驗題
詳細決議
一、單選題
- 神經網路的“損失函式”(Loss fuction)衡量的是(A)
A.預測值與真實值之間的差距
B.訓練集與測驗集之間的差距
C.dropout損失的資訊量
D.pooling損失的資訊量
- 函式f(x)=1/(1+e^(-x))的導數在x>∞的極限是(B)
A.1 B.0 C.0.5 D.∞
決議 :sigmoid函式極限的是在(0,1),這里問的是它的導數S’(x)=S(x)(1-S(x)),所以應該是0,
- 在反向傳播的程序中,首先被計算的變數(C)的梯度,之后將其反向傳播,
A.連接權重 B.損失函式 C.激活函式 D.特征映射
-
卷積神經網路VGG16名稱中16指的是(C)
A.論文發表于2016年
B.網路總共有16層
C.網路有16層的引數需要訓練
D.VGG發表的第16代網路
決議 :VGG16共包含:
13個卷積層(Convolutional Layer),分別用conv3-XXX表示
3個全連接層(Fully connected Layer),分別用FC-XXXX表示
5個池化層(Pool layer),分別用maxpool表示
其中,卷積層和全連接層具有權重系數,因此也被稱為權重層,總數目為13+3=16,這即是
VGG16中16的來源,(池化層不涉及權重,因此不屬于權重層,不被計數),
所以這里的16層指的是需要參與訓練的層數,
- 在神經網路中,“梯度消失”問題的主要來源是(D)
A.被Dropout丟棄
B.被Pooling丟棄
C.梯度為負數
D.梯度趨近于零
-
下列哪一項在神經網路中引入了非線性 B
A. 隨機梯度下降
B. 修正線性單元(ReLU)
C. 卷積函式
D. 以上都不對 -
以下哪種不是自適應學習率方法 A
A. Mini-batch SGD
B. Adagrad
C. RMSprop -
如果使用的學習率太大,會導致 C
A. 網路收斂的快
B. 網路收斂的快
C. 網路無法收斂
D. 不確定 -
下列目標檢測網路中,哪個是一階段的網路 C
A. Faster-rcnn
B. RFCN
C. YOLOV3
D. SPP-net -
假定在神經網路中的隱藏層中使用激活函式X,在特定神經元給定任意輸入,會得到輸出[-0.0001],X可能是以下哪一個激活函式 B
A. ReLU
B. tanh
C. Sigmoid
D. 以上都不是
決議:該激活函式可能是 tanh,因為該函式的取值范圍是 (-1,1),
- 如果增加神經網路的寬度,精確度會增加到一個閾值,然后開始降低,造成這一現象的原因可能是 C
A. 只有一部分核被用于預測
B. 當核數量增加,神經網路的預測能力降低
C. 當核數量增加,其相關性增加,導致過擬合
D. 以上都不對
二、多選題
- 神經網路中引數極多,常用的初始化方法有哪些?(ABD)
A.全零初始化 B.隨機初始化 C.加載預訓練模型 D.使用深度信念網路
決議 :深度信念網路(DBN)通過采用逐層訓練的方式,解決了深層次神經網路的優化問題,通過逐層訓練為整個網路賦予了較好的初始權值,使得網路只要經過微調就可以達到最優解,
- 人工智能網路的常用激活函式有(ABD)
A.sigmond B.tanh C.sinh D.relu E.cos
-
以關于梯度下降法敘述正確的有?(BD)
A. 精度下降方法迭代時將沿著梯度方向進行更新
B.梯度下降方法迭代時將沿著負梯度方向進行更新
C.梯度方向是使得函式值下降最快的方向
D.梯度方向是使得函式值上升降最快的方向
決議 :梯度是一個向量,目標函式在具體某點沿著梯度的相反方向下降最快,一個形象的比喻是想象你下山的時候,只能走一步下山最快的方向即是梯度的相反方向,每走一步就相當于梯度下降法的一次迭代更新,
- 常用的池化層有哪些?(AB)
A.MaxPooling B.AveragePooling C.MinPooling D.MedianPooling
- 相對于普通的神經網路,回圈神經網路(RNN)的“回圈”主要體現在(ABC)
A.訓練程序中的反向傳播次數更多
B.訓練經過一定輪次之后將引數歸零
C.深層節點的輸出會反過來影響淺層節點
D.每個節點自回圈
-
當影像分類的準確率不高時,可以考慮以下哪種方法提高準確率 (ABC)
A. 資料增強
B. 調整超引數
C. 使用預訓練網路引數
D. 減少資料集 -
下列哪個神經網路結構會發生權重共享 AB
A. 卷積神經網路
B. 回圈神經網路
C. 全連接神經網路 -
關于梯度下降演算法,以下說法正確的是 ABC
A. 隨機梯度下降演算法是每次考慮單個樣本進行權重更新
B. Mini-Batch梯度下降演算法是批量梯度下降和隨機梯度下降的折中
C. 批量梯度下降演算法是每次考慮整個訓練集進行權重更新 -
當影像分類的準確率不高時,可以考慮以下哪種方法提高準確率
A. 資料增強
B. 調整超引數
C. 使用預訓練網路引數
D. 減少資料集
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/201013.html
標籤:其他