目錄
一、背景
二、實戰決議
三、總結
一、背景
最近,在開發中遇到個功能需求,系統有個資訊查詢模塊,要求資訊按照卡片形式展示,如下圖:
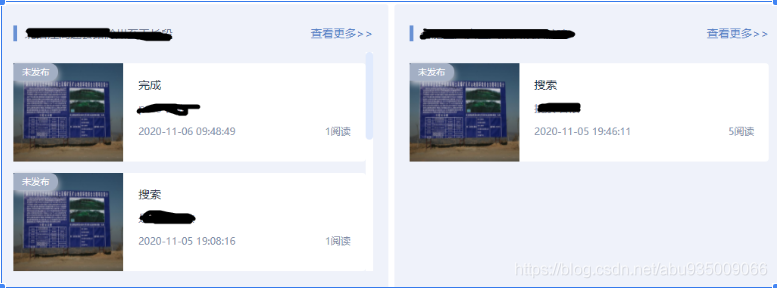
按照專案組展示卡片,每個專案組展示閱讀量最多的TOP2,
需求決議:按照專案組分組,然后取每組閱讀量最多的前2條,
二、實戰決議
基于Mysql資料庫
表定義
1、專案組:team
| id | 主鍵 |
| name | 專案組名稱 |
2、資訊表:info
| id | 主鍵 |
| team_id | 專案組id |
| title | 資訊名稱 |
| pageviews | 瀏覽量 |
| content | 資訊內容 |
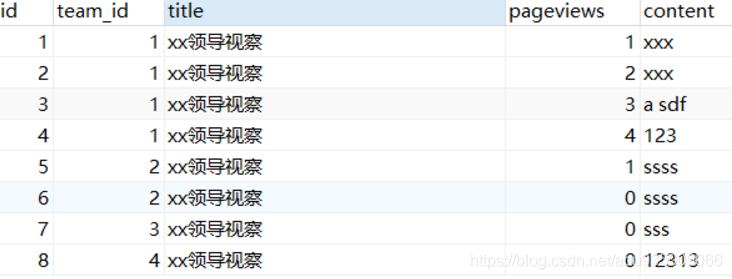
info表資料如下圖:
我們先預習下Select基礎知識
書寫順序:
select *columns*
from *tables*
where *predicae1*
group by *columns*
having *predicae1*
order by *columns*
limit *start*, *offset*;執行順序:
from *tables*
where *predicae1*
group by *columns*
having *predicae1*
select *columns*
order by *columns*
limit *start*, *offset*;
count(欄位名) # 回傳表中該欄位總共有多少條記錄
DISTINCT 欄位名 # 過濾欄位中的重復記錄
第一步:先找出資訊表中閱讀量的前二名
info資訊表自關聯
SELECT a.*
FROM info a
WHERE (
SELECT count(DISTINCT b.pageviews)
FROM info b
WHERE a.pageviews < b.pageviews AND a.team_id= b.team_id
) < 2 ;乍一看不好理解,下面舉例說明
舉個例子:
當閱讀量pageviews a = b = [1,2,3,4]
a.pageviews = 1,b.pageviews 可以取值 [2,3,4],count(DISTINCT b.pageviews) = 3
a.pageviews = 2,b.pageviews 可以取值 [3,4],count(DISTINCT b.pageviews) = 2 # 有2條,即第三名
a.pageviews = 3,b.pageviews 可以取值 [4],count(DISTINCT b.pageviews) = 1 # 有1條,即第二名
a.pageviews = 4,b.pageviews 可以取值 [],count(DISTINCT b.pageviews) = 0 # 有0條,即最大 第一名count(DISTINCT b.pageviews) 代表有幾個比這條值大
a.team_id= b.team_id 自關聯條件,約等于分組
所以前二名 等價于 count(DISTINCT e2.Salary) < 2 ,所以 a.pageviews 可取值為 3、4,即集合前 2 高
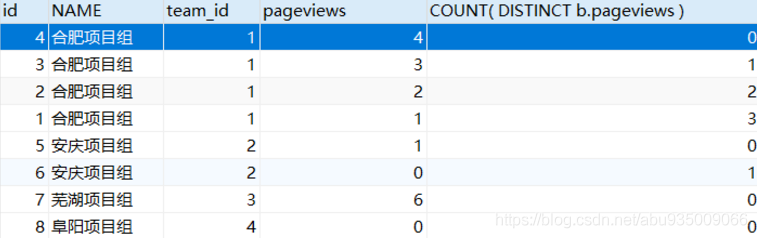
第二步:再把表 team和表 info連接
SELECT a.id, t.NAME, a.team_id, a.pageviews
FROM info a
LEFT JOIN team t ON a.team_id = t.id
WHERE (
SELECT count(DISTINCT b.pageviews)
FROM info b
WHERE a.pageviews < b.pageviews AND a.team_id= b.team_id) < 2
ORDER BY a.team_id, a.pageviews desc結果如下圖:
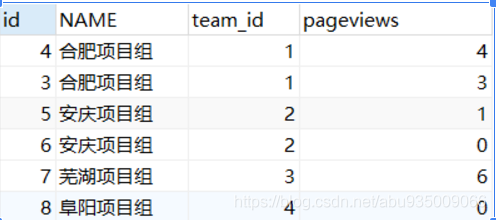
還有一種好理解的方式:
分組GROUP BY + HAVING,這種方式可以一步一步方便除錯結果
SELECT a.id, t.NAME, a.team_id, a.pageviews, COUNT( DISTINCT b.pageviews )
FROM info a
LEFT JOIN info b ON ( a.pageviews < b.pageviews AND a.team_id = b.team_id )
LEFT JOIN team t ON a.team_id = t.id
GROUP BY a.id, t.NAME, a.team_id, a.pageviews
HAVING COUNT( DISTINCT b.pageviews ) < 2
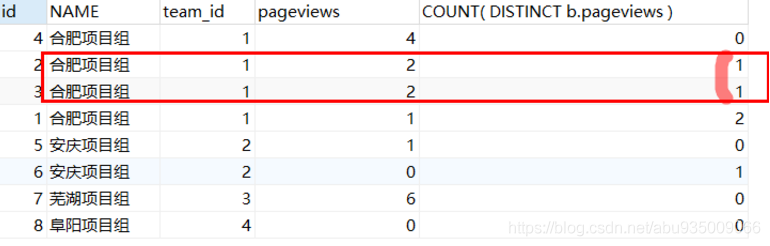
ORDER BY a.team_id, a.pageviews DESC問題:如果出現閱讀數相同的情況,就裂開了,
舉例說明:
當閱讀量pageviews a = b = [1,2,2,4]
a.pageviews = 1,b.pageviews 可以取值 [2,2,4],count(DISTINCT b.pageviews) = 3
a.pageviews = 2,b.pageviews 可以取值 [4],count(DISTINCT b.pageviews) = 1 # 有1條,即并列第二名
a.pageviews = 2,b.pageviews 可以取值 [4],count(DISTINCT b.pageviews) = 1 # 有1條,即第二名
a.pageviews = 4,b.pageviews 可以取值 [],count(DISTINCT b.pageviews) = 0 # 有0條,即最大 第一名count(DISTINCT e2.Salary) < 2 ,所以 a.pageviews 可取值為 2、2、4,即集合前 2 高,但是有三條資料
三、總結
需求轉化:將分組求前幾條,改為了自關聯后,有幾條資料比這條大
其實這個是類似LeetCode上難度為hard的一道資料庫題目
185. 部門工資前三高的所有員工
參考:
https://leetcode-cn.com/problems/department-top-three-salaries/solution/185-bu-men-gong-zi-qian-san-gao-de-yuan-gong-by-li/
關注我的公眾號【Java大廠面試官】,回復:架構、資源等關鍵詞(更多關鍵詞,關注后注意提示資訊)獲取更多免費資料,
公眾號會發布在作業中遇到的問題和解決方案,分享自己的讀書筆記和面試總結,成為一個架構師的辛酸之路,以及去大廠的面試資料和面經,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/208452.html
標籤:其他