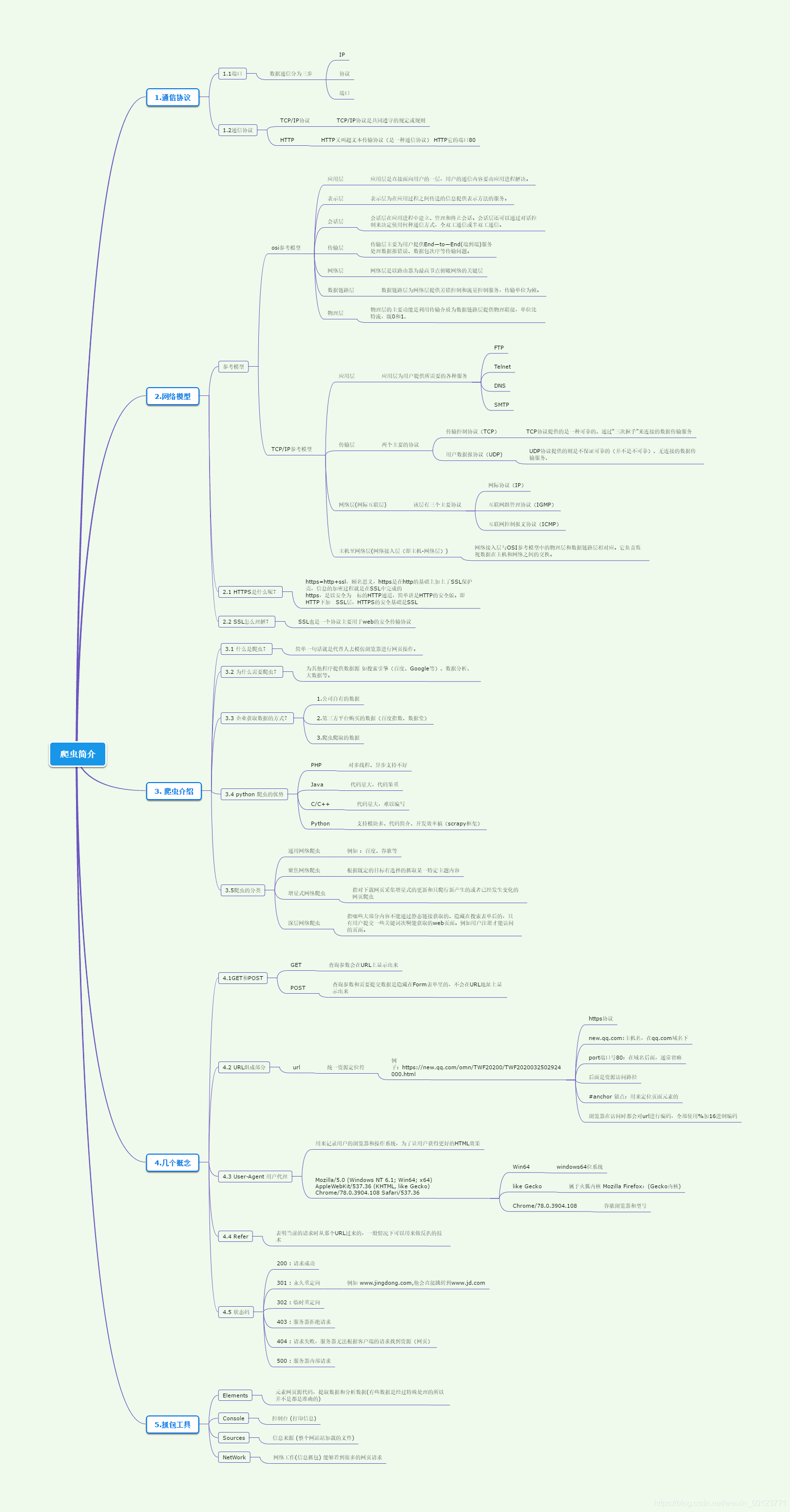
第一章 爬蟲介紹
1.通信協議
1.1埠
資料通信分為三步
IP
協議
埠
1.2通信協議
TCP/IP協議
TCP/IP協議是共同遵守的規定或規則
HTTP
HTTP又叫超文本傳輸協議(是一種通信協議) HTTP它的埠80
2.網路模型
參考模型
osi參考模型
應用層
應用層是直接面向用戶的一層,用戶的通信內容要由應用行程解決,
表示層
表示層為在應用程序之間傳送的資訊提供表示方法的服務,
會話層
會話層在應用行程中建立、管理和終止會話,會話層還可以通過對話控制來決定使用何種通信方式,全雙工通信或半雙工通信,
傳輸層
傳輸層主要為用戶提供End—to—End(端到端)服務處理資料報錯誤、資料包次序等傳輸問題,
網路層
網路層是以路由器為最高節點俯瞰網路的關鍵層
資料鏈路層
資料鏈路層為網路層提供差錯控制和流量控制服務,傳輸單位為幀,
物理層
物理層的主要功能是利用傳輸介質為資料鏈路層提供物理聯接,單位位元流,既0和1.
TCP/IP參考模型
應用層
應用層為用戶提供所需要的各種服務
FTP
Telnet
DNS
SMTP
傳輸層
兩個主要的協議
傳輸控制協議(TCP)
TCP協議提供的是一種可靠的、通過“三次握手”來連接的資料傳輸服務
用戶資料報協議(UDP)
UDP協議提供的則是不保證可靠的(并不是不可靠)、無連接的資料傳輸服務.
網路層(網際互聯層)
該層有三個主要協議
網際協議(IP)
互聯網組管理協議(IGMP)
互聯網控制報文協議(ICMP)
主機至網路層(網路接入層(即主機-網路層))
網路接入層與OSI參考模型中的物理層和資料鏈路層相對應,它負責監視資料在主機和網路之間的交換,
2.1 HTTPS是什么呢?
https=http+ssl,顧名思義,https是在http的基礎上加上了SSL保護殼,資訊的加密程序就是在SSL中完成的,https,是以安全為?標的HTTP通道,簡單講是HTTP的安全版,即HTTP下加?SSL層,HTTPS的安全基礎是SSL
2.2 SSL怎么理解?
SSL也是一個協議主要用于web的安全傳輸協議
3. 爬蟲介紹
3.1 什么是爬蟲?
簡單一句話就是代替人去模仿瀏覽器進行網頁操作,
3.2 為什么需要爬蟲?
為其他程式提供資料源 如搜索引擎(百度、Google等)、資料分析、大資料等,
3.3 企業獲取資料的方式?
1.公司自有的資料
2.第三方平臺購買的資料(百度指數、資料堂)
3.爬蟲爬取的資料
3.4 python 爬蟲的優勢
PHP
對多執行緒、異步支持不好
Java
代碼量大,代碼笨重
C/C++
代碼量大,難以撰寫
Python
支持模塊多、代碼簡介、開發效率搞(scrapy框架)
3.5爬蟲的分類
通用網路爬蟲
例如 :百度、谷歌等
聚焦網路爬蟲
根據既定的目標有選擇的抓取某一特定主題內容
增量式網路爬蟲
指對下載網頁采集增量式的更新和只爬行新產生的或者已經發生變化的網頁爬蟲
深層網路爬蟲
指哪些大部分內容不能通過靜態鏈接獲取的、隱藏在搜索表單后的,只有用戶提交一些關鍵詞次啊能獲取的web頁面,例如用戶注冊才能訪問的頁面,
4.幾個概念
4.1GET和POST
GET
查詢引數會在URL上顯示出來
POST
查詢引數和需要提交資料是隱藏在Form表單里的,不會在URL地址上顯示出來
4.2 URL組成部分
url
統一資源定位符
例子:https://new.qq.com/omn/TWF20200/TWF2020032502924000.html
https協議
new.qq.com:主機名,在qq.com域名下
port埠號80:在域名后面,通常省略
后面是資源訪問路徑
#anchor 錨點:用來定位頁面元素的
瀏覽器在訪問時都會對url進行編碼,全部使用%加16進制編碼
4.3 User-Agent 用戶代理
用來記錄用戶的瀏覽器和作業系統,為了讓用戶獲得更好的HTML效果
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
Win64
windows64位系統
like Gecko
屬于火狐內核 Mozilla Firefox:(Gecko內核)
Chrome/78.0.3904.108
谷歌瀏覽器和型號
4.4 Refer
表明當前的請求時從那個URL過來的,一般情況下可以用來做反扒的技術
4.5 狀態碼
200 : 請求成功
301 : 永久重定向
例如 www.jingdong.com,他會直接跳轉到www.jd.com
302 : 臨時重定向
403 : 服務器拒絕請求
404 : 請求失敗,服務器無法根據客戶端的請求找到資源(網頁)
500 : 服務器內部請求
5.抓包工具
Elements
元素網頁源代碼,提取資料和分析資料(有些資料是經過特殊處理的所以并不是都是準確的)
Console
控制臺 (列印資訊)
Sources
資訊來源 (整個網站站加載的檔案)
NetWork
網路作業(資訊抓包) 能夠看到很多的網頁請求
歡迎加入python資料分析、爬蟲學習討論群,一起自學一起進步,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/209122.html
標籤:其他
上一篇:MySQL資料庫學習2