在游戲中,當我們需要讓角色移動到指定位置時,只需要滑鼠輕輕的一點就可以完成這簡單的步驟,系統會立即尋找離角色最近的一條路線

可是,這背后的行為邏輯又有什么奧秘呢? 你會怎么寫這個尋路演算法呢?
一般我們遇到這種路徑搜索問題,大家首先可以想到的是廣度優先搜索演算法(Breadth First Search)、還有深度優先(Depth First Search)、弗洛伊德(Floyd)、迪杰斯特拉(Dij)等等這些非常著名的路徑搜索演算法,但是在絕大多數情況下這些演算法面臨的缺點就暴露了出來:時間復雜度比較高,
所以,大部分環境里我們用到的是一個名叫A* (A star)的搜索演算法
(點擊圖片瀏覽動圖)
說到最短路徑呢,我們就不得不提到廣度優先遍歷(BFS),它是一個萬能演算法,它不單單可以用在 尋路或者搜索的問題上,windows的系統工具:畫板 中的油漆桶就是其比較典型一個的例子

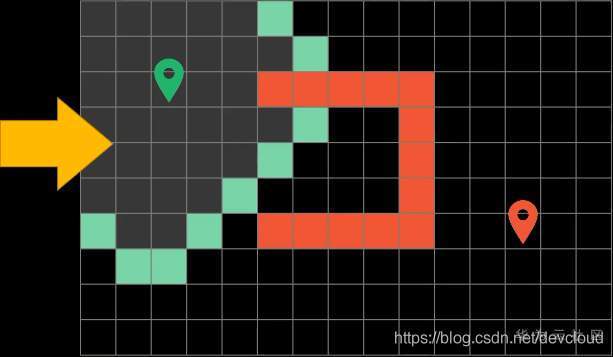
這里對路徑搜索做一個比較簡潔的示例

假設我們是在一個網格上面進行最短路徑的搜索

我們只能上下左右移動,不可以穿越障礙物,演算法的目的是為了能讓你尋找到一條從起點到站點的最短路徑
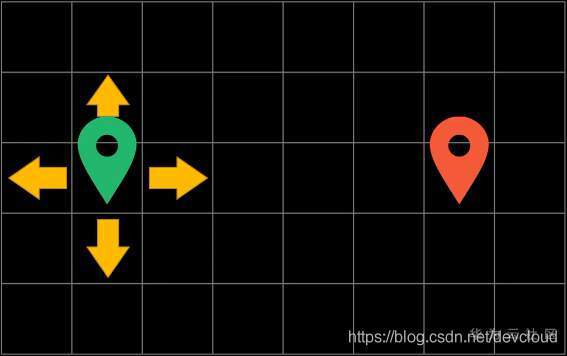
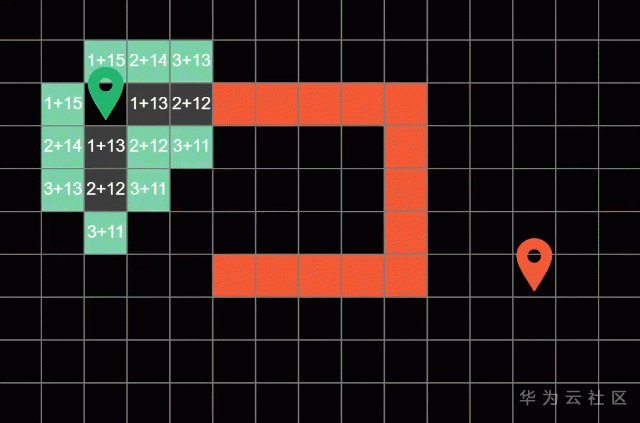
假設每次都可以上下左右朝4個方向進行移動

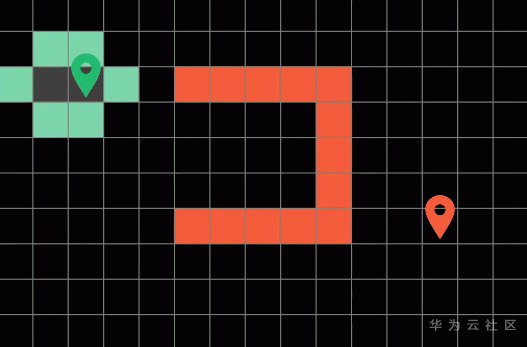
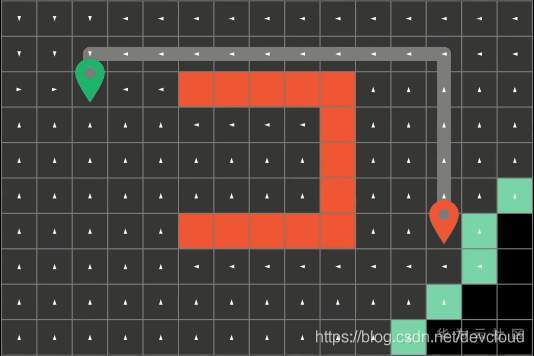
演算法在每一輪遍歷后會標記這一輪探索過的方塊稱為邊界(Frontier),就是這些綠色的方塊,
(點擊圖片瀏覽動圖)

然后演算法呢會回圈往復的從這些邊界方塊開始,朝他們上下左右四個方向進行探索,直到演算法遍歷到了終點方塊才會停止,而最短路徑呢就是演算法之前一次探索過的路徑,為了得到演算法探索過的整條路徑呢,我們可以在搜索的程序中順勢記錄下路徑的來向,

比如這里方塊上的白色箭頭就代表了之前方塊的位置
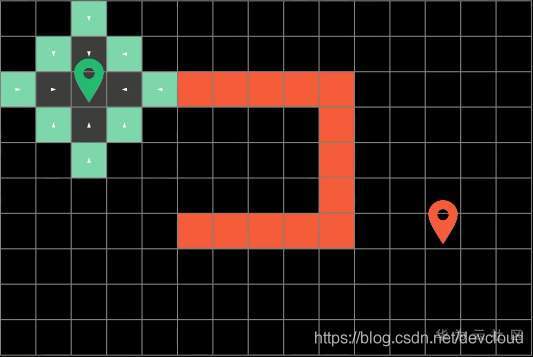
在每一次探索路徑的時候,我們要做的也只是額外的記錄下這個資訊
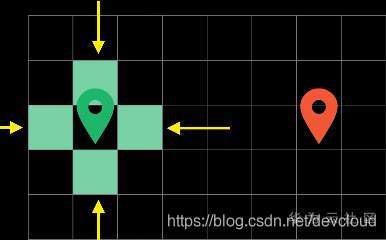
要注意,所有探索過的路徑我們需要將它們標記成灰色,代表它們“已經被訪問過“,這樣子演算法就不會重復探索已經走過的路徑了,
廣度優先演算法顯然可以幫助我們找到最短路徑,不過呢它有點傻,因為它對路徑的尋找是沒有方向性的,它會向各個方向探測過去,

最壞的情況可能是找到終點需要遍歷整個地圖,因此很不智能,我們需要一個更加高效的演算法,
就是本次我們要介紹的A * (A star)搜索演算法
A* Search Algorithm
”A*搜索演算法“也被叫做“啟發式搜索”
與廣度優先不同的是,我們在每一輪回圈的時候不會去探索所有的邊界方塊(Frontier),而會去選擇當前“代價(cost)”最低的方塊進行探索,
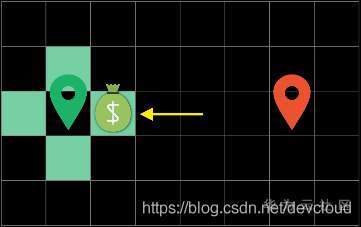
這里的“代價”就很有意思了,也是A*演算法智能的地方,

我們可以把這里的代價分成兩部分,一部分是“當前路程代價(可表示成f-cost)”:比如你從起點出發一共走過多少個格子,f-cost就是幾
另一部分是“預估代價(可表示成g-cost)”:用來表示從當前方塊到再終點方塊大概需要多少步,預估預估所以它不是一個精確的數值,也不代表從當前位置出發就一定會走那么遠的距離,不過我們會用這個估計值來指導演算法去優先搜索更有希望的路徑,
最常用到的“預估代價”有歐拉距離(Euler Distance)“,就是兩點之間的直線距離(x1 - x2)^2 + (y1 - y2)^2
當然還有更容易計算的“曼哈頓距離(Manhattan Distance)”,就是兩點在豎直方向和水平方向上的距離總和|x1 - x2|+|y1 - y 2|
曼哈頓距離不用開方,速度快,所以在A* 演算法中我們可以用它來充當g-cost
接下來,我們只要把之前講到的這兩個代價相加就得出了總代價:f-cost + g-cost
然后在探索方塊中,優先挑選總代價最低的方塊進行探索,這樣子就會少走很多彎路
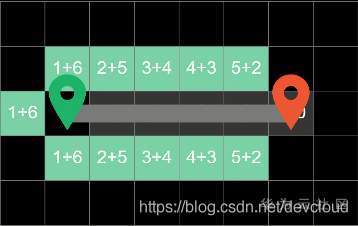
而且搜索到的路徑也一定是最短路徑,
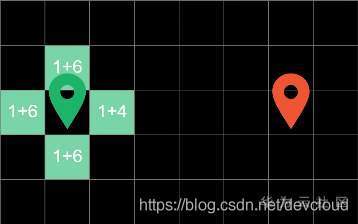
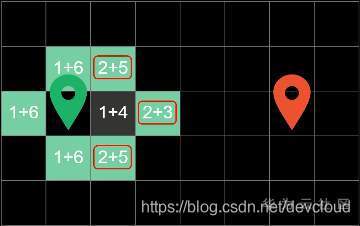
在第一輪回圈中,演算法對起點周圍的四個方塊進行探索,并計算出“當前代價”和“預估代價”,
比如這里的1代表從起步到當前方塊走了1步
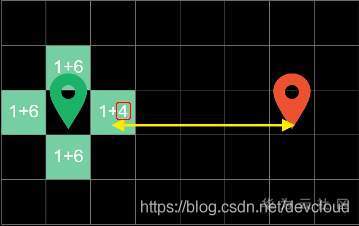
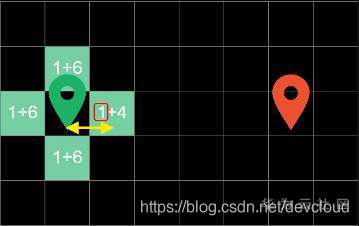
這里的4代表著方塊到終點的曼哈頓距離,在這四個邊界方塊中,右邊方塊代價最低,因此在下一輪回圈中會優先對它進行搜尋
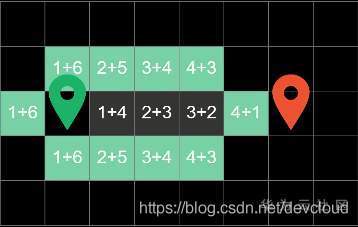
在下一輪回圈中,我們已同樣的方式計算出方塊的代價,發現最右邊的方塊價值依然最低,因此在下一輪的回圈中,我們對它進行搜尋
演算法就這樣子回圈往復下去,直到搜尋到終點為止
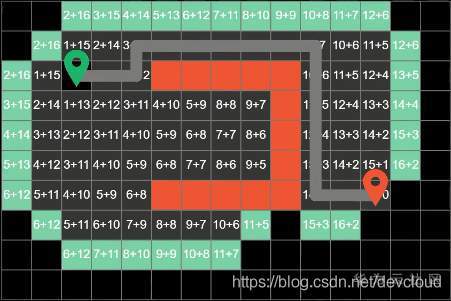
增加一下方塊的數量級,A*演算法同樣可以找到正確的最短路徑
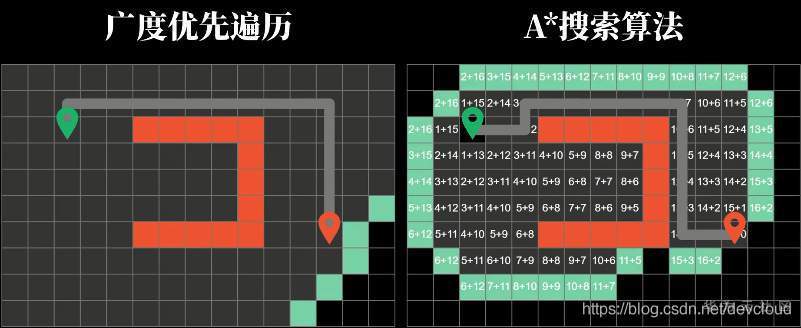
最為關鍵的是,它搜尋的方塊個數明顯比廣度優先遍歷少很多,因此也就更高效,
理解了演算法的基本原理后,接下來就是上代碼了,這里我直接參考redblobgames的Python代碼實作,因為人家實在寫的太好了!
def heuristic(a, b): #Manhattan Distance
(x1, y1) = a
(x2, y2) = b
return abs(x1 - x2) + abs(y1 - y2)
def a_star_search(graph, start, goal):
frontier = PriorityQueue()
frontier.put(start, 0)
came_from = {}
cost_so_far = {}
came_from[start] = None
cost_so_far[start] = 0
while not frontier.empty():
current = frontier.get()
if current = goal:
break
for next in graph.neighbors(current):
new_cost = cost_so_far[current] + graph.cost(current, next)
if next not in cost_so_far or new_cost < cost_so_far[next]:
cost_so_far[next] = new_cost
priority = new_cost + heuristic(goal, next)
frontier.put(next, priority)
came_from[next] = current
return came_from, cost_so_far
先來看看最上面幾行,frontier中存放了我們這一輪探測過的所有邊界方塊(之前圖中那些綠色的方塊)
frontier = PriorityQueue()PriorityQueue代表它是一個優先佇列,就是說它能夠用“代價”自動排序,并每次取出”代價“最低的方塊
frontier.put(start, 0)佇列里面呢我們先存放一個元素,就是我們的起點
came_from = {}接下來的的 came_from 是一個從當前方塊到之前的映射,代表路徑的來向
cost_so_far = {}這里的 cost_so_far 代表了方塊的“當前代價”
came_from[start] = None
cost_so_far[start] = 0這兩行將起點的 came_from 置空,并將起點的當前代價設定成0,這樣子就可以保證演算法資料的有效性
while not frontier.empty():
current = frontier.get()接下來,只要 frontier 這個佇列不為空,回圈就會一直執行下去,每一次回圈,演算法從優先佇列里抽出代價最低的方塊
if current = goal:
break然后檢測這個方塊是不是終點塊,如果是演算法結束,否則繼續執行下去
for next in graph.neighbors(current):接下來,演算法會對這個方塊上下左右的相鄰塊,也就是回圈中 next 表示的方塊進行如下操作
new_cost = cost_so_far[current] + graph.cost(current, next)演算法會先去計算這個 next 方塊的“新代價”,它等于之前代價 加上從 current 到 next 塊的代價
由于我們用的是網格,所以后半部分是 1
if next not in cost_so_far or new_cost < cost_so_far[next]:然后只要 next 塊沒有被檢測過,或者 next 當前代價比之前的要低
frontier.put(next, priority)我們就直接把他加入到優先佇列,并且這里的總代價priority等于“當前代價”加上“預估代價”
priority = new_cost + heuristic(goal, next)預估代價就是之前講到的“曼哈頓距離”
def heuristic(a, b): (x1, y1) = a (x2, y2) = b return abs(x1 - x2) + abs(y1 - y2)之后程式就會進入下一次回圈,重復執行之前的所有步驟
這段程式真的是寫的特別巧妙,可能比較難以理解可是多看幾遍說不定你就突然靈光乍現了呢
拓展
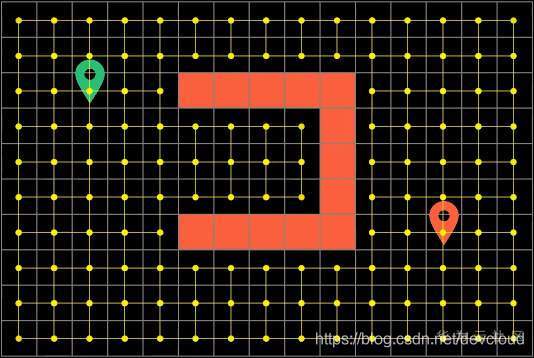
如果把地圖拓展成網格形式(Grid),因為圖的節點太多,遍歷起來會非常的低效
于是我們可以吧網格地圖簡化成 節點更少的路標形式(WayPoints)
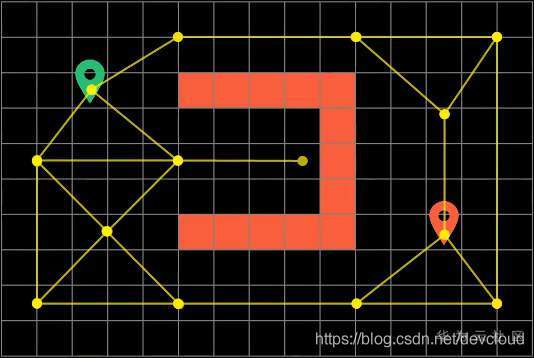
然后需要注意的是:這里任意兩個節點之間的距離就不再是1了,而是節點之間的實際距離
我們還可以用自上而向下分層的方式來存盤地圖
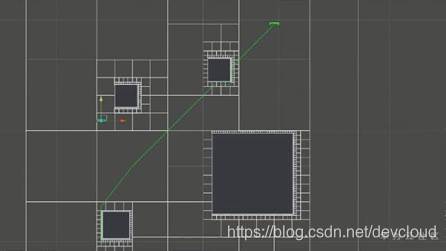
比如這個四叉樹(Quad Tree)
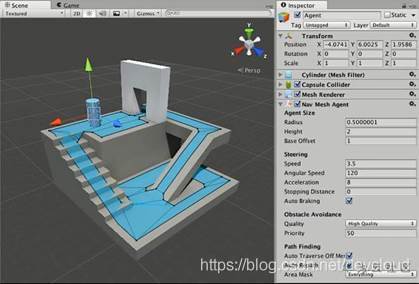
又或者像unity中使用的導航三角網(Navigation Mesh),這樣子演算法的速度就會得到進一步優化
另外,我還推薦redblobgames的教程
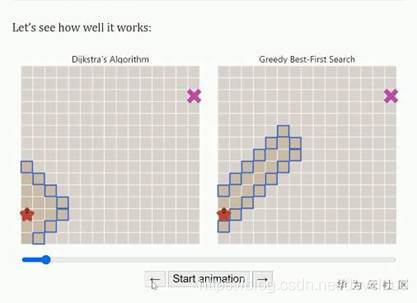
各種演算法的可視化,以及清楚的看見各種演算法的遍歷程序、中間結果
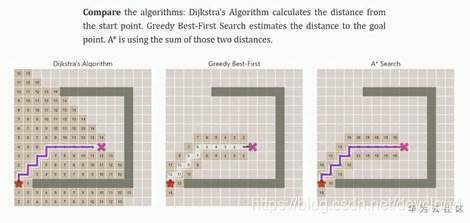
以及各種方法之間的比較,非常的直觀形象,對于演算法的理解也很有幫助,
參考:
[1]周小鏡. 基于改進A演算法的游戲地圖尋徑的研究[D].西南大學,2010. [2]https://www.redblobgames.com/pathfinding/a-star/introduction.html [3]https://en.wikipedia.org/wiki/A_search_algorithm
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/209407.html
標籤:其他
上一篇:MATLAB 版大富翁
下一篇:生命游戲