標題無意冒犯,就是覺得這個廣告挺好玩的
上面這張思維導圖喜歡就拿走,反正我也學不了這么多
文章目錄
- 前言
- 歡迎來到我們的圈子
- 繞過登錄驗證的小餅干:cookies and session
- 宣告
- 什么是cookies?什么是session?
- 是如何實作“記住我的登錄狀態”的功能
- post請求
- 實操第一步
- 鋒回路轉
- 把小餅干裝進餅干盒
- 自動化實作:selenium
- 先展示一下
- 代碼展示
- 環境配置
- selenium簡單講解
- 設定瀏覽器引擎
- selenium能干嘛?
- 為什么selenium這么能干?
前言
前期回顧:我要偷偷學Python(第十天)
上一篇呢,上一篇不是很好,我自己有數,身體抱恙,所以,這一篇我準備了不少有意思的東西(壞笑),嘿嘿,快來跟我動手操作,
我行,你也行!!!

插播一條推送:(如果是小白的話,可以看一下下面這一段)
歡迎來到我們的圈子
我建了一個Python學習答疑群,有興趣的朋友可以了解一下:這是個什么群
群里已經有七百多個小伙伴了哦!!!
直通群的傳送門:傳送門
本系列文默認各位有一定的C或C++基礎,因為我是學了點C++的皮毛之后入手的Python,這里也要感謝齊鋒學長送來的支持,
本系列文默認各位會百度,學習‘模塊’這個模塊的話,還是建議大家有自己的編輯器和編譯器的,上一篇已經給大家做了推薦啦?
我要的不多,點個關注就好啦
然后呢,本系列的目錄嘛,說實話我個人比較傾向于那兩本 Primer Plus,所以就跟著它們的目錄結構吧,
本系列也會著重培養各位的自主動手能力,畢竟我不可能把所有知識點都給你講到,所以自己解決需求的能力就尤為重要,所以我在文中埋得坑請不要把它們看成坑,那是我留給你們的鍛煉機會,請各顯神通,自行解決,
繞過登錄驗證的小餅干:cookies and session
宣告
看到這個標題,激動不?難道,今天咱也能去盜號了嗎?嘿嘿,準備好黑頭套,干他丫的,
喂喂喂,醒醒,醒醒,哈喇子都流出來了,咱可是遵紀守法好公民,怎么去干這種事情?
我只會教你,怎么在人家點擊了“記住賬號密碼”的情況下,你給它繞過登錄驗證,至于你要怎么拿到這個條件,那跟我沒關系啊,特此宣告哈哈哈,
看了我前兩天發的那篇“自己爬自己的照片”的博客的朋友不知道對這個流程是否還有印象,是否還有疑慮啊,這么麻煩的操作,處處體現著人的干預,機器怎么搞?你不登錄,你不保存,你不去找網址,怎么拿到cookies嘛,
能問出這種問題的小伙伴(真的有)啊,我只能說你腦子挺活絡的,但是不要跑偏了,上面你這幾個問題,都是有技術手段可以解決的,但是我們讓爬蟲能夠登錄自己的賬號,就干不了很多事情嗎?工具在你手上,
什么是cookies?什么是session?
cookie: 在網站中,http請求是無狀態的,也就是說,即使第一次和服務器連接后并且登錄成功后,第二次請求服務器依然不能知道當前請求是哪個用戶,cookie的出現就是為了解決這個問題:當瀏覽器訪問網站后,這些網站將一組資料存放在客戶端,當該用戶發送第二次請求的時候,就會自動的把上次請求存盤的cookie資料自動攜帶給服務器,服務器通過瀏覽器攜帶的資料就能識別當前用戶,
一般為網頁存在本地的一些資料,用來下次訪問時回傳驗證,常用于登陸驗證,記住狀態
session: Session是存放在服務器端的類似于HashTable的結構來存放用戶 資料,當瀏覽器第一次發送請求時,服務器自動生成了一個HashTable和一個Session ID用來唯一標識這個HashTable,并將其通過回應發送到瀏覽器,當瀏覽器第二次發送請求,會將前一次服務器回應中的Session ID放在請求中一并發送到服務器上,服務器從請求中提取出Session ID,并和保存的所有Session ID進行對比,找到這個用戶對應的HashTable,
類似于客戶機本地的cookie,session為服務器的’cookie’,可以實作一樣的功能,往往還可以一同互動驗證登陸,記住狀態
是如何實作“記住我的登錄狀態”的功能
所以我們可以知道,如果將Session ID通過Cookie發送到客戶端的時候設定其有效時間為1年,那么在今后的一年時間內,客戶端訪問我的網站的時候都回將這個Session ID值發送到服務器上,服務器根據這個Session ID從記憶體或者資料庫里面恢復存放Key-Value對的HashTable,
但是,服務器上的Session其實不會保存,過了一定的時間之后,服務器上的Session就會被銷毀,以減輕服務器的訪問壓力,當服務器上的資料被銷毀后,即使客戶端上存放了cookie也沒有辦法“記住我的登錄狀態”了,
所以,本文方法只是短期驗證cookie跳過登陸驗證訪問之用,本地的cookie失效時間主要和服務器上session設定的時間有關,
post請求
什么是post請求?如果你沒聽說過post請求,那么就想一下get請求吧,
其實,post和get都可以帶著引數請求,不過get請求的引數會在url上顯示出來,
但post請求的引數就不會直接顯示,而是隱藏起來,像賬號密碼這種私密的資訊,就應該用post的請求,
說到這里我想起來我帶的C++帶學群的那群人好像還沒把輸入控制函式的作業交上來,
通常,get請求會應用于獲取網頁資料,比如我們之前學的requests.get(),post請求則應用于向網頁提交資料,比如提交表單型別資料(像賬號密碼就是網頁表單的資料),
實操第一步
打開CSDN的登錄頁面,填上你的個人資訊:https://passport.csdn.net/login?code=public
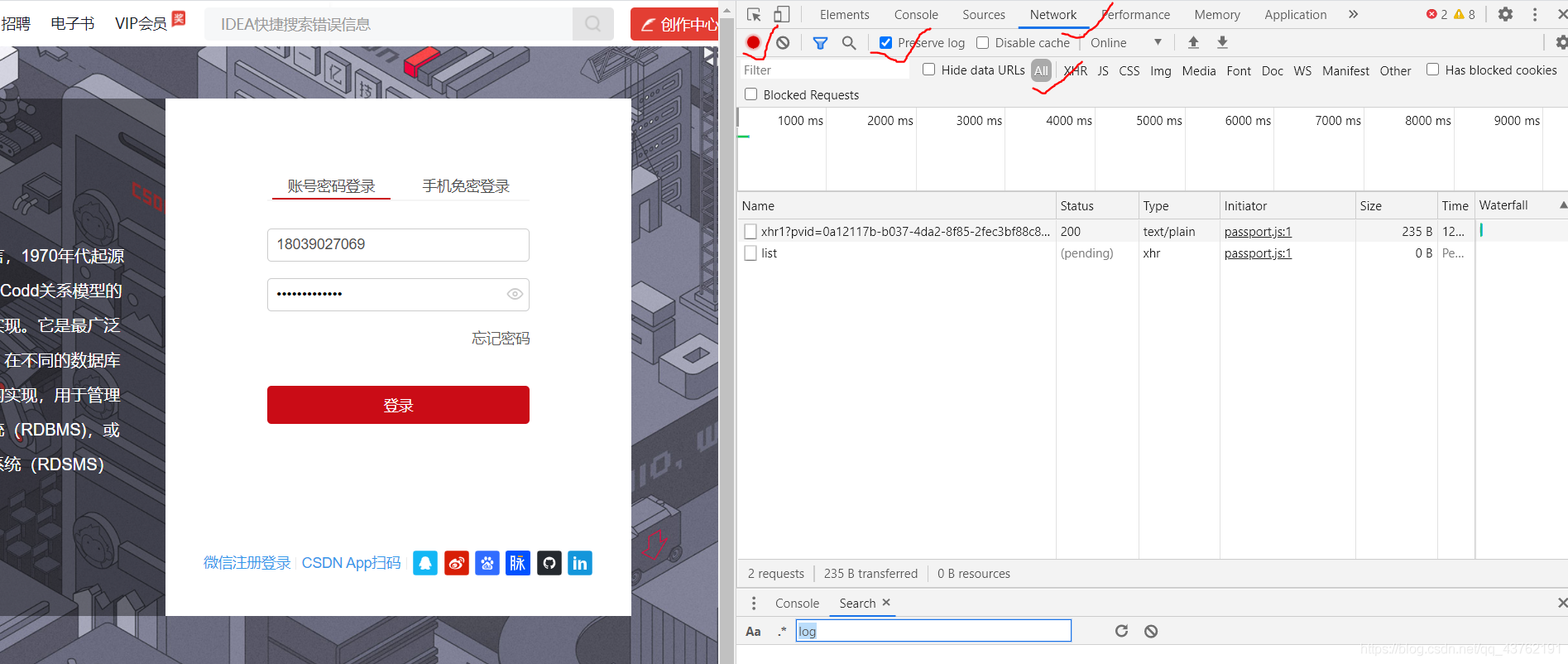
該勾的勾,該選的選,然后點擊登錄,
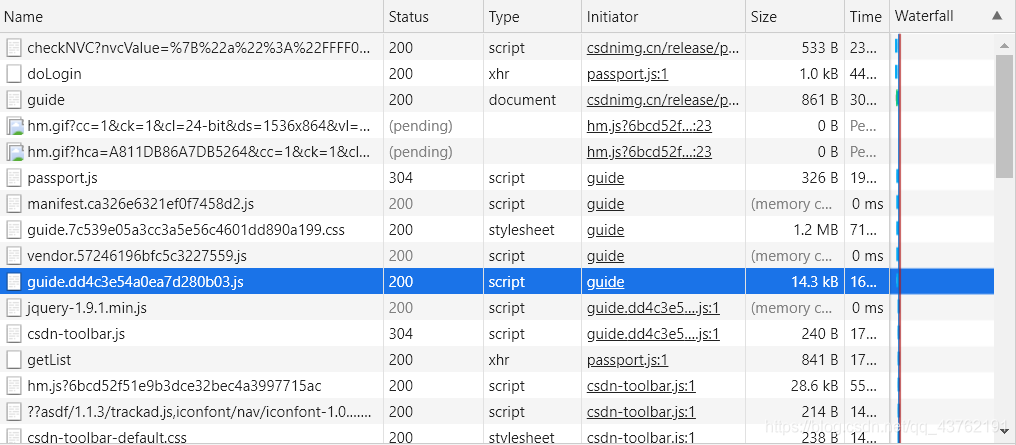
你猜是哪個包啊,耍點小聰明啊,你看你登錄成功之后,右邊還在不斷的加載包,那就可以判定登錄包肯定在前邊,
點擊登錄之后,信號一傳送,第一步肯定是登錄,所以就前幾個包看一下,一眼就看到了那個“doLogin”吧,點開,
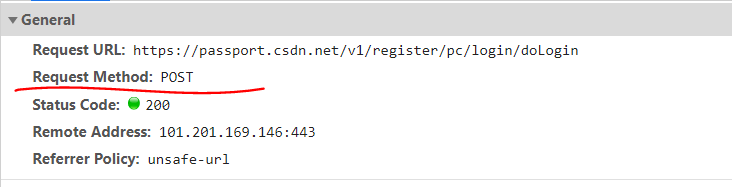
看到沒,post、
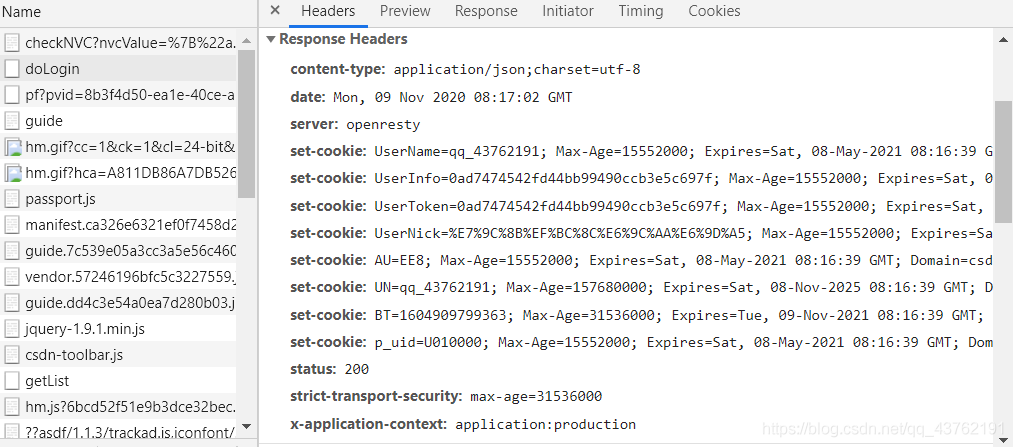
內啥,看到一大串的set-cookies了嗎?沒別的意思,我就提一下哈哈哈哈哈哈,
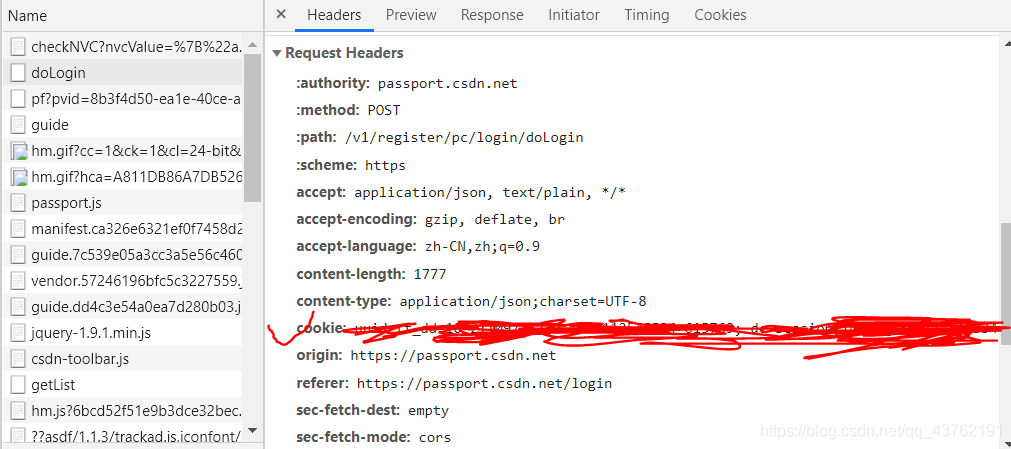
吶,我給你畫出來了,
上面我提那一下啊,其實我是想說,都打開,不同網站不一樣,指不定在哪個小角落里發現了你的小餅干呢,
其實不止小餅干啊,賬號密碼都有:
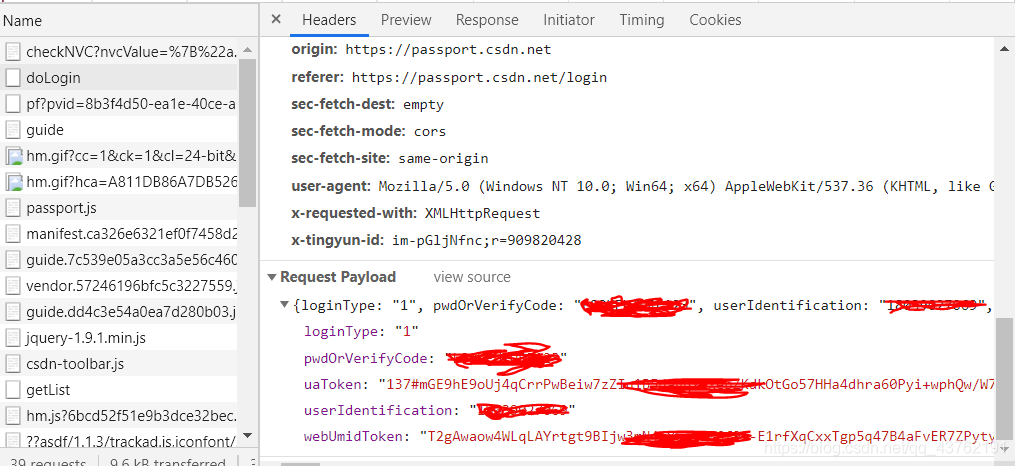
前邊那個自己爬自己的代碼我就不再寫了,這里直接把鏈接貼過來吧:Python練習時長兩周的練習生在CSDN抓到了自己的學生證認證照
我們來試試另一種登錄方式,帶參登錄,
import requests
#引入requests,
url = 'https://www.csdn.net/'
#把請求登錄的網址賦值給url,
headers = {
'origin':'https://passport.csdn.net',
# 請求來源,本案例中其實是不需要加這個引數的,只是為了演示
'referer':'https://passport.csdn.net/login',
'User-Agent':'省略'
}
#加請求頭,前面有說過加請求頭是為了模擬瀏覽器正常的訪問,避免被反爬蟲,
data = {
"loginType": "1",
"pwdOrVerifyCode": "密碼",
"userIdentification":"賬號"
}
#把有關登錄的引數封裝成字典,賦值給data,
login_in = requests.post(url,headers=headers,data=data)
print(login_in)
好的,回傳值403,草率了,,
沒事了,沒事了,
鋒回路轉
哦,我又不斷地嘗試了,終于成功的登錄上了:
import requests
from bs4 import BeautifulSoup
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36',
'Connection': 'keep-alive',
'accept': 'application/json, text/plain, */*',
#'Cookie': cookie,
'referer': “我的博客”頁面網址
}
url = 上面那個referer
data = {
"loginType": "1",
"pwdOrVerifyCode": 你的,
"userIdentification":你的
}
#把有關登錄的引數封裝成字典,賦值給data,
login_in = requests.post(url,headers=header,data=data)
print(login_in)
好極,這次回傳值是200了,
接下來干嘛?接下來找一篇博客評論一下這事兒就算過去了,
cookies = login_in.cookies
#提取cookies的方法:呼叫requests物件(login_in)的cookies屬性獲得登錄的cookies,并賦值給變數cookies,
url_1 = 自己找
#我們想要評論的文章網址,
data_1 = {
'content': 'test',
'articleId':個人填
}
#把有關評論的引數封裝成字典,
comment = requests.post(url_1,headers=header,data=data_1,cookies=cookies)
#用requests.post發起發表評論的請求,放入引數:文章網址、headers、評論引數、cookies引數,賦值給comment,
#呼叫cookies的方法就是在post請求中傳入cookies=cookies的引數,
print(comment.status_code)
#列印出comment的狀態碼,若狀態碼等于200,則證明我們評論成功,
CDSN評論重繪比較慢,所以就以狀態碼為準,有時候慢起來要等一天你才能看得到,
如果真等了一天還評論不上去,沒事,我跟你說,那應該是被后臺給切了,
沒事,我們后面還會有更好的辦法,
把小餅干裝進餅干盒
算了,為了看著直觀,我還是把之前那段爬學生證的代碼節選一下吧,
import requests
from bs4 import BeautifulSoup
cookie = '''*此處粘貼從chrome中復制的cookie資訊*'''
header = {
'User-Agent': '放你自己的',
'Connection': 'keep-alive',
'accept': '放你自己的',
'Cookie': cookie,
'referer': '放你自己的博客主頁地址'
}
url = 'https://me.csdn.net/api/user/show' # csdn 個人中心中,加載名字的js地址
seesion = requests.session()
response = seesion.get(url,headers=header)
print(type(session.cookies))
#列印cookies的型別,session.cookies就是登錄的cookies
好極,可以看到結果是:<class ‘requests.cookies.RequestsCookieJar’>
這玩意兒怕是不能存到文本里面吧,誰去試一下看看,
不過仔細觀察一下吧,這個cookies有沒有長得挺像一個字典型字串啊
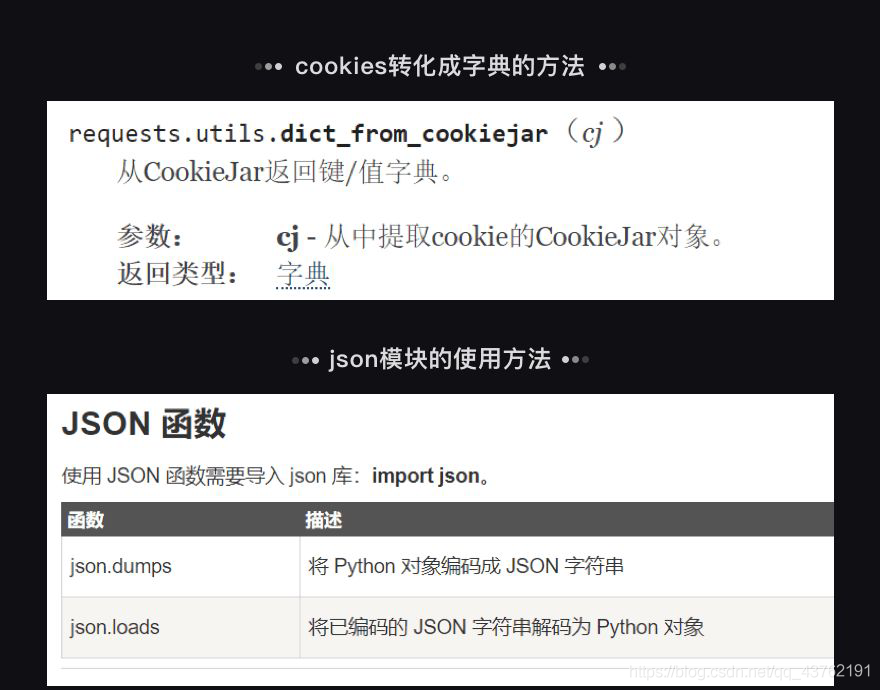
自己動手啊,我就說要一句:其實不用轉字串也可以試一下,不行了再轉也不遲,
當然了,還有其他的方式獲取到cookies,不過我這套方法是最直接的了,
自動化實作:selenium
現在的網站啊,也都不是傻子,哪個登錄不要你驗證碼的?極少數吧,
那這驗證碼不就得你手動去輸入了,當然,也有人說什么機器學習啊,破解驗證碼啊,想法不錯,動手試試嘛,
還有的網站啊,想必你也碰到過吧,阡陌交通,錯綜復雜的,爬個球啊爬,
就更不要說那些URL加密了啊,或者直接禁止爬蟲的網站了,
好,接下來我們就來看看這項即將要接觸的新技術:selenium能夠幫助我們闖過多少障礙,
先展示一下
粗略展示一下,打開瀏覽器,打開一篇博客,然后關掉,至于其他高端操作,我們后面通過代碼來展示:
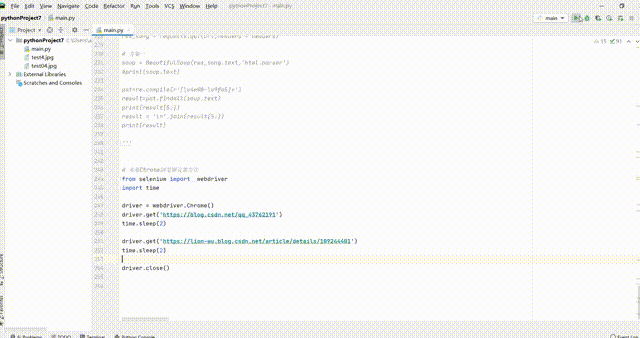
代碼展示
# 本地Chrome瀏覽器設定方法
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/qq_43762191')
time.sleep(2)
driver.get('https://lion-wu.blog.csdn.net/article/details/109244401')
time.sleep(2)
driver.close()
代碼給你們,你們拿去試試看,多半是運行不起來的,因為你們多半沒有配置環境,
環境配置
好,沒環境都不用著急,一切都會如期而至的嘛,
首先,你需要一個谷歌瀏覽器,一直在說,應該沒有小伙伴還沒下載吧,
其次,你需要看一下你的谷歌瀏覽器的版本,這個很重要,因為一代版本對應的是一代驅動,匹配不上的話問題就會有點麻煩了,
接下來,我們來下載一個驅動:http://npm.taobao.org/mirrors/chromedriver/
版本自己挑啊,
下載完之后,解壓,把這個驅動放到Python安裝的同級目錄下,如果不知道是哪個,那就下載了有多少個Python安裝嫌疑目錄就放多少個唄,
好,再打開pycharm,運行前面的代碼,
哦,對了,你還要下載一個selenium的包,還有點大,
今天不講太多的操作,就開個頭,字數也八千多了,把好玩的東西都留到下一篇嘛,
那接下來來講一下上面那幾行代碼,開個好頭,我知道,可能會有小伙伴接著就自己去查了啊,
selenium簡單講解
設定瀏覽器引擎
#第一步,匯入模塊,不過多贅述
from selenium import webdriver
import time
driver = webdriver.Chrome() #獲取對谷歌瀏覽器的控制權,這里如果沒有驅動的話是會直接報錯的
driver.get('https://blog.csdn.net/qq_43762191') #命令谷歌瀏覽器:嘿,小樣兒,給老子打開這個網頁
time.sleep(2) #主要是因為瀏覽器慢了點,還是說網路慢了點,反正就是有延遲,你等兩秒唄,
driver.get('https://lion-wu.blog.csdn.net/article/details/109244401') #再開一個
time.sleep(2) #同上
driver.close() #行了,玩到這里,關了
selenium能干嘛?
我就這么說吧,上面這一段,把Chrome瀏覽器設定為引擎,然后賦值給變數driver,driver是實體化的瀏覽器,在后面你會總是能看到它的影子,這也可以理解,因為我們要控制這個實體化的瀏覽器為我們做一些事情,
你懂得,
為什么selenium這么能干?
selenium能把我們前面遇到的問題簡化,爬動態網頁如爬靜態網頁一樣簡單,
剛開始我們直接用BeautifulSoup就能處理掉的那種網頁,就是靜態網頁,我們使用BeautifulSoup爬取這型別網頁,因為網頁源代碼中就包含著網頁的所有資訊,因此,網頁地址欄的URL就是網頁源代碼的URL,
后來,我們開始接觸更復雜的網頁,我要是沒有記錯的話,咱是從抓取CSDN的評論開始的吧,那時候我們開始接觸到了json,
還有后面的QQ音樂,要爬取的資料不在HTML源代碼中,而是在json中,你就不能直接使用網址欄的URL了,而需要找到json資料的真實URL,這就是一種動態網頁,
不論資料存在哪里,瀏覽器總是在向服務器發起各式各樣的請求,當這些請求完成后,它們會一起組成開發者工具的Elements中所展示的,渲染完成的網頁源代碼,
在遇到頁面互動復雜或是URL加密邏輯復雜的情況時,selenium就派上了用場,它可以真實地打開一個瀏覽器,等待所有資料都加載到Elements中之后,再把這個網頁當做靜態網頁爬取就好了,
說了這么多優點,使用selenium時,當然也有美中不足之處,
由于要真實地運行本地瀏覽器,打開瀏覽器以及等待網渲染完成需要一些時間,selenium的作業不可避免地犧牲了速度和更多資源,不過,至少不會比人慢,所以上面讓你等著,年輕人嘛,寧停三分鐘,不搶一秒鐘嘛,
就到這里啊,留點懸念嘛,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/210419.html
標籤:其他