源代碼&資料集下載地址:https://download.csdn.net/download/princessyang/12504757
一、獲取世界各國疫情歷史資料
1.1 選取資料源
選擇網易的疫情實時動態播報平臺作為資料源,其地址如下:
https://wp.m.163.com/163/page/news/virus_report/index.html?nw=1&anw=1
# 首先匯入使用的包,使用request進行網頁請求,使用pandas保存資料,
import requests
import pandas as pd
import time
pd.set_option('max_rows',500)
# 設定請求頭,偽裝為瀏覽器
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
# 發起請求,將找到的第一個資料源作為請求目標,
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total' # 定義要訪問的地址
r = requests.get(url, headers=headers) # 使用requests發起請求
print(r.status_code) # 查看請求狀態,回應狀態為200表示請求成功
print(type(r.text)) #查看型別, r.text——文本獲取, r.content——圖片、音頻獲取,
print(len(r.text)) # 查看文本長度
200
<class ‘str’>
301443
回傳后的內容是一個30萬長度的字串,由于字串格式不方便進行分析,并且在網頁預覽中發現資料為類似字典的json格式,所以這里將其轉為json格式,
# 將字串格式轉為json格式,
import json
data_json = json.loads(r.text)
data_json.keys() # data鍵存放著需要的資料
dict_keys([‘reqId’, ‘code’, ‘msg’, ‘data’, ‘timestamp’])
取出 json 中的需要使用的資料
data = data_json['data'] # 取出json中的資料
data.keys()
dict_keys([‘chinaTotal’, ‘chinaDayList’, ‘lastUpdateTime’, ‘overseaLastUpdateTime’, ‘areaTree’])
資料中總共有四個鍵,每個鍵存盤著不同的內容:
| 鍵名稱 | 資料內容 |
|---|---|
| chinaTotal | 全國當日資料 |
| chinaDayList | 全國歷史資料 |
| lastUpdateTime | 更新時間 |
| areaTree | 世界各地實時資料 |
1.2 世界各國實時資料獲取 today_data
自定義函式
# 將提取資料的方法封裝為函式
def get_data(data,info_list):
info = pd.DataFrame(data)[info_list] # 主要資訊
today_data = pd.DataFrame([i['today'] for i in data ]) # 生成today的資料
today_data.columns = ['today_'+i for i in today_data.columns] # 修改列名
total_data = pd.DataFrame([i['total'] for i in data ]) # 生成total的資料
total_data.columns = ['total_'+i for i in total_data.columns] # 修改列名
return pd.concat([info,total_data,today_data],axis=1) # info、today和total橫向合并最終得到匯總的資料
# 定義保存資料方法
def save_data(data,name):
file_name = name+'_'+time.strftime('%Y_%m_%d',time.localtime(time.time()))+'.csv'
data.to_csv(file_name,index=None,encoding='utf_8_sig')
print(file_name+' 保存成功!')
time.strftime('%Y_%m_%d',time.localtime(time.time()))
在 json 資料 data 中的 areaTree 是串列格式,每個元素都是一個國家的實時資料,每個元素的 children 是各國家省份的資料,現在來提取世界各國實時資料,
areaTree = data['areaTree'] # 取出 areaTree——世界各地實時資料
areaTree[0] # 查看第一個國家的資料
{‘today’: {‘confirm’: 2,
‘suspect’: 0,
‘heal’: 1,
‘dead’: 0,
‘severe’: 0,
‘storeConfirm’: 1},
‘total’: {‘confirm’: 1086,
‘suspect’: 0,
‘heal’: 965,
‘dead’: 48,
‘severe’: 0},
‘extData’: {},
‘name’: ‘突尼斯’,
‘id’: ‘9577772’,
‘lastUpdateTime’: ‘2020-06-03 14:01:28’,
‘children’: []}
areaTre 中每個鍵值的含義:
| 鍵名稱 | 資料內容 |
|---|---|
| today | 當日資料 |
| total | 累計資料 |
| extData | 無資料 |
| name | 國家名稱 |
| id | 各國編號 |
| lastUpadateTime | 更新時間 |
| chilfren | 各國下一級資料 |
使用 for 回圈查看前5個國家的名稱和更新時間
for i in range(len(areaTree)): # 查看各國家名稱和更新時間
print(areaTree[i]['name'],areaTree[i]['lastUpdateTime'])
if i == 5:
break
突尼斯 2020-06-03 14:01:28
塞爾維亞 2020-06-03 14:23:53
中國 2020-06-03 14:18:58
日本 2020-06-03 10:03:11
泰國 2020-06-03 10:03:38
新加坡 2020-06-03 10:05:02
從 areaTree 中提取各個國家的實時資料,
today_world = get_data(areaTree,['id','lastUpdateTime','name'])
today_world.head() # 查看獲取資料的前5行
| id | lastUpdateTime | name | total_confirm | total_suspect | total_heal | total_dead | total_severe | total_input | today_confirm | today_suspect | today_heal | today_dead | today_severe | today_storeConfirm | today_input | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 9577772 | 2020-06-03 14:01:28 | 突尼斯 | 1086 | 0 | 965 | 48 | 0 | NaN | 2.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | NaN |
| 1 | 9507896 | 2020-06-03 14:23:53 | 塞爾維亞 | 11454 | 0 | 6766 | 245 | 0 | NaN | 24.0 | 0.0 | 40.0 | 1.0 | 0.0 | -17.0 | NaN |
| 2 | 0 | 2020-06-03 14:18:58 | 中國 | 84602 | 3 | 79825 | 4645 | 2 | 1762.0 | 7.0 | 0.0 | 3.0 | 0.0 | 0.0 | 4.0 | 1.0 |
| 3 | 1 | 2020-06-03 10:03:11 | 日本 | 17712 | 0 | 15304 | 914 | 0 | NaN | 51.0 | NaN | 173.0 | 2.0 | NaN | -124.0 | NaN |
| 4 | 2 | 2020-06-03 10:03:38 | 泰國 | 3083 | 0 | 2966 | 58 | 0 | NaN | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 | -1.0 | NaN |
將獲取資料保存到本地
save_data(today_world,'today_world')
1.3 世界各國歷史資料獲取 alltime_world
因為原始資料中沒有國家名稱,為了得到每個國家的名稱,需要生成國家編號和國家名稱的鍵值對,這樣就可以存盤國家名稱,在之前的世界各國實時資料 today_world 中有國家的編號和名稱,可以用它來生成鍵值對,
today_world[['id','name']].head()
country_dict = {key:value for key,value in zip(today_world['id'], today_world['name'])}
# 查看前五個內容
count = 0
for i in country_dict:
print(i,country_dict[i])
count += 1
if count == 5:
break
9577772 突尼斯
9507896 塞爾維亞
0 中國
1 日本
2 泰國
通過每個國家的編號訪問每個國家歷史資料的地址,然后獲取各個國家的歷史資料,
start = time.time()
for country_id in country_dict: # 遍歷每個國家的編號
try:
# 按照編號訪問每個國家的資料地址,并獲取json資料
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode='+country_id
r = requests.get(url, headers=headers)
json_data = json.loads(r.text)
# 生成每個國家的資料
country_data = get_data(json_data['data']['list'],['date'])
country_data['name'] = country_dict[country_id]
# 資料疊加
if country_id == '9577772':
alltime_world = country_data
else:
alltime_world = pd.concat([alltime_world,country_data])
print('-'*20,country_dict[country_id],'成功',country_data.shape,alltime_world.shape,
',累計耗時:',round(time.time()-start),'-'*20)
time.sleep(10)
except:
print('-'*20,country_dict[country_id],'wrong','-'*20)
-------------------- 突尼斯 成功 (80, 15) (80, 15) ,累計耗時: 1 --------------------
-------------------- 突尼斯 wrong --------------------
-------------------- 塞爾維亞 成功 (84, 15) (164, 15) ,累計耗時: 11 --------------------
-------------------- 中國 成功 (120, 15) (284, 15) ,累計耗時: 22 --------------------
-------------------- 日本 成功 (123, 15) (407, 15) ,累計耗時: 37 --------------------
……省略號
將獲取資料保存到本地
save_data(alltime_world,'alltime_world')
二、資料預處理
匯入資料
#讀取資料疫情資料alltime_world_2020_05_31.csv
import pandas as pd
alltime_world = pd.read_csv('alltime_world_2020_05_31.csv', encoding='utf-8') # 1)讀檔案
print( alltime_world.info() ) # 2)查看基本資訊
name_dict = {'date':'日期','name':'名稱','id':'編號','lastUpdateTime':'更新時間',
'today_confirm':'當日新增確診','today_suspect':'當日新增疑似',
'today_heal':'當日新增治愈','today_dead':'當日新增死亡',
'today_severe':'當日新增重癥','today_storeConfirm':'當日現存確診', 'today_input':'當日輸入',
'total_confirm':'累計確診','total_suspect':'累計疑似','total_heal':'累計治愈',
'total_dead':'累計死亡','total_severe':'累計重癥','total_input':'累計輸入'} # 3)創建中文列名字典
alltime_world.rename(columns=name_dict, inplace=True) # 4)將英文列名更改中文列名
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 12331 entries, 0 to 12330
Data columns (total 15 columns):
# Column Non-Null Count Dtype
— ------ -------------- -----
0 date 12331 non-null object
1 total_confirm 12331 non-null int64
2 total_dead 12331 non-null int64
3 total_heal 12331 non-null int64
4 total_input 12331 non-null int64
5 total_severe 12331 non-null int64
6 total_suspect 12331 non-null int64
7 today_confirm 12331 non-null int64
8 today_dead 12331 non-null int64
9 today_heal 12331 non-null int64
10 today_input 12135 non-null float64
11 today_severe 10408 non-null float64
12 today_storeConfirm 0 non-null float64
13 today_suspect 10808 non-null float64
14 name 12331 non-null object
dtypes: float64(4), int64(9), object(2)
memory usage: 1.4+ MB
## 使用下面屬性和函式查看資料的大概資訊
alltime_world.info() # 查看二維資料表的大資訊
print('\n\n查看二維資料表的統計訊息,統計數值型資料: \n', alltime_world.describe() )
print('\n\n查看二維資料表的列標簽:\n', alltime_world.columns )
print('\n\n查看二維資料表的行標簽:\n', alltime_world.index )
print('\n\n查看二維資料表的值:\n', alltime_world.values )
print('\n\n查看二維資料表的前5行:\n', alltime_world.head() )
print('\n\n查看二維資料表的后5行:\n', alltime_world.tail() )
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 12331 entries, 0 to 12330
Data columns (total 15 columns):
# Column Non-Null Count Dtype
— ------ -------------- -----
0 日期 12331 non-null object
1 累計確診 12331 non-null int64
2 累計死亡 12331 non-null int64
3 累計治愈 12331 non-null int64
4 累計輸入 12331 non-null int64
5 累計重癥 12331 non-null int64
6 累計疑似 12331 non-null int64
7 當日新增確診 12331 non-null int64
8 當日新增死亡 12331 non-null int64
9 當日新增治愈 12331 non-null int64
10 當日輸入 12135 non-null float64
11 當日新增重癥 10408 non-null float64
12 當日現存確診 0 non-null float64
13 當日新增疑似 10808 non-null float64
14 名稱 12331 non-null object
dtypes: float64(4), int64(9), object(2)
memory usage: 1.4+ MB
……省略號
查看 alltime_world 資料每列的缺失值比例
# 計算缺失值比例
alltime_world_nan = alltime_world.isnull().sum()/len(alltime_world)
# 轉變為百分數
alltime_world_nan.apply(lambda x: format(x, '.1%'))
日期 0.0%
累計確診 0.0%
累計死亡 0.0%
累計治愈 0.0%
累計輸入 0.0%
累計重癥 0.0%
累計疑似 0.0%
當日新增確診 0.0%
當日新增死亡 0.0%
當日新增治愈 0.0%
當日輸入 1.6%
當日新增重癥 15.6%
當日現存確診 100.0%
當日新增疑似 12.4%
名稱 0.0%
dtype: object
可以現當日新增相關資料缺失值較多,這主要由于采集資料的當天一些國家沒有更新資料,因此這里將不再對其進行分析,當日現存確診一列雖然全部為空,但該缺失值可以通過已有資料直接計算,公式為:
當日現存確診=累計確診-累計治愈-累計死亡
缺失值處理
# 先使用線性插值的方式填充缺失值
alltime_world.interpolate(method='linear', inplace=True)
# 再使用0填充缺失值
alltime_world.fillna(0, inplace=True)
# 計算當日現存確診人數(當日現存確診=累計確診-累計治愈-累計死亡)
alltime_world['當日現存確診'] = alltime_world['累計確診']-alltime_world['累計治愈']-alltime_world['累計死亡']
# 將日期改成datetime格式
alltime_world['日期'] = pd.to_datetime(alltime_world['日期'])
alltime_world.info()
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 12331 entries, 0 to 12330
Data columns (total 15 columns):
# Column Non-Null Count Dtype
— ------ -------------- -----
0 日期 12331 non-null datetime64[ns]
1 累計確診 12331 non-null int64
2 累計死亡 12331 non-null int64
3 累計治愈 12331 non-null int64
4 累計輸入 12331 non-null int64
5 累計重癥 12331 non-null int64
6 累計疑似 12331 non-null int64
7 當日新增確診 12331 non-null int64
8 當日新增死亡 12331 non-null int64
9 當日新增治愈 12331 non-null int64
10 當日輸入 12331 non-null float64
11 當日新增重癥 12331 non-null float64
12 當日現存確診 12331 non-null int64
13 當日新增疑似 12331 non-null float64
14 名稱 12331 non-null object
dtypes: datetime64ns, float64(3), int64(10), object(1)
memory usage: 1.4+ MB
三、資料分析可視化1–matplotlib繪圖
3.1 繪制多個國家的累計確診人數折線圖
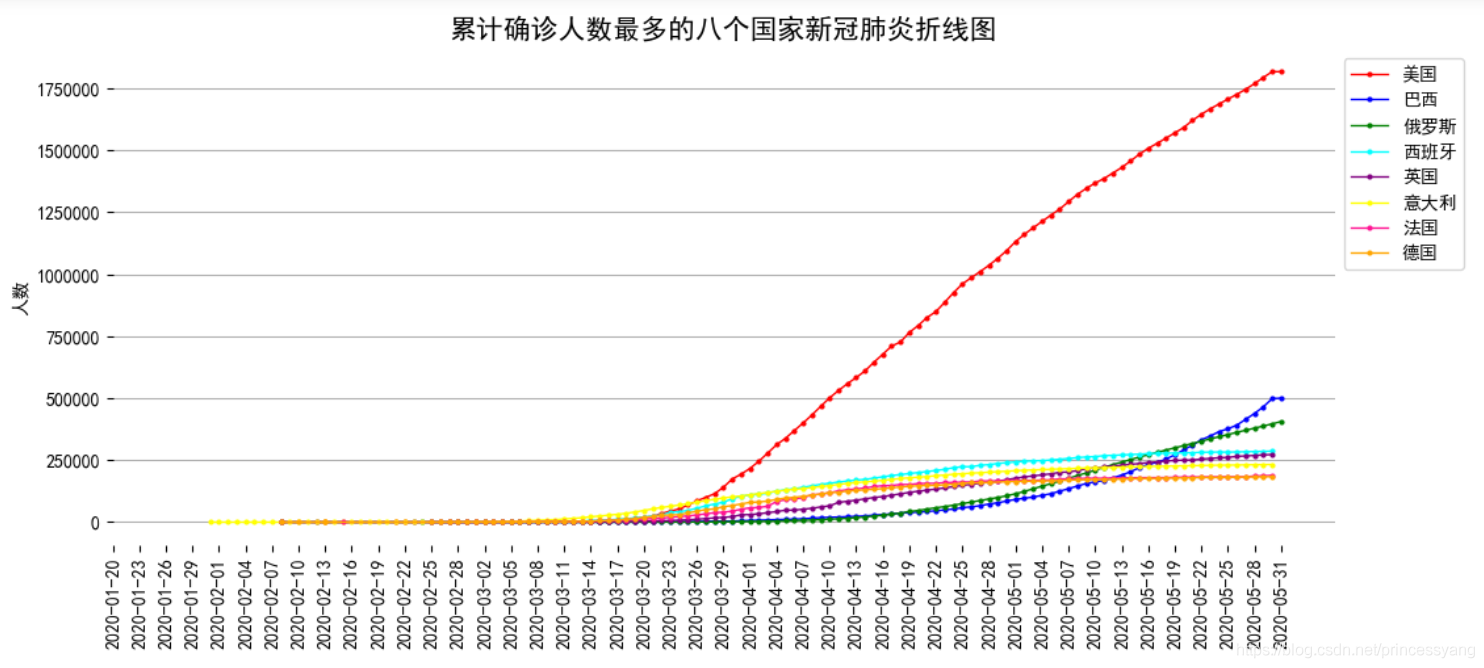
使用 matplotlib 庫繪制累計確診人數最多的8個國家(‘美國’,‘巴西’,‘俄羅斯’,‘西班牙’,‘意大利’,‘英國’,‘法國’,‘德國’)的累計確診人數折線圖
# 查看“累計確診”人數最多的8個國家資料,并可視化
import matplotlib.pyplot as plt
import matplotlib as mpl
# 自定義函式,接收國家和顏色兩個引數,每次呼叫繪制一個國家的折線圖
def line_chart(name,color1):
x = alltime_world.loc[alltime_world.名稱==name,'日期']
y_total = alltime_world.loc[alltime_world.名稱==name,'累計確診']
ax.plot(x,y_total,color=color1,lw=1,marker='o',ms=2,label=name)
# 創建畫布,切分繪圖區域,繪制兩條曲線
figure = plt.figure(figsize=(12,5))
ax = plt.subplot()
# 設定繪圖區字體
mpl.rcParams['font.family'] = 'simhei' # 設定顯示字體
mpl.rcParams['font.size'] = 10 # 設定顯示字體大小
# 資料準備
country_name = alltime_world.groupby(by='名稱')['累計確診'].max().sort_values(ascending=False)[:8].index # 累計確診人數最多的八個國家
color1 = ['red','blue','green','cyan','purple','yellow','deeppink','orange'] # 設定八個顏色
# 遍歷八個國家,呼叫自定義函式繪圖
for i in range(len(country_name)):
line_chart(country_name[i],color1[i])
# 設定圖外觀(圖示題,y軸標題,圖例等)
plt.title('累計確診人數最多的八個國家新冠肺炎折線圖',size=15)
plt.ylabel('人數')
plt.legend(bbox_to_anchor=[1,1]) # 圖例位置調整
plt.grid(axis='y') # 添加y軸橫線
plt.box(False)
# 設定x軸日期顯示格式等
ax.xaxis.set_major_formatter(mpl.dates.DateFormatter('%Y-%m-%d')) # 設定時間標簽顯示格式
plt.xticks(pd.date_range(min(alltime_world.日期),max(alltime_world.日期),freq='3D'),rotation=90)# 設定時間標簽顯示格式
plt.show()
3.2 繪制各國新增確診人數折線圖
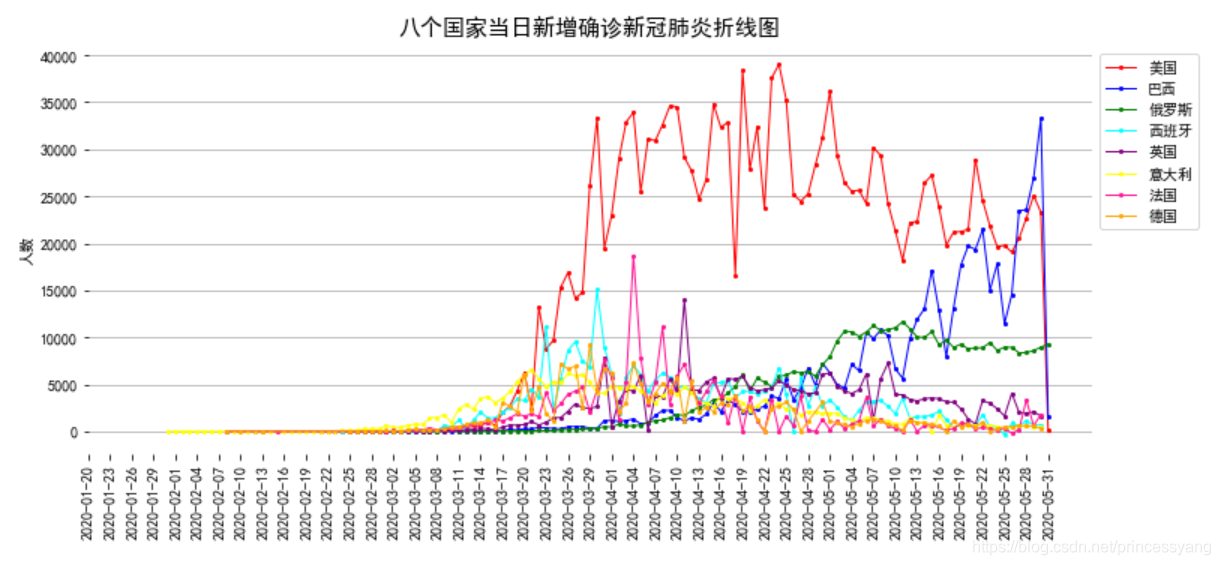
使用 matplotlib 庫繪制累計確診人數最多的8個國家(‘美國’,‘巴西’,‘俄羅斯’,‘西班牙’,‘意大利’,‘英國’,‘法國’,‘德國’)的新增確診人數折線圖
# 查看“累計確診”人數最多的8個國家的“當日新增確診”的資料,并可視化
import matplotlib.pyplot as plt
import matplotlib as mpl
# 自定義函式,接收國家和顏色兩個引數,每次呼叫繪制一個國家的折線圖
def line_chart(name,color1):
x = alltime_world.loc[alltime_world.名稱==name,'日期']
y_total = alltime_world.loc[alltime_world.名稱==name,'當日新增確診']
ax.plot(x,y_total,color=color1,lw=1,marker='o',ms=2,label=name)
# 創建畫布,切分繪圖區域,繪制兩條曲線
figure = plt.figure(figsize=(12,5))
ax = plt.subplot()
# 設定繪圖區字體
mpl.rcParams['font.family'] = 'simhei' # 設定顯示字體
mpl.rcParams['font.size'] = 10 # 設定顯示字體大小
# 資料準備
country_name = alltime_world.groupby(by='名稱')['累計確診'].max().sort_values(ascending=False)[:8].index # 累計確診人數最多的八個國家
color1 = ['red','blue','green','cyan','purple','yellow','deeppink','orange'] # 設定八個顏色
# 遍歷八個國家,呼叫自定義函式繪圖
for i in range(len(country_name)):
line_chart(country_name[i],color1[i])
# 設定圖外觀(圖示題,y軸標題,圖例等)
plt.title('八個國家當日新增確診新冠肺炎折線圖',size=15)
plt.ylabel('人數')
plt.legend(bbox_to_anchor=[1,1]) # 圖例位置調整
plt.grid(axis='y') # 添加y軸橫線
plt.box(False)
# 設定x軸日期顯示格式等
ax.xaxis.set_major_formatter(mpl.dates.DateFormatter('%Y-%m-%d')) # 設定時間標簽顯示格式
plt.xticks(pd.date_range(min(alltime_world.日期),max(alltime_world.日期),freq='3D'),rotation=90)# 設定時間標簽顯示格式
plt.show()
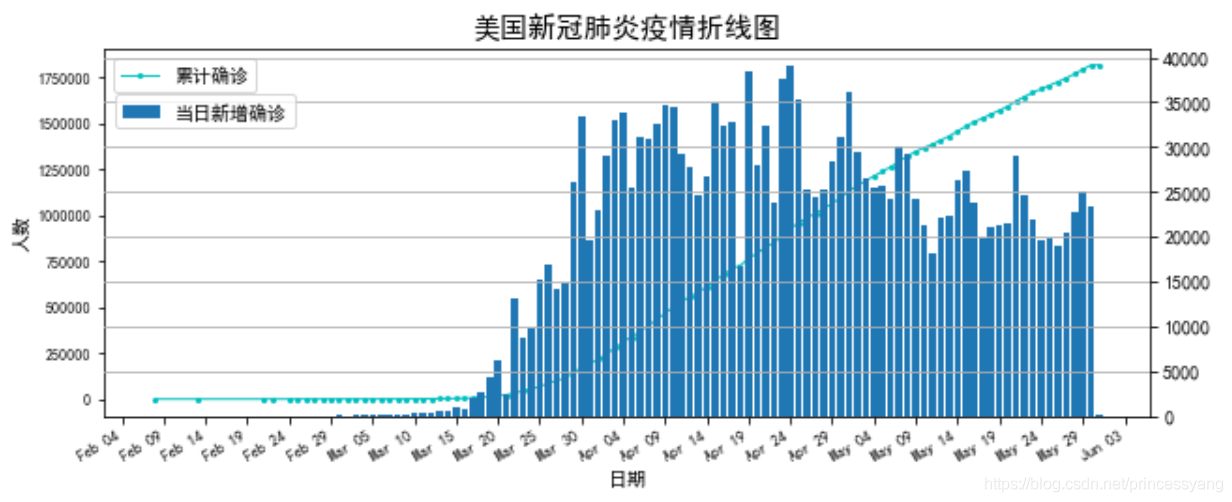
3.3 美國新冠肺炎的累計確診和當日新增確診繪制
繪制美國新冠肺炎的累計確診和當日新增確診的折線圖與柱形圖
# 資料準備
American = alltime_world[alltime_world['名稱']=='美國']
American.set_index('日期',inplace=True)# 設定日期為索引
# 創建畫布
fig, ax = plt.subplots(figsize=(10, 4))
# 設定繪圖區字體
mpl.rcParams['font.family'] = 'simhei' # 設定顯示字體
mpl.rcParams['font.size'] = 10 # 設定顯示字體大小
# 畫圖
American['累計確診'].plot(ax=ax, fontsize=8,style='-',lw=1,color='c',marker='o',ms=2,legend=True) # 累計確診折線圖
ax1 = ax.twinx()
ax1.bar(American.index, American['當日新增確診']) # 當日新增確診柱形圖
# 設定x軸日期顯示格式等
ax1.xaxis.set_major_locator(mpl.dates.DayLocator(interval = 5)) #設定間距
ax1.xaxis.set_major_formatter(mpl.dates.DateFormatter('%b %d')) #設定日期格式
fig.autofmt_xdate() #自動調整日期傾斜
# 設定圖外觀(圖示題,y軸標題,圖例等)
plt.title('美國新冠肺炎疫情折線圖',size=15)
ax.set_ylabel('人數', fontsize=10)
ax.set_xlabel('日期', fontsize=10)
ax1.legend(['當日新增確診'],loc='upper left',bbox_to_anchor=(0.001, 0.9)) # 設定圖例
plt.grid(axis='y')
plt.box(False)
plt.show()
四、資料分析可視化2–pyecharts繪圖
資料準備
# 匯入資料
import pandas as pd
world_data = pd.read_csv('alltime_world_2020_05_31.csv', encoding='utf-8')
# 缺失值處理
# 先使用線性插值的方式填充缺失值
world_data.interpolate(method='linear', inplace=True)
# 再使用0填充缺失值
world_data.fillna(0, inplace=True)
# 計算當日現存確診人數
world_data['today_storeConfirm'] = world_data['total_confirm']-world_data['total_heal']-world_data['total_dead']
# 將日期改成datetime格式
world_data['date'] = pd.to_datetime(world_data['date'])
# 選取最新更新的各國資料
world_data_groupby = world_data[['name','date','total_confirm']].groupby(by=['name'], as_index=False).max()
world_data_merge = pd.merge(world_data_groupby, world_data, on=['name','date','total_confirm'], how='left')
4.1 世界各國家現存確診人數地圖
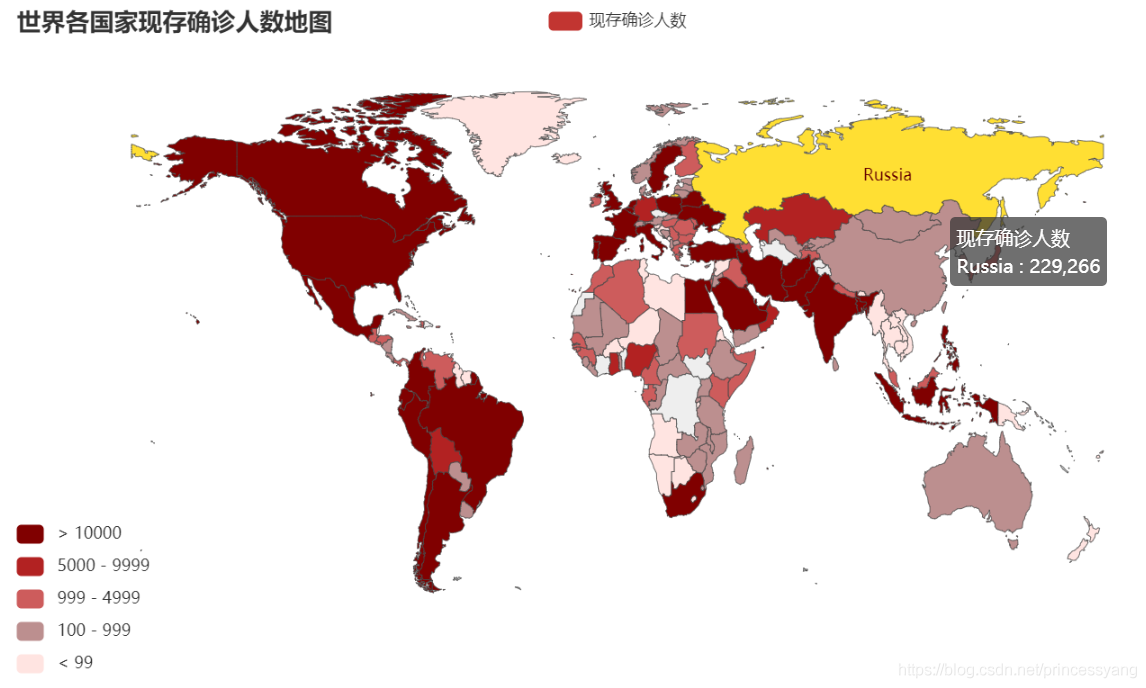
將各個國家數值資訊映射到地圖上,通過顏色變化來表示數值的大小或范圍,顏色地圖適合帶有地理位置資訊的資料的展現,將顏色和地圖相結合,直觀顯示資料的地理分布,通過顏色深淺容易判斷數值的大小,下圖顯示的是截止到5月31日,世界各國現有確診人數地圖,每個區域被賦予一種顏色,通過查看左下角的圖例可以明確每種顏色對應的數值范圍,圖例中的顏色由下至上依次從淺到深,數值范圍也相應地由小到大,
# 匯入pyecharts庫以及繪圖需要的相關類
import pyecharts
import pyecharts.options as opts # 調整配置項
from pyecharts.charts import Map # Map類用于繪制地圖
from pyecharts.charts import Pie # Pie類用于繪制玫瑰圖
from datetime import datetime,timedelta # datetime模塊生成時間資料
import matplotlib.pyplot as plt # 載入Matplotlib庫
利用 Map類繪制世界地圖時,需要輸入各國家的英文名稱和對應的數值,首先要將資料的中文名稱轉換為英文名稱,
# 載入國家中英文對照表,使用Series類的replace方法將各國家對應的中文名稱替換成英文名稱
contry_name = pd.read_csv('county_china_english.csv', encoding='gbk')
world_data_merge['eg_name'] = world_data_merge['name'].replace(contry_name['中文'].values ,contry_name['英文'].values)
# 提取出需要的資料,保存成一個嵌套串列的形式
heatmap_data = world_data_merge[['eg_name','today_storeConfirm']].values.tolist()
heatmap_data[:10]
[[‘Bhutan’, 37.0],
[‘Timor-Leste’, 0.0],
[‘China’, 118.0],
[‘Central African Rep.’, 938.0],
[‘Denmark’, 735.0],
[‘Ukraine’, 13426.0],
[‘Uzbekistan’, 757.0],
[‘Uganda’, 341.0],
[‘Uruguay’, 117.0],
[‘Chad’, 224.0]]
接下來開始繪圖
# 首先初始化類物件Map,并呼叫add方法添加繪圖基本配置
map_ = Map().add(series_name = "現存確診人數", # 設定提示框標簽
data_pair = heatmap_data, # 輸入資料
maptype = "world", # 設定地圖型別為世界地圖
is_map_symbol_show = False # 不顯示標記點
)
# 設定系列配置項
map_.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) # 不顯示國家(標簽)名稱
# 設定全域配置項
map_.set_global_opts(title_opts = opts.TitleOpts(title="世界各國家現存確診人數地圖"), # 設定圖示題
# 設定視覺映射配置項
visualmap_opts = opts.VisualMapOpts(pieces=[ # 自定義分組的分點和顏色
{"min": 10000,"color":"#800000"}, # 栗色
{"min": 5000, "max": 9999, "color":"#B22222"}, # 耐火磚
{"min": 999, "max": 4999,"color":"#CD5C5C"}, # 印度紅
{"min": 100, "max": 999, "color":"#BC8F8F"}, # 玫瑰棕色
{"max": 99, "color":"#FFE4E1"}, # 薄霧玫瑰
],
is_piecewise = True)) # 顯示分段式圖例
# 呼叫render_notebook方法直接在jupyter notebook中渲染圖形
map_.render_notebook()
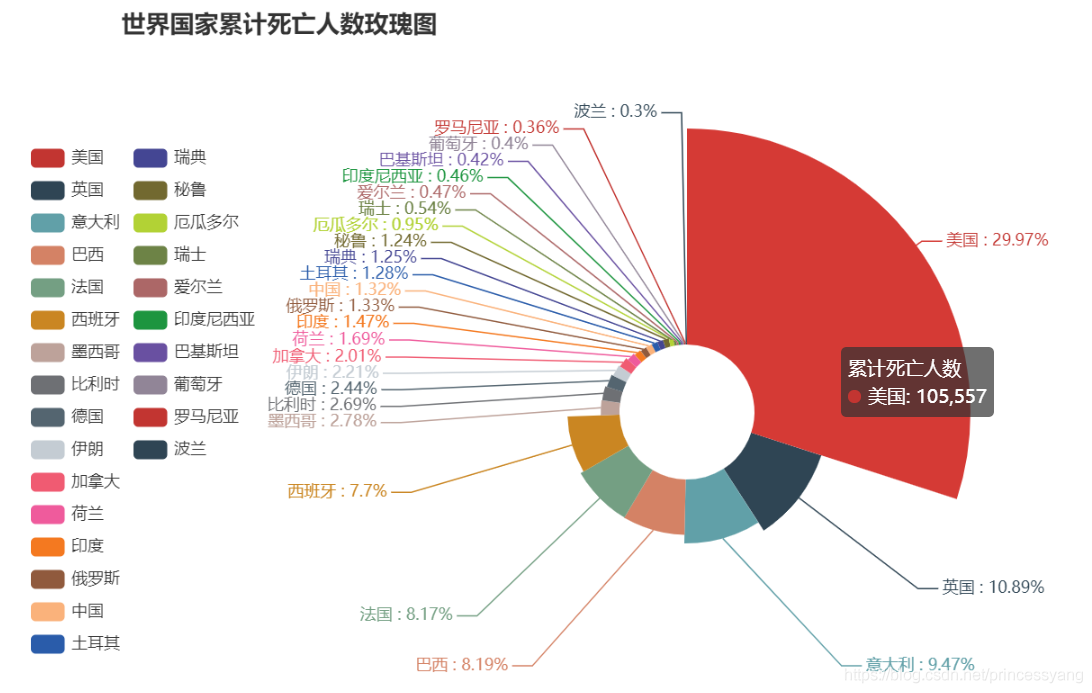
4.2 世界國家累計死亡人數玫瑰圖
玫瑰圖是一種二維極坐標統計圖,玫瑰圖與餅狀圖類似,餅狀圖各個扇形的半徑相同,角度不同,角度表示每一部分占比的大小;玫瑰圖各個扇形的半徑和角度都不同,角度依然表示每一部分的占比大小,半徑表示每一部分的數值大小,下圖是一個特殊的玫瑰圖,扇形角度一致,半徑不同,可以很清楚觀察到海外每個國家累計確診人數的大小對比關系,
繪制累計死亡人數超過1000人的國家的累計死亡人數玫瑰圖
# 首先篩選出累計死亡人數超過1000人的世界國家,并按人數進行降序排序
need_data = world_data_merge[['name','total_dead']][world_data_merge['total_dead'] >1000]
rank = need_data[['name','total_dead']].sort_values(by='total_dead',ascending=False).values
# 接著導添加繪圖的基本配置
pie = Pie().add("累計死亡人數", # 添加提示框標簽
rank, # 輸入資料
radius = ["20%", "80%"], # 設定內半徑和外半徑
center = ["60%", "60%"], # 設定圓心位置
rosetype = "radius") # 玫瑰圖模式,通過半徑區分數值大小,角度大小表示占比
# 最后設定全域和系列配置項并繪制玫瑰圖
pie.set_global_opts(title_opts = opts.TitleOpts(title="世界國家累計死亡人數玫瑰圖", # 設定圖示題
pos_right = '60%'), # 圖示題的位置
legend_opts = opts.LegendOpts( # 設定圖例
orient='vertical', # 垂直放置圖例
pos_right="75%", # 設定圖例位置
pos_top="20%"))
pie.set_series_opts(label_opts = opts.LabelOpts(formatter="{b} : {d}%")) # 設定標簽文字形式為(國家:占比(%))
# 在notebook中進行渲染
pie.render_notebook()
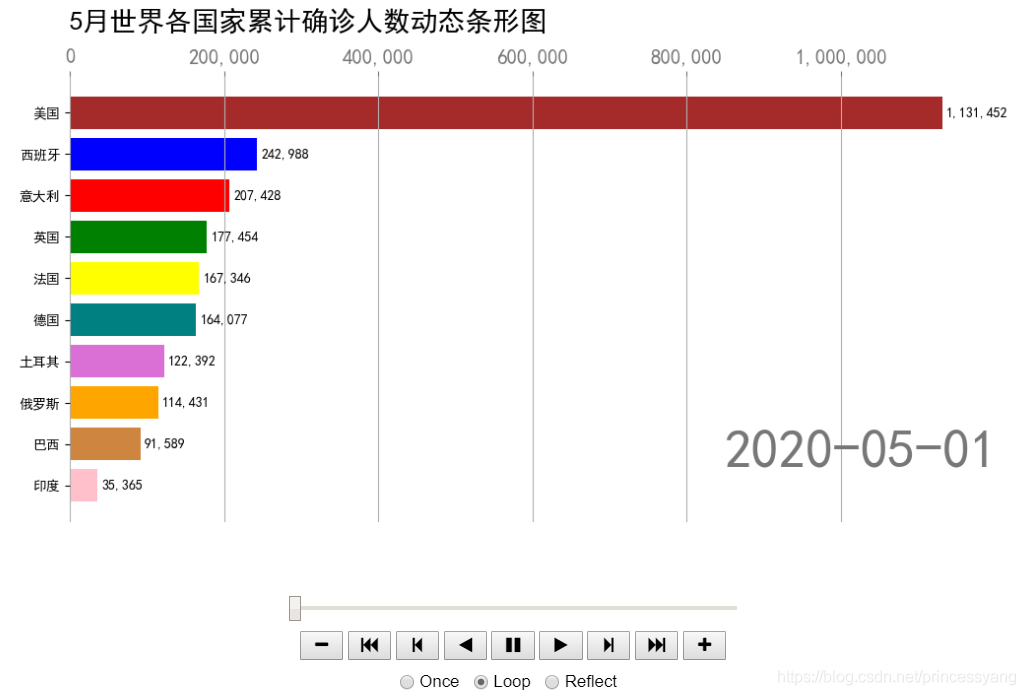
4.3 五月世界國家累計確診人數動態條形圖
條形圖由一些長度不等的橫向長方形組成,以長方形的長度來表示資料,易于比較各組資料之間的差別,
動態圖表是目前非常流行的一種可視化方法,可以按照時間序列動態展示條形圖資料的變化,
繪制5月份累計確診人數最多的10個國家的動態條形圖(‘美國’, ‘巴西’, ‘俄羅斯’, ‘西班牙’, ‘英國’, ‘意大利’, ‘法國’, ‘德國’, ‘印度’, ‘土耳其’)
# 首先挑選出疫情最為嚴重的10個國家,并篩選出這些國家的歷史疫情資料
country_list = world_data.groupby(by='name')['total_confirm'].max().sort_values(ascending=False)[:10].index # 累計確診人數最多的10個國家
need_data = world_data[world_data['name'].isin(country_list)]
# 接下來使用datetime模塊生成時間資料,構造時間串列
time_list = [(datetime(2020, 5, 1) + timedelta(i)).strftime('%Y-%m-%d') for i in range(31)]
# 載入Matplotlib庫,并設定正常顯示中文字體
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['figure.dpi'] = 100
# 為每個國家設定一種顏色
color_list = ['brown','peru','orange','blue','green','red','yellow','teal','pink','orchid']
country_color = pd.DataFrame()
country_color['country'] = country_list
country_color['color'] = color_list
自定義繪圖函式
# 定義繪圖函式
import matplotlib.ticker as ticker
def barh_draw(day):
# 提取每一天的資料
draw_data = need_data[need_data['date']==day][['name','total_confirm']].sort_values(by='total_confirm',ascending=True)
# 清空當前的繪圖
ax.clear()
# 繪制條形圖
ax.barh(draw_data['name'],draw_data['total_confirm'], color=[country_color[country_color['country']==i]['color'].values[0] for i in draw_data['name']])
# 數值標簽的間距
dx = draw_data['total_confirm'].max()/200
# 添加數值標簽
for j, (name, value) in enumerate(zip(draw_data['name'], draw_data['total_confirm'])):
ax.text(value+dx, j, f'{value:,.0f}', size=10, ha='left', va='center')
# 添加日期標簽
ax.text(draw_data['total_confirm'].max()*0.75, 0.4, day, color='#777777',size=40, ha='left')
# 設定刻度標簽的格式
ax.xaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.0f}'))
# 設定刻度的位置
ax.xaxis.set_ticks_position('top')
# 設定刻度標簽的顏色和大小
ax.tick_params(axis='x',colors='#777777', labelsize=15)
# 添加網格線
ax.grid(which='major',axis='x',linestyle='-')
# 添加圖示題
ax.text(0, 11, '5月世界各國家累計確診人數動態條形圖',size=20, ha='left')
# 去除圖邊框
plt.box(False)
# 關倍訓圖框
plt.close()
繪制動態條形圖
# 動態繪圖
fig, ax = plt.subplots(figsize=(12, 6))
import matplotlib.animation as animation
from IPython.display import HTML
animator = animation.FuncAnimation(fig, barh_draw, frames=time_list, interval=200)
HTML(animator.to_jshtml())
參考資料
[1] http://cookdata.cn/note/view_static_note/fa203bf68cc57b10af2773bf5b48fd34/
[2] http://cookdata.cn/note/view_static_note/f4edb8aed12abe451206406efee375d7/
[3] http://cookdata.cn/note/view_static_note/84230091c4104946ab3d22dd675df58d/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/222615.html
標籤:其他