我打算寫一本介紹搜索引擎制作的書,目前想邊寫邊發,希望大家看了能給點反饋。題目就是“如何制作一個搜索引擎”
前言
現在市面上有很多介紹如何制作搜索引擎的書籍,我在書城也曾隨手翻過一些,不過大多是書太厚,話太多,有種浪費生命的感覺。回想當年帶我入門的那本書是閻宏飛寫的《搜索引擎》,靠著這本書,我積累了關于搜索引擎的基礎知識,之后再加上老外的論文,最終完成了自己的碩士畢業論文。《搜索引擎》這本書主要闡述了搜索引擎的核心概念和思想,而在具體到實踐上則點到即止。我在做網站時積累了一些實踐的經驗,于是想貢獻出一點拙知,希望如果能對有需要的人起到一點幫助的作用,就足夠了。
一個搜索引擎能夠做到的最基本的事情是接受一個查詢輸入,然后給出與這個查詢輸入相關的一些結果。我們常見的搜索引擎百度就是這樣一個比較典型的例子。鑒于百度已經占據了國內的絕大部分的搜索份額,于是后來者便另辟蹊徑,期望能夠在現有的搜索市場中分得一杯羹,創造了垂直搜索的概念。垂直搜索是相對于類似百度或者谷歌這樣的通用搜索引擎而提出的。這類搜索引擎往往只針對某一個領域,比如現在國內常見的用來搜索bt和迅雷資源的搜索引擎。不過這類搜索引擎只是限制了通用搜索的查詢范圍,本質上與那些通用搜索引擎是沒有什么差別的,在具體實踐上反而要更加簡單一些。
我個人喜歡從應用的范圍層面來劃分,將搜索引擎分為普通互聯網搜索引擎和網站站內搜索引擎。互聯網搜索引擎需要面對惡劣的資料環境,它從各個不同的網站中搜集網頁資訊,而這些網站的html代碼可能極其不規范,搜索引擎要能夠從那些不規范的代碼中找出有用的資訊。相比互聯網搜索引擎,站內搜索引擎要輕松許多,它只處理站內有限的文本資訊,而且對于網站建設者而言,可以限制需要被搜索的內容,很多時候,站內搜索引擎根本不需要處理網頁代碼就能直接獲取到資訊本身。
在后續一系列圍繞如何制作搜索引擎的文章中,我將介紹實作一個通用搜素引擎所需的基礎知識,并幫助打造一個簡易的互聯網搜索引擎和站內搜索引擎。不過在這一切開始之前,讀者需懂得基本的編程知識和線性代數知識,否則閻宏飛老師的《搜索引擎》就已經足夠了。我會盡量在文章里使用偽代碼,盡量少的參考線性代數知識。不過我還是建議讀者學習一下c語言和javascript。在具體實踐中我們還將涉及nodejs和mongodb,這2個雖然不是編程語言,但是相當有用的中間件工具,有時間的話,也要了解一下。如果你曾學過java,nodejs就相當于weblogic,而mongodb就是oracle資料庫了。
uj5u.com熱心網友回復:
搜索引擎的基本框架一個完整的網路通用搜索引擎在邏輯上由四部分組成,根據圖1,分成資料采集、資料加工、資料索引、資料服務。
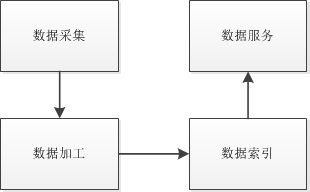
圖1
資料采集模塊俗稱網路爬蟲或者網路蜘蛛。雖然名字很形象,但是從實踐的角度來說,計算機程式的處理程序和昆蟲的自發行為有很大的差別。資料采集模塊需要能夠正確獲取到網站的網頁,它的行為更像我們在瀏覽器中輸入網址后不斷的點擊網頁鏈接。所以更為貼切的說法是資料采集模塊即模擬了網頁瀏覽器,又模擬了人類的網頁點擊行為。粗放地來看,資料采集模塊應該具有2個基本功能:
1:根據網頁地址(URL)獲取該地址對應的網頁檔案。
2:決議出網頁檔案中的鏈接地址和網頁有效資訊文本。
資料加工模塊是搜索引擎的核心功能,它負責對資料采集模塊采集的網頁有效資訊文本進行加工,使得我們人類能看懂的文字資訊能夠按照設定的規則被計算機理解。對于一個初級搜索引擎來說,需要將文本文字進行拆解、歸類,如果是中文,還需要在拆解的時候對中文進行分詞。之后將決議結果發送給索引模塊,索引模塊再進一步加工后錄入到搜索引擎的資料庫中。如果要實作一個更加智能的高級搜索引擎,在上述步驟的基礎上,還要能夠實作語意理解,這樣當用戶在搜索“明天星期幾”的時候,搜索引擎給出的應該是包含“明天是星期六”或者“明天是星期一”。。。。。。諸如此類的結果,而不僅僅是含有“明天星期幾”這5個關鍵詞的網頁結果集合。
資料索引模塊是搜索引擎的另外一個核心,它和資料加工模塊的關系就像人類的心和肺,缺一不可。這個模塊主要功能是將資料加工模塊的處理結果保存在一個規范的資料結構中,這樣做的目的是為了給接下去的資料服務模塊提供便利,使得資料服務模塊能夠在極短的時間內完成對整個互聯網資料的資訊檢索。
資料服務模塊是搜索引擎對外部提供服務的介面。它要能夠對外部輸入進行及時回應,并聯系資料索引模塊,取出用戶查找內容的網頁結果。很多時候,為了能夠高效地對用戶行為進行反饋,搜索引擎常常在這個模塊處實作一些預測或者快取演算法,別勉對用戶的每一次查詢都實施一次完整的資料查找流程。
從上述對4個模塊的描述可以看出,搜索引擎和一個圖書館的圖書檢索系統并沒有太大差別,且搜索引擎的模塊鏈都是單向且唯一的,不存在多個模塊之間需要進行資料互動,或者資料互動是雙向的。僅這一點而言,搜索引擎在邏輯上還是比較簡單的。我相信,讀者只要能夠堅持,最后實作一個實用的搜索引擎應用是完全沒有問題的。
uj5u.com熱心網友回復:
垂直搜索與站內搜索與互聯網通用搜索引擎相比,所謂的垂直搜索引擎和站內搜索引擎在概念上要簡單一些,可以把他們看作是在現有通用搜索引擎的概念上進行裁剪后所形成的產物。垂直搜索是針對某一特定行業領域進行搜索服務。比如提供BT資源搜索的搜索引擎。一般這類搜索引擎會在資料采集端進行簡化,只搜取指定網站的網頁資源。而在資料加工端,以BT資源搜索引擎為例,引擎只從網頁資訊中提取出資源名稱關鍵字與bt種子鏈接地址,并忽略其它資訊。在資料索引模塊,引擎只做簡單的關鍵字索引,無需對語意等做處理。站內搜索引擎則更加簡單一些,引擎在資料采集模塊只需被動等待資訊輸入。這是因為站點的設計是可控的,在任何資訊被站點的記錄同時傳一份副本給搜索引擎,搜索引擎便可執行其后續邏輯流程。搜索論壇帖子便是一個典型案例。當用戶提交一個帖子時,站點把提交內容轉發給站內搜索引擎,搜索引擎接收帖子文本后,開始資料加工并索引入庫。這一切都無需對網頁檔案進行處理,避免了大量的網頁標簽過濾作業。
隨著越來越多的網頁應用使用javascript來動態生成用戶內容,傳統的互聯網通用搜索引擎正在失去其傳統優勢。在移動優先的設計理念下,傳統通用搜索引擎搜集的靜態網頁有效內容可能只包含一行關鍵詞代碼,但網頁在用戶端卻能展現出豐富多彩的內容。所以在不久的將來,站內搜索將發揮越來越大的作用,可能每個公開站點都會有一個自己個性化的搜索引擎,原先由通用搜索引擎提供的站內搜索將逐漸消失。
uj5u.com熱心網友回復:
木擊倒啊··································································uj5u.com熱心網友回復:
我說,還會更新嗎uj5u.com熱心網友回復:
兄弟,更新呀uj5u.com熱心網友回復:

uj5u.com熱心網友回復:
我能說,現在搜索引擎已經進入人工智能階段嗎?現在更重要的是如何提供展現,而不是以前的如何分詞、如何索引等等,這些技術已經成熟,且趨于穩定。轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/226100.html
標籤:非技術區