UDP和運營商有什么關系?
這個問題有點大且突兀,只要不是在三大運營商上班的,其實我們都是端到端用戶,而端到端用戶對于網路的認知必然是盲目的,我們不知道路由器對我們的流量做了什么,我們更沒有能力去控制它們,我們只能猜測,
本來一個技術范疇的討論一旦涉及到了猜測,就不是技術討論了,而是社會學討論,這往往會帶來無休止的辯論,爭吵,在此其中,獨占鰲頭的往往不是靠技術實力,而是靠口才和措辭,或者還有夾雜著各種手勢的抑揚頓挫,
我是極其討厭充斥著此類調調的場合的,我在這種場合往往會選擇閉嘴,然后離開,
人們無休止地討論如何針對CC(Congestion Control)進行調優,其實每個人心里都沒底,說出來的貌似令人信服的話靠的無非就是自信和強勢,然后結論會瞬間打臉這種信口開河,
摘錄一段深信服白皮書上的話:
如上圖所示,剛好與傳統 TCP“慢上升、快下降”相對,HTP 快速傳輸協議對于資料傳輸為“快上升、慢下降”,當網路吞吐允許的情況下以最短的時間將傳輸速度提高到吞吐量所允許的最高;
搞得好像真的一樣,但其實這簡直就是扯淡!
很多人都說QUIC其實不如TCP,這個結論我至今都不知道從哪個 “權威” 那里得到的,就好像人們人云亦云地詬病Netfilter/iptales一樣,可是當你測驗的時候,卻發現 并不是每次 QUIC都不如TCP,
人們很少去深入探究中間網路,就好像開著個跑車在鬧市區依然總覺得自己能起飛一樣,說起運營商和TCP/UDP的關系,人們總是避而不談,結論往往就兩種:
- 你傻X啊,運營商和TCP/UDP毫無關系,
- 你想多了(或者就是腦子是個好東西…),運營商會深度決議你的每一個資料包的,
說的跟真事兒一樣,就好像他們無所不知的樣子,我不明白這些懂點兒網路的人為什么總是學不會懂禮貌,其實我脾氣也不好,我心里早就一萬個XXX了,
但如果哪一天我也想聊聊這種話題,我會從一個具體的事情開始,嗯,今天就是,2021年春節前最后的一個周末,
我不能理解的一個問題是 一個UDP socket為什么不能多次bind不同的埠, UDP本身就是無狀態無連接的,它想發資料的時候,隨時抓一個和其它五元組不沖突的埠使用即可,但事實上在一個UDP socket的生命周期內,它的源埠是不會變的,這看起來對UDP施加了更緊的約束,我覺得這是不合理的,這種約束也太不UDP了,
我們看下面的代碼:
#!/usr/bin/python3
import socket
#import sys
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
server_address = ('192.168.56.101', 1234)
message = str.encode('aaaaaaaaaaaaaaaaaaaaa')
sport = 4321
while True:
sent = sock.sendto(message, server_address)
sock.bind(('192.168.56.102', sport))
sport = sport + 1
當你執行的時候,你會得到下面的報錯:
Traceback (most recent call last):
File "./udpsender.py", line 14, in <module>
sock.bind(('192.168.56.102', sport))
OSError: [Errno 22] Invalid argument
至少在Linux上是這樣的,
這是因為Linux禁止double bind:
int __inet_bind(struct sock *sk, struct sockaddr *uaddr, int addr_len,
bool force_bind_address_no_port, bool with_lock)
{
...
/* Check these errors (active socket, double bind). */
err = -EINVAL;
if (sk->sk_state != TCP_CLOSE || inet->inet_num)
goto out_release_sock;
...
}
OK,既然我這么篤信這是不合理的,改了它便是了,執行下面的腳本:
#!/usr/bin/stap -g
%{
#include <net/inet_sock.h>
%}
function alter(ssk:long)
%{
struct sock *sk = (struct sock *)STAP_ARG_ssk;
struct inet_sock *inet = inet_sk(sk);
sk->sk_prot->unhash(sk);
inet->inet_num = 0;
%}
probe kernel.function("__inet_bind")
{
alter($sk);
}
現在再來執行上面的python腳本試試看,
我們主要應該關注的是如果UDP socket每次發包都換一個不同的源埠,這將會在短時間內創造大量的五元組,這個事實會影響運營商的決策,
傳統的狀態防火墻,狀態NAT會用一個 五元組 來追蹤一條 連接 ,如果連接過多,就會對這些保存狀態的設備造成很大的壓力,這種壓力主要體現在兩個方面:
- 存盤壓力:設備不得不配置大量的記憶體來保存大量的連接,
- 處理器壓力:設備不得不在資料包到來的時候花更多的時間來匹配到一條連接,
由于UDP的無狀態特征,沒有任何報文指示一條連接什么時候該創建什么時候該銷毀,設備必須有能力自行老化已經創建的UDP連接,且不得不在權衡中作出抉擇:
- 如果老化時間過短,將會破壞正常通信但通信頻率很低的UDP連接,
- 如果老化時間過長,將會導致已經無效的UDP連接消耗大量的記憶體,這將為DDoS攻擊創造一個攻擊面,
攻擊者只需要用不同的UDP五元組構造報文使其經過狀態設備即可,由于UDP報文沒有任何指示連接創建銷毀的控制資訊,狀態設備不得不平等對待任何新來的五元組,即為它們創建連接,并且指定相同的老化時間,TCP與此完全不同,由于存在syn,fin,rst等控制資訊,狀態設備便可以針對不同狀態的TCP連接指定不同的老化時間,ESTABLISHED狀態的連接顯然要比其它狀態的連接老化時間長得多,
這導致使用TCP來實施同樣的攻擊會困難很多,
為什么,為什么快速構造不同的TCP五元組達不到UDP同樣的效果?
- 如果你只是盲目的用不同源埠發送syn,在沒有真正的對端回應的情況下,這種狀態的連接將會很快老化掉(10秒以內,甚至更短),
- 如果你構造使用不同埠的大量真正的TCP連接,那么在狀態設備受到傷害的同時,你自己也必須付出巨大的代價來維持住這些連接,
- …
你發起一個TCP連接,為了讓狀態設備保存這條連接,你自己也不得不保存這條連接,除非你通過海量的反射主機同時發起真連接,否則在單臺甚至少量的主機上,這種攻擊很難奏效,
辦法也不是沒有,如果你能在三次握手成功創建連接后迅速關掉它們,同時阻止任何rst,fin報文的發出,攻擊可能會簡單一些,
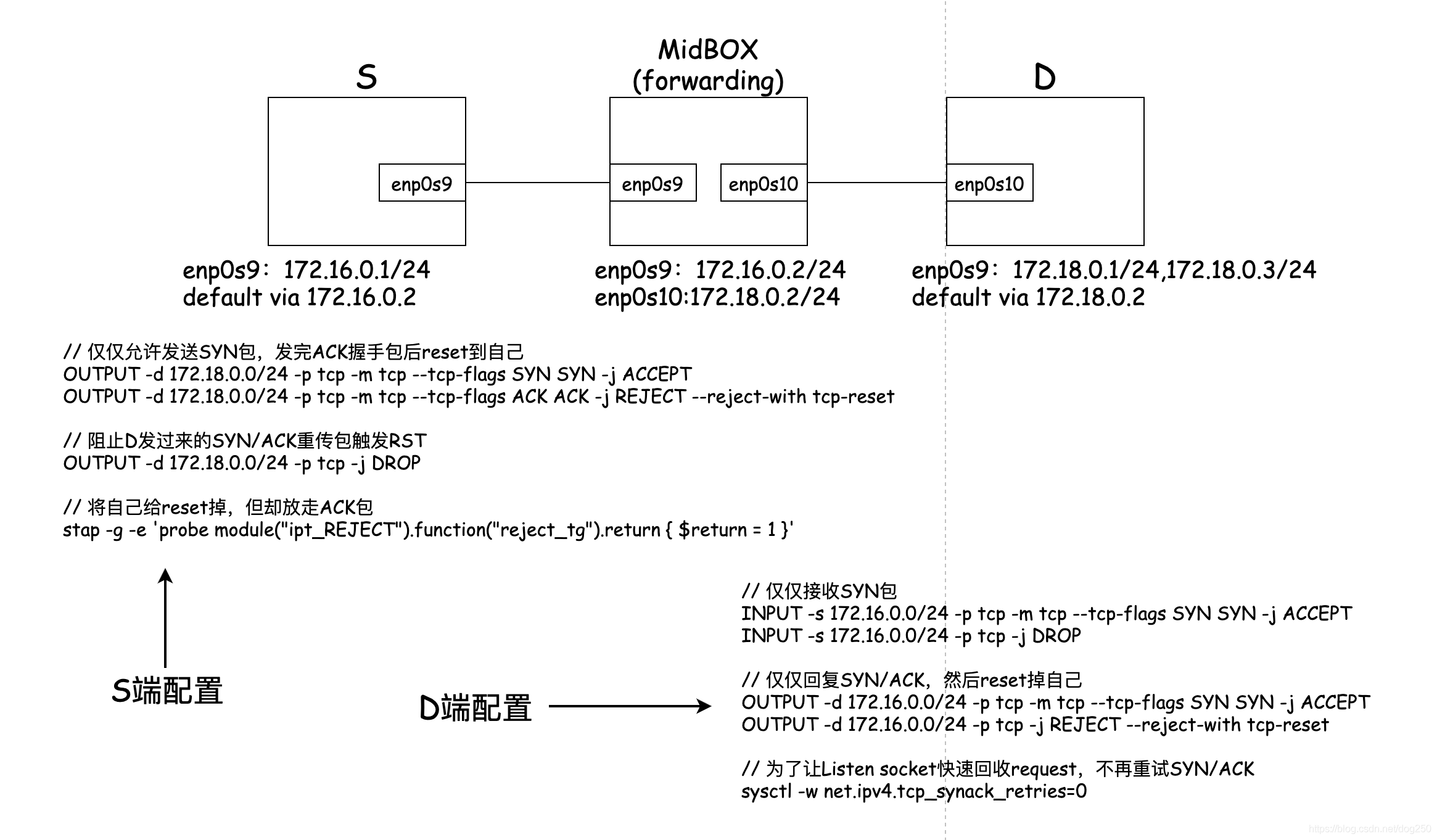
在S上執行下面的命令:
while true; do telnet 172.18.0.1 22;done
刷一波之后,在Midbox上查看conntrack條目:
# conntrack -L -p tcp src 172.16.0.1|grep ESTABLISHED |wc -l
conntrack v1.4.5 (conntrack-tools): 14118 flow entries have been shown.
14117
而此時,S和D上均早已經看不見任何連接了:
# netstat -antp|grep 172.16.0.1 |wc -l
0
此外,不通過協議堆疊,構造raw報文來進行TCP握手進行攻擊,本地不保存任何TCP連接資訊顯然是一種 更佳 的方法,因為我懶得去寫那么多代碼,也不想折騰scapy這種東西,就只能用上述iptables/stap的方式模擬了,
然而無論怎樣,TCP做類似的攻擊依然達不到UDP快速構建連接損害狀態設備的效果,至少效率損失個3倍(需要三次握手)起跳吧,
好了,結束對狀態設備的討論,現在問題又來了,如果是非狀態設備呢?
既然是無狀態設備,我們便不必再糾結五元組連接的保持了,但是UDP短期構造海量五元組的能力仍然會影響無狀態設備包分類演算法的正常運行,基于包分類演算法的優先級佇列,快取管理幾乎也是通過五元組計算來完成的,UDP的特征將會使無狀態設備對其做流量管控變得困難,其結果就是,眼睜睜任憑UDP流量擠滿各級佇列快取卻沒有辦法將其精確識別出來,即便是BBR遇到了UDP流量,也只能自降pacing rate而興嘆,在它看來,瓶頸帶寬是真的減小了,運營商設備本應該做的更多,然而它卻無能為力,
運營商(特別是國內運營商)顯然沒有能力和精力根據TCP和UDP的不同去深度定制不同的QoS策略,一刀切顯然是最便捷的手段,
當然,國內運營商的帶寬套餐超賣可能會導致下面的事情的發生(本人從不同非技術渠道獲知,用技術手段確認):
- 自然月月初,為了給套餐用戶極佳的體驗,會在高峰期對幾乎所有UDP流量進行限制,包括丟包,低優先級佇列,限速等等,
- 自然月月末,很多套餐用戶流量已經超限,會適當放開對UDP流量的管制來實作自然限速,
這就是我為什么總是提倡 “在自然月月初的時候把你的UDP流量的UDP頭換成TCP頭,接收端再換回來” 的原因,
當我說這個話的時候,我聽到過兩種意思截然相反的反對聲音:
- 運營商的設備根本不會去檢測每一個報文到底是TCP還是UDP,更不會做深度包決議,這會嚴重影響性能,所以換頭這個方法幾乎沒用,
- 運營商的設備會檢查每一個經過的報文,很容易發現你這個假的TCP頭,這么做更容易導致你的報文被丟棄,所以換頭這個方法幾乎沒用,
我不知道這些人出于什么目的,我和他們并不熟識,只是單純的討論技術而已,在我要求他們給出理論分析或者至少給出測驗資料的時候,他們便再也不回復了,我不知道他們是出于什么心態處處反駁,大概是為了彰顯一下自己?不得而知,為了懟而懟沒有意義,還是要親自試一下,
當我需要親自試一下的時候,又有人出來懟了,大概是說,即便真的要這么做,何必換頭,直接修改掉IP頭的protocol欄位即可,很多人煞有其事地告訴我,直接改個欄位就行:
...
if (iph->protocol == IPPROTO_TCP) {
iph->protocol = IPPROTO_UDP;
ip_send_check(iph);
udph->check = 0;
} else if (iph->protocol == IPPROTO_UDP) {
iph->protocol = IPPROTO_TCP;
ip_send_check(iph);
}
我敢保證他們絕對沒有真的試過,因為當你真正去這么嘗試的時候,就會發現,丟包率大大增加了,甚至根本無法通信!這個事實難道沒有從反面證明換頭操作會影響運營商的QoS策略嗎?
下面是我測驗這種情況的一個代碼片段,它是一個udpping程式,每次發給對端一個隨機的字串,等待對端echo回來,首先在對端部署僅僅修改IP頭protocol欄位的邏輯,并且執行socat:
socat -v UDP-LISTEN:4321,fork PIPE
發送端同樣部署上述的IP頭換protocol欄位的邏輯,執行發送的代碼片段如下:
while True:
payload= random_string(20)
sock.sendto(payload.encode(), (IP, PORT))
...
recv_data,addr = sock.recvfrom(65536)
if addr[0]==IP and addr[1]==PORT:
rtt=((time.time()-time_of_send)*1000)
print("Reply from",IP,"seq=%d"%count, "time=%.2f"%(rtt),"ms")
...
很遺憾,結果如下:
# 地址和rtt為偽造,真實測驗鏈路為上海到日本,
Reply from 123.123.123.123 seq=97 time=25.41 ms
Request timed out
Request timed out
Request timed out
Reply from 123.123.123.123 seq=101 time=25.41 ms
Request timed out
Reply from 123.123.123.123 seq=103 time=25.44 ms
Reply from 123.123.123.123 seq=104 time=25.39 ms
Request timed out
Request timed out
Request timed out
Reply from 123.123.123.123 seq=108 time=25.40 ms
Reply from 123.123.123.123 seq=109 time=25.43 ms
由于發包程式發送的是random字串,它們將會被決議成TCP頭超過UDP頭大小的部分,抓包可以一窺究竟,它可以分別被決議成下面的樣子:
IP (tos 0x20, ttl 64, id 60168, offset 0, flags [DF], proto TCP (6), length 128)
111.111.111.111.1234 > 123.123.123.123.4321: Flags [FSRPUE], cksum 0x5651 (incorrect -> 0x1bba), seq 7108832:7108912, win 17975, urg 19510, options [[bad opt]
...
IP (tos 0x20, ttl 64, id 60969, offset 0, flags [DF], proto TCP (6), length 128)
111.111.111.111.1234 > 123.123.123.123.4321: tcp 96 [bad hdr length 12 - too short, < 20]
...
IP (tos 0x20, ttl 64, id 63113, offset 0, flags [DF], proto TCP (6), length 128)
111.111.111.111.1234 > 123.123.123.123.4321: Flags [RE], cksum 0x5430 (incorrect -> 0x8e6e), seq 7108832:7108920, win 20022, length 88 [RST+ lCufDCd5oRmJCW02dV6coRDKCGVmJc]
嗯,結果大概就是這個樣子,
僅僅修改IP頭的protocol欄位,僅僅將TCP修改成UDP為什么不行?
因為運營商狀態設備確實會檢查TCP報文中的syn,ack,fin,rst等標志(否則它們如何創建連接呢?),如果狀態設備確實檢查了這些標志,那么它就會在內部維護一個TCP連接的狀態機,至少大概是這樣,如果你的TCP報文序列嚴重違反了TCP狀態機,結果可想而知,
如果只是設定了syn而沒有設定ack,并且這個偽造的TCP報文還攜帶資料,在我的測驗環境中則是被100%丟棄,
如果你只是修改了IP頭的protocol欄位,比方說改成了TCP,那么運營商設備就會將后面的UDP頭決議成TCP頭,由于UDP頭只有8個位元組,而TCP頭的flag欄位在8位元組以外,因此運營商設備會將UDP的payload決議成TCP頭的flag欄位,而UDP payload幾乎可以是任意的,
感謝TCP頭和UDP頭的前兩個欄位是一致的!
因此,如果要執行UDP頭換TCP頭的操作,并不是如那些信口開河之人想象的那樣簡單的,至少我測驗下來,需要做的是:
- 不要帶syn標志,因為運營商設備可能會檢查syn標志和payload的互斥性(即不允許fastopen),
- 保持一個單調遞增的的Seq Number以及一個單調遞增的Ack Number,
- 沒有必要非要發送偽造的syn和syn/ack,這個類似Linux nf_conntrack的nf_conntrack_tcp_loose配置,網路允許路由的不對稱,因此loose是寬松的,
下面的代碼片段將UDP換成TCP頭,為了不妨礙Netfilter深度檢測報文,這個代碼要在POSTROUTING的最后執行:
struct iphdr *iph = ip_hdr(skb), ihdr;
struct dst_entry *dst = NULL;
static unsigned int seq = 1239876;
static unsigned int ack_seq = 2345;
udph = (struct udphdr *)start;
ihdr = *iph;
uhdr = *udph;
if (iph->protocol != IPPROTO_UDP)
goto out;
ihdr.protocol = IPPROTO_TCP;
oldlen = ntohs(ihdr.tot_len);
ihdr.tot_len = htons(oldlen + delta);
if ((dst = skb_dst(skb)) == NULL)
goto out;
// 假TCP不支持TSO/GSO,因此由于新增了12位元組的TCP和UDP頭長差之后超過MTU的包不予換頭,
if (oldlen + delta + LL_RESERVED_SPACE(dst->dev) > dst_mtu(dst))
goto out;
if (pskb_expand_head(skb, delta, 0, GFP_ATOMIC))
goto out;
iph = (struct iphdr *)skb_push(skb, delta);
*iph = ihdr;
skb_reset_network_header(skb);
skb_set_transport_header(skb, iph->ihl*4);
ip_send_check(iph);
tcph = (struct tcphdr *)skb_transport_header(skb);
tcph->source = uhdr.source;
tcph->dest = uhdr.dest;
tcph->seq = htonl(seq);
seq += 1000;
tcph->ack_seq = ack_seq;
tcph->syn = 0;
tcph->doff = 5;
tcph->ack = 1;
tcph->urg = 1;
tcph->rst = 0;
tcph->fin = 0;
tcph->window = htons(1000);
// 無需計算TCP校驗和,因為我會在接收端將它換回UDP并且取消校驗和檢查,以實作真正的盡力而為的弱校驗,
將UDP頭換成TCP頭之后,在另一端,我們需要執行相反的操作,將偽造的假TCP頭再換回UDP,這個要更容易些,至少不需要expand_head了,
下面的代碼在PREROUTING的raw之后conntrack之前執行,這是因為需要在iptables的raw表中對需要轉換的資料包進行識別,并且要保證恢復UDP頭之后不影響后續可能存在的nf_conntrack操作:
struct iphdr *iph = ip_hdr(skb), ihdr;
struct dst_entry *dst = NULL;
udph = (struct udphdr *)start;
ihdr = *iph;
uhdr = *udph;
if (iph->protocol != IPPROTO_TCP)
goto out;
ihdr.protocol = IPPROTO_UDP;
oldlen = ntohs(ihdr.tot_len);
ihdr.tot_len = htons(oldlen - delta);
iph = (struct iphdr *)skb_pull(skb, delta);
*iph = ihdr;
skb_reset_network_header(skb);
skb_set_transport_header(skb, iph->ihl*4);
ip_send_check(iph);
udph = (struct udphdr *)skb_transport_header(skb);
udph->source = thdr.source;
udph->dest = thdr.dest;
udph->len = htons(ntohs(iph->tot_len) - sizeof(struct iphdr));
// 取消校驗和,補償下換頭操作帶來的額外延遲,
udph->check = 0;
下面是一個iperf測驗中換頭功能切換前后的抓包效果:
23:37:25.951045 IP 192.168.56.101.1234 > 192.168.56.102.4321: UDP, length 1000
23:37:25.957493 IP 192.168.56.101.1234 > 192.168.56.102.4321: UDP, length 1000
23:37:25.968388 IP 192.168.56.101.1234 > 192.168.56.102.4321: UDP, length 1000
23:37:25.973226 IP 192.168.56.101.1234 > 192.168.56.102.4321: UDP, length 1000
23:37:25.988933 IP 192.168.56.101.1234 > 192.168.56.102.4321: UDP, length 1000
23:37:25.988933 IP 192.168.56.101.1234 > 192.168.56.102.4321: UDP, length 1000
23:37:26.009427 IP 192.168.56.102.4321 > 192.168.56.101.1234: UDP, length 1000
23:39:03.572431 IP 192.168.56.101.1234 > 192.168.56.102.4321: Flags [.UEW], seq 8934678:8935678, ack 3458334720, win 1000, urg 43727, length 1000
23:39:03.580616 IP 192.168.56.101.1234 > 192.168.56.102.4321: Flags [.UEW], seq 1000:2000, ack 1, win 1000, urg 35592, length 1000
23:39:03.587336 IP 192.168.56.101.1234 > 192.168.56.102.4321: Flags [.UEW], seq 2000:3000, ack 1, win 1000, urg 28841, length 1000
23:39:03.597182 IP 192.168.56.101.1234 > 192.168.56.102.4321: Flags [.UEW], seq 3000:4000, ack 1, win 1000, urg 19029, length 1000
23:39:03.603321 IP 192.168.56.101.1234 > 192.168.56.102.4321: Flags [.UEW], seq 4000:5000, ack 1, win 1000, urg 12785, length 1000
23:39:03.610564 IP 192.168.56.101.1234 > 192.168.56.102.4321: Flags [.UEW], seq 5000:6000, ack 1, win 1000, urg 5600, length 1000
23:39:03.618043 IP 192.168.56.101.1234 > 192.168.56.102.4321: Flags [.UEW], seq 6000:7000, ack 1, win 1000, urg 63666, length 1000
好漂亮的序列,
關于重算IP頭校驗和的問題,很多人是很反感,總覺得這里會增加額外的處理延時,實際上這種校驗和計算開銷是可以忽略不計的,
校驗和是一種非常弱的校驗演算法,它本質上就是就是將資料序列按照16bits拆分,然后將這些16bits資料加到一起,從這個基本原理可以看出,用 加法交換律 很容易實作 修改資料而不改變校驗和 以及 校驗和增量重新計算 ,
下面的代碼展示了通過修改IP頭的id欄位來彌補protocol欄位和tot_len欄位的的改變從而不改變原始的校驗和:
unsigned short old1 = *(unsigned short *)&iph->ttl; // ttl和protocol合體作為16bits參與計算
unsigned short old2 = *(unsigned short *)&iph->tot_len; // 換頭后總長會改變
unsigned short *pID;
...// 修改protocol和總長
pID = (unsigned short *)&iph->id;
*pID -= *(unsigned *)&iph->ttl - old1;
*pID -= *(unsigned *)&iph->tot_len - old2;
我個人傾向于采用同時修改IPID和原始IP校驗和的方式,因為這樣可以應對中間設備對IPID的分布進行掃描:
- 同一臺主機發出報文的IPID欄位呈現偽遞增趨勢,
- 如果同一個源IP的IPID是亂序的,中間設備會認為這是被NAT的不同主機發出的,進而可能給出不同的排隊優先級,
下面的代碼實作了校驗和的增量計算:
unsigned short old1 = *(unsigned short *)&iph->ttl; // ttl和protocol合體作為16bits參與計算
unsigned short old2 = *(unsigned short *)&iph->tot_len; // 換頭后總長會改變
... // 修改protocol和總長
iph->check = ~iph->check + *(unsigned *)&iph->ttl - old1 + *(unsigned *)&iph->tot_len - old2;
iph->check = ~iph->check;
其實,由于IP頭本身就很小,一共才10個bits,因此即便是重新全部計算一遍也不會有多大開銷,而諸如TCP,UDP這種連帶載荷一起計算的校驗和才能算得上開銷,慢載MSS的報文差不多需要700多次的計算,因此一般比如在做了NAT之后需要對TCP/UDP重新計算校驗和的時候,會用增量計算,只計算改變的量,而IP頭的校驗和,無所謂咯,
TCP校驗和太弱了,以至于我們完全不可信任它,交換payload的兩個16bits不會影響檢驗和的正確性,因此在我們下載檔案的時候,一般會順手下載一個MD5檔案用來自行校驗,
有點跑題,OK,言歸正傳,
我在公網上進行了測驗,同樣的上海到日本的鏈路,換頭操作之后丟包率小幅降低但不是很明顯,等哪天我找一條國內的鏈路在流量高峰期測驗一把再看效果,
行文至此,可以看到,首先,運營商真的會根據UDP和TCP標志做區分對待,其次,UDP頭換成TCP頭傳輸在技術上是可行的,現在,我想最后聊一下這種技術適合做什么,不能做什么,
顯然,TCP換頭有個前提,你必須能控制兩端,換句話說這是一個雙邊操作,這和IP/GRE/TCP/UDP/VXX等隧道技術非常相似,簡直就是同一類東西,當你可以控制兩端時,你才有能力去搭建一條隧道,那么隧道里封裝什么呢?
在我看來,任何東西都可以封裝在這個偽造的假TCP隧道里,當然,包括皮鞋和真絲的領帶,
現在,讓我們忽略隧道的概念,我可以把遇到的任意UDP頭換成TCP頭嗎?比如DNS的流量?
當然可以!并且我建議你這么做!只要你能卡住該UDP流量必經路徑上的兩個點,你就可以在這兩個點之間將UDP頭換成TCP頭,我的理由如下:
- 不要誤會,我的TCP不會帶來任何TCP意義上的開銷,不保存連接,無重傳,不保序,這是個假的TCP,只是一個TCP頭罷了,
- 本來UDP就是盡力而為的,換成偽造的假TCP并不會讓事情變得更糟糕,
- 運營商對TCP更加友好,對UDP不友好,但卻無力深度檢測TCP連接的真實性,
zhengjiang wenzhou skinshoe wet,down rain enter water not can fat.
浙江溫州皮鞋濕,下雨進水不會胖,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/257484.html
標籤:其他
上一篇:leetcode上關于單向鏈表的《反轉鏈表》求解步驟及思路(C語言)
下一篇:Javascript初學者筆記篇