C# 訪問網頁并對頁面上的元素進行抓取
//
HttpWebRequest request=HttpWebRequest.Create(“URL”) AS HttpWebRequest;
//設定訪問頁面的標頭
request.Method = “get”;//通過get方式訪問
//在需訪問的頁面F12,Network下的Headers中可以查看
request.Accept = “”;
request.ContentType = “”;
request.UserAgent = “”;
HttpWebResponse response = request.GetResponse() as HttpWebResponse;
StreamReader steamReader=new SteamReader(response.GetResponseStream());
//如果請求下來的頁面是zip格式
Stream ResStream = new System.IO.Compression.GZipStream(response.GetResponseStream(), System.IO.Compression.CompressionMode.Decompress);
Encoding encoding = Encoding.GetEncoding(“utf-8”);
StreamReader streamReader = new StreamReader(ResStream, encoding);
//請求下來的HTML頁面
String data=stream.ReadToEnd();
//以攜程網主頁房間數為例
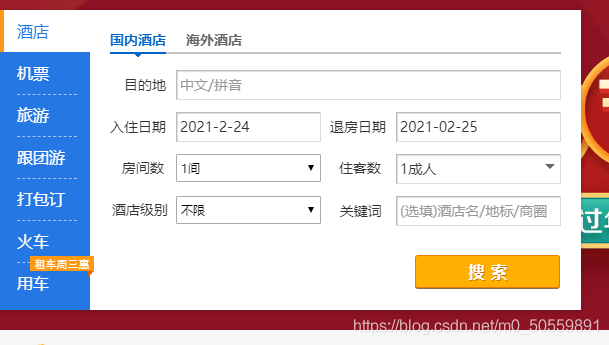
Hashtable hashtable = new Hashtable();// 網頁中元素物件
var htmlDoc = new HtmlAgilityPack.HtmlDocument();
htmlDoc.LoadHtml(data);//決議
HtmlNode token = htmlDoc.DocumentNode.SelectSingleNode(Xpath);
List<String> li = new List<string>();
//遍歷其中符合條件的資料
foreach (HtmlNode row in token.SelectNodes("option"))
{
li.Add(row.InnerHtml);
}
String aa=string.Empty;
for (int i=0;i<li.Count;i++) {
aa += li[i]+ "\r\n";
}
//顯示爬取下來的資料aa

轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/263461.html
標籤:其他