前言
我們在對比字串時若發現有一個字符不滿足,則從下一個字符重新匹配,挨個遍歷的演算法是一種低效的,于是三位前輩,D.E.Kunth, J.H.Morris, V.R.Pratt發表樂一個模式匹配演算法,可以大大避免重復遍歷的情況,我們把它稱之為克努特——莫里斯——普拉斯演算法,簡稱KMP演算法,
一、KMP模式匹配演算法原理
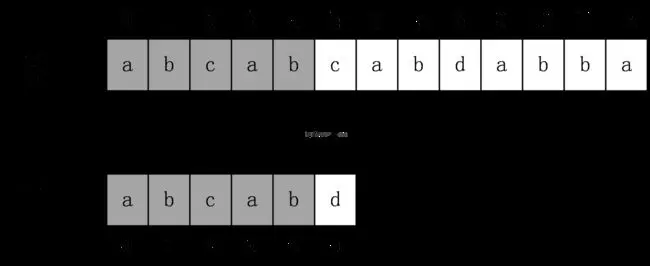
我們不直接講代碼,我們先理解一下他為什么比樸素演算法好,按照我們上面說的樸素演算法進行匹配,此時前五個字母,兩個串完全相等,直到第六個字母,c和d不相等,接下來按照樸素演算法應該從第一個串的第二個對比,不相等,再到第三個對比,直到第四個字母a和下面串的a相等,這樣從主串一步步移動,似乎沒什么問題,但是我們仔細觀察發現字串a與他后面的b,c都不相同,而在我們第一次匹配時,主串的前五位和子串的前五位相同,那么字串的a肯定和主串二三位置的b,c不等,所以我們將主串移動到第二個位置,和第三個位置的操作是多余的,所以我們應該直接忽略這兩個操作,直接將主串挪到第四個位置a的位置開始進行匹配,從這里我們可以分析得到在字串對比中有些回溯是可以不用發生的——所謂好馬不吃回頭草,我們的kmp演算法就是為了讓不必要的回溯不發生而誕生的,
二、KMP演算法的具體操作
1.回溯的步數
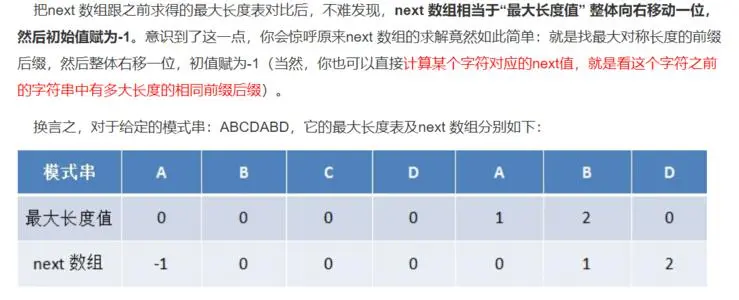
上文我們提到了若兩個字符不相等時,主串會回溯,我們的KMP演算法可以不讓主串進行回溯,我們是通過移動子串繼續匹配的,如上圖所示,我們利用kmp演算法可以將字串移到主串的第四個位置進行比對,假設字串的位置由j表示,此時我們也就是移到了j = 3的位置繼續和主串的“c”進行比較,既然我們是移動子串,那么這個回溯步數就和子串有特定的聯系,這里引入一個概念,字串的前后綴,例如“abc”,它的前綴有“a“,”ab“,后綴有”c”,“bc”,我們回溯的步數是根據字串的前后綴相似度,也就是最長相等前后綴,例如“abcabd”我們的j = 6(j為字串的字母位置)時,發現d與主串的c不等,需要移動,這個最長前后綴是在d之前的“abcab”中尋找的,我們可以很容易得到最長前后綴為“ab”,所以我們移到了j = 3的位置,也就是str【2】,綜上我們每一個位置的字母都有一個回溯的步數,這里我們引入KMP演算法中的next陣列:
next陣列是一個我們存回溯步數的陣列,規則為第一個字母存-1,有相同前后綴的存前后綴的大小,其余存0;
c語言實作代碼如下:
void GetNext(str t,int next[]) {
int j = 0, k = 1;
next[0] = -1; //令第一個為-1
while (j < t->length - 1) {
if (k==-1 || t->data[j] == t->data[k]) {
j++;
k++;
next[j] = k;
} else {
k = next[k]; 不等時回溯
}
}
}
2.KMP演算法函式代碼:
代碼如下所示:
int KMPIndex(str s, str t) {
int next[MaxSize], i = 0, j = 0;
GetNext(t, next);
while (i < s->length && j < t->length) {
if (j == -1 || s->data[i] == t->data[j]) {
i++;
j++;
} else {
j=next[j]; //不相等時根據next陣列回溯
}
}
if (j >= t->length) {
return(i - t->length); //若字串在主串中,回傳字串在主串中的第一個位置,
} else {
return(-1); //若字串不存在,則回傳—1;
}
}
總結
kmp演算法適用與處理子串重復出現一些字母的情況,我們在處理這類問題時可以嘗試使用kmp演算法,初學kmp,有許多不足的地方,還請大家多多包涵,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/277685.html
標籤:其他
上一篇:Notification——HTML5桌面通知彈窗(你用過嗎?點擊測驗地址體驗一下吧)
下一篇:CSS布局—溢位(清晰易懂)