最近在學習爬蟲,
大麥網搜索引擎頁面:
https://search.damai.cn/search.htm,我想采集各演出節目的相關資訊,做資料分析。
但是,該頁面的主要內容(如下圖所示),標題、演員、地點、時間等,均無法在源代碼中找到。
請教各位:這是用了什么技巧?爬蟲應當怎么做?其他的隱藏手段及解決辦法給個思路,謝謝!
uj5u.com熱心網友回復:
啥技巧沒用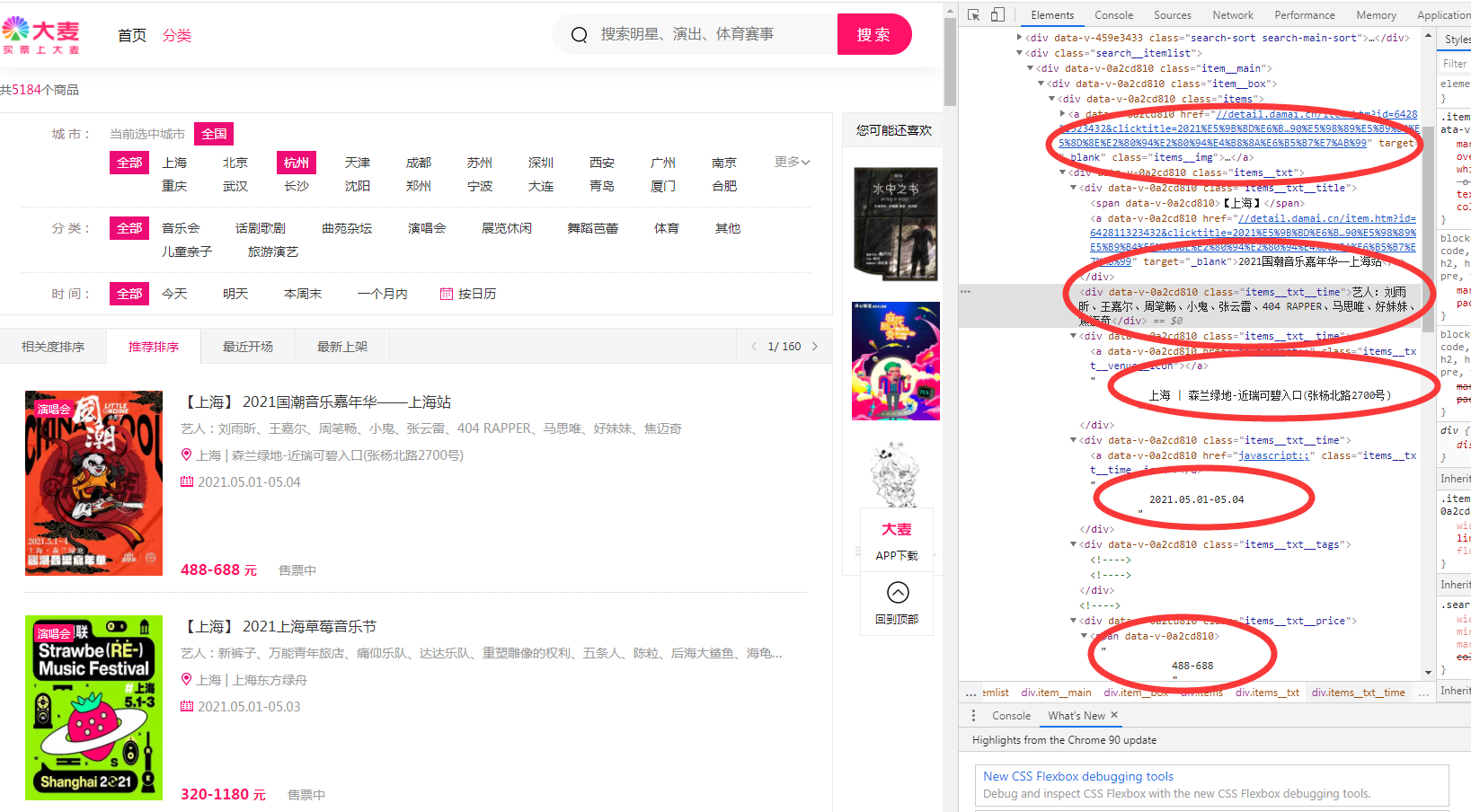
uj5u.com熱心網友回復:
看介面請求,資料都在介面里面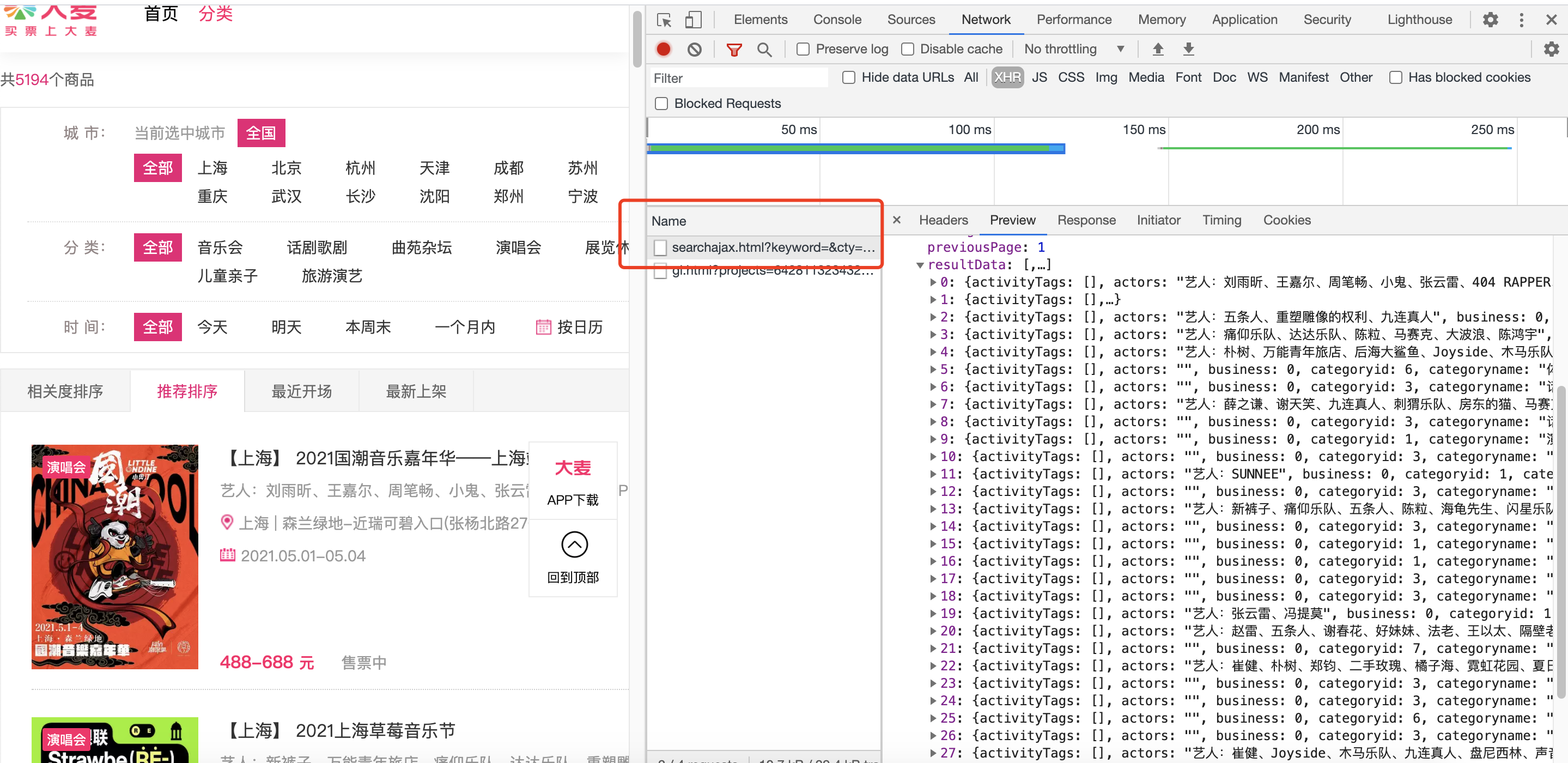
uj5u.com熱心網友回復:
非常感謝熱心人的幫助!詳細審慎地查看了兩位答復,感徑訓有些疑惑。為什么用“查看源代碼”復制粘貼過來的搜索不到“標題、演員、地點、時間”等內容?uj5u.com熱心網友回復:
api回傳的東西怎么會在源代碼上面...uj5u.com熱心網友回復:
什么意思?我是在chrome中右鍵“查看源代碼”的
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/280468.html
標籤:HTML(CSS)