文章目錄
- 鄰接矩陣存盤圖的廣度優先遍歷程序分析
- C語言實作佇列編程
- 程式中加入圖的處理函式
- 結果的再次分析
- C#語言實作圖的廣度優先遍歷、并顯示廣度優先遍歷生成樹
- JavaScript語言實作圖的廣度優先遍歷、并顯示廣度優先遍歷生成樹
鄰接矩陣存盤圖的廣度優先遍歷程序分析
對圖1這樣的無向圖,要寫成鄰接矩陣,則就是下面的式子
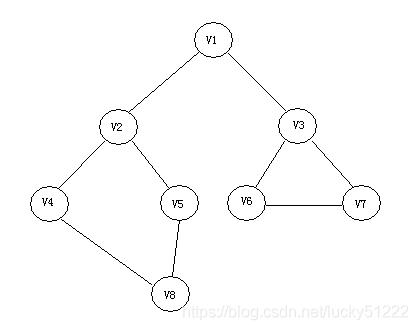
 一般要計算這樣的問題,畫成表格來處理是相當方便的事情,實際中計算機處理問題,也根本不知道所謂矩陣是什么,所以畫成表格很容易幫助我們完成后面的編程任務,在我們前面介紹的內容中,有不少是借助著表格完成計算任務的,如Huffman樹,
一般要計算這樣的問題,畫成表格來處理是相當方便的事情,實際中計算機處理問題,也根本不知道所謂矩陣是什么,所以畫成表格很容易幫助我們完成后面的編程任務,在我們前面介紹的內容中,有不少是借助著表格完成計算任務的,如Huffman樹,
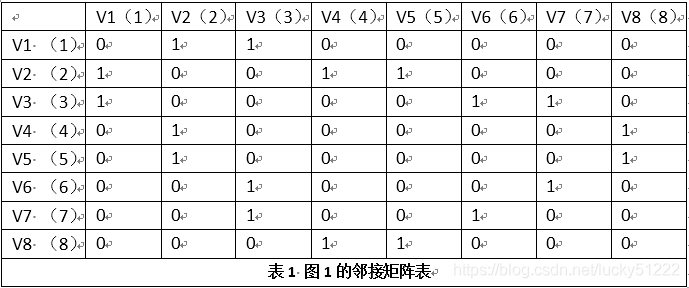
為了記錄那些頂點是已經走過的,還要設計一個表來標記已經走過的頂點,在開始,我們假設未走過的是0,走過的是1,于是有:

對廣度優先遍歷,還需要補充一個佇列、來記錄一個頂點可以抵達到的其他頂點,
廣度優先遍歷程序如下:
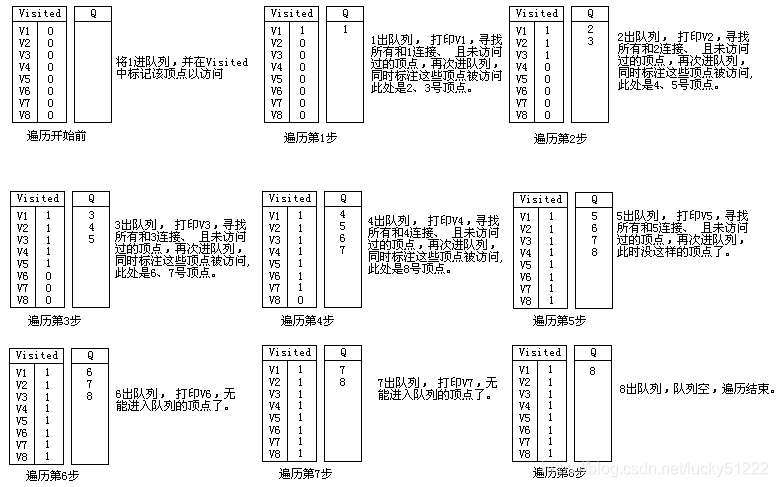
結果分析
從上面的程序可以看出:僅僅就頂點訪問到的次序而言,圖1的廣度優先遍歷結果是:
V1->V2->V3>V4->V5->V6->7->V8
但實際執行程序中我們可以發現:所謂圖的廣度優先遍歷、其結果應該是一個樹:
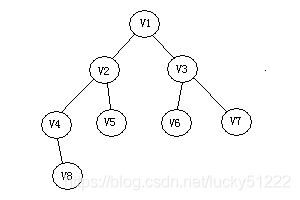
在C語言中,顯示這個結果并不容易,所以大多C語言的教材中并不會給出這樣的結果,
C語言實作佇列編程
根據上面的分析,我們可以知道:要廣度優先遍歷圖,首先要一個佇列系統,
佇列在C語言上只能自己構造,好在我們前面有鏈表、有順序表,我們可以復制過來一個鏈表程式構造一個佇列,于是從鏈表程式中復制過來b5.c或者b6.c即可,我們分析佇列的ADT可知,最需要的佇列功能需求是:
QueueInit()、EnQueue、DeQueue()、QueueEmpty()這4個函式,于是有以下佇列定義:
struct Queue
{
struct LinkedList * LinkQueue;
int Count;
};
由于我們已經確定使用鏈表做佇列,所以佇列實際就是鏈表的換名包裝,所以我們可以理解為佇列就是鏈表的另一種應用,表3的程式就是這樣的做法,所以對佇列的初始化,就是:
struct Queue * QueueInit()
{
struct Queue *q;
q=(struct Queue *)malloc(sizeof(struct Queue));
q->LinkQueue=LinkedListInit();
q->Count=0;
return q;
}
有了佇列的初始化,則進入佇列、實際相當于給這個鏈表追加一條記錄,就是Append()的另類包裝:
int EnQueue(struct Queue *Q,struct ElemType *E)
{
if(Q==NULL) return -1;
if(E==NULL) return -2;
Append(Q->LinkQueue,E);
Q->Count++;
return 0;
}
注意資料出佇列,出佇列總是把鏈表中第一個結點的資料給出來、并洗掉第一個結點,所以出佇列就是:
int DeQueue(struct Queue *Q,struct ElemType *E)
{
struct ElemType *pE;
if(Q==NULL) return -1;
if(E==NULL) return -2;
pE=LinkedListGet(Q->LinkQueue,1);
ElemCopy(pE,E);
LinkedListDel(Q->LinkQueue,1);
Q->Count--;
return 0;
}
出佇列函式總是把第一個結點洗掉掉,注意佇列完全可能資料出完后再次有資料進入佇列,則原來的結點洗掉函式有Bug,這在程式開發中很正常,修改后就是:
int LinkedListDel(struct LinkedList *L,int n)
{
int i;
struct Node *p0,*p1;
if(L==NULL) return -1;
if(n<0||n>L->Count) return -2;
p0=L->Head;
for(i=0;i<n-1;i++)
p0=p0->next;
p1=p0->next;
p0->next=p1->next;
free(p1);
L->Count--;
if(L->Count==0) L->Tail=L->Head;
return 0;
}
修改的這個鏈表結點函式、僅僅加了第14行,在過去,所以結點洗掉后,最后的尾巴結點指標Tail所指的存盤空間被釋放,導致這個指標變數不可用,現在在結點個數為0的情況下,再次讓尾結點指向頭結點,保證下次進入鏈表的資料依然正確,
而判斷佇列是否為空則相對簡單的多,就是:
int QueueEmpty(struct Queue *Q)
{
if(Q==NULL) return -1;
return !(Q->Count);
}
補充main()函式,測驗多批次進入佇列、出佇列,全部程式見B0.c
在我們的圖遍歷應用中,我們對佇列的資料僅僅要求一個整數即可,而這個程式進出佇列的資料有三列資料,為加強該程式可靠行,修改ElemType(),就是:
void ElemCopy(struct ElemType *s,struct ElemType *d)
{
d->sNo=s->sNo;
//strcpy(d->sName,s->sName);
//d->sAge=s->sAge;
}
在一個系統中,類似這樣的修改很正常,使用已有的程式完成自己的作業,會大大加快編程的進度,使得編程作業更加流暢,
而這一切都需要自己有足夠的積累,有這個積累后完成這樣的作業才有基礎,所謂技術水平,就是不斷積累的程序,
下面,在圖的處理中會再次體現這樣的程序,
程式中加入圖的處理函式
我們的佇列系統完成后,記著再復制一個檔案,加入圖的鄰接矩陣讀資料程式,我們這里這個程式名稱是b1.c,對鄰接矩陣資料的讀取、并構造圖的程序,在深度優先遍歷程式中已完成,所以直接復制過來即可,回顧廣度優先遍歷演算法,就是把第一個頂點先無條件裝進佇列,所以撰寫遍歷BFSM函式如下:
四、程式中加入圖的處理函式
我們的佇列系統完成后,記著再復制一個檔案,加入圖的鄰接矩陣讀資料程式,我們這里這個程式名稱是b1.c,對鄰接矩陣資料的讀取、并構造圖的程序,在深度優先遍歷程式中已完成,所以直接復制過來即可,回顧廣度優先遍歷演算法,就是把第一個頂點先無條件裝進佇列,所以撰寫遍歷BFSM函式如下:
void BFSM(struct Graph *G)
{
int i,n;
struct Queue *Q;
struct ElemType *p,E,e;
Q=QueueInit();
E.sNo=0; // 設定0進佇列
EnQueue(Q,&E);
G->Visited[0]=1; // 設定0號頂點已被訪問
p=&e;
while(!QueueEmpty(Q))
{
//待補充
}
}
從第11行開始,則進入真正的遍歷,
有這么個函式后,我們可以補充main()的測驗函式就是:
main()
{
struct Graph *G;
G=GraphCreat("p176G719.txt");
BFSM(G);
}
main()很短,也很簡單,如有不明白的回顧下深度優先遍歷函式,
回顧一下:就是佇列Q里出佇列,然后找與該頂點相連的所有頂點、在進佇列,就是:
void BFSM(struct Graph *G)
{
int i,n;
struct Queue *Q;
struct ElemType *p,E,e;
Q=QueueInit();
E.sNo=0;
EnQueue(Q,&E);
G->Visited[0]=1;
p=&e;
while(!QueueEmpty(Q))
{
DeQueue(Q,p);
n=p->sNo;
printf("%s\n",G->pV[n]);
for(i=0;i<G->num;i++)
if(G->pA[n][i]==1&&G->Visited[i]==0)
{
G->Visited[i]=1;
E.sNo=i;
EnQueue(Q,&E);
}
}
}
運行這個程式、就會列印出這個圖的廣度優先遍歷結果,
結果的再次分析
有了這個函式后,構造main()開始從第0個頂點遍歷圖1,就是:
進一步測驗該函式,按圖1的資料仔細分析下它的執行程序,如有圖的連接分量不為1,則會在第一個連接分量遍歷完成后終止,如下圖4,在B1.C中是無法全部遍歷完成的,這個圖的檔案在G4.TXT,修改表23中第5行,從G4.TXT中讀資料,則會發現這個程式僅僅遍歷了A、B、C、D,而沒有到達過E、F、G這三個頂點,
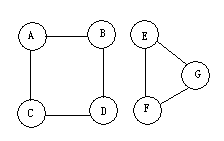
這個圖該如何遍歷呢?請同學們自己修改程式,完成這個圖的遍歷,
廣度優先遍歷到此結束,
C#語言實作圖的廣度優先遍歷、并顯示廣度優先遍歷生成樹
在C#檔案夾中可以找到“Graph0.cs”,這個檔案中包含著深度優先遍歷、廣度優先遍歷等程式中的所有圖類程式,現在,我們就要在這個類中補充新的方法,
首先復制這個類到Graph.cs,然后用C#建立一個Windows應用程式,然后在資源管理器中添加這個類,這個類和在深度優先遍歷中的類完全一致,但去掉了命名空間說明,這樣,這個類就可以使用在其他工程中了,
首先是再次熟悉這個類中的變數定義:
private int[,] A //鄰接矩陣
private string[] V //頂點矩陣
private int[] Visited //頂點訪問表
private TreeNode[] T //遍歷生成樹
private int num //頂點個數
private int ConnComp //連通分量
找到這個類中的最后一個方法:DSFTraverse(),然后開始在這個方法后補充新方法:DFS(),由于演算法和C語言完全一致,此處演算法問題不在介紹,
private void BFS(int N)
{
int n;
Queue<int> Q = new Queue<int>();
Q.Enqueue(N);
Visited[N] = 1;
while (Q.Count != 0)
{
n = Q.Dequeue();
for (int i = 0; i < num; i++)
if (A[n, i] == 1 && Visited[i] == 0)
{
T[n].Nodes.Add(T[i]);
Visited[i] = 1;
Q.Enqueue(i);
}
}
}
這個方法可以從第N個頂點開始遍歷,同前面涉及的問題一樣,考慮到多次遍歷、以及多連通分量的圖,我們還要補充下面的方法:
public int BFSTraverse()
{
int i;
ConnComp = 0;
for (i = 0; i < num; i++)
{
T[i] = new TreeNode(V[i]);
Visited[i] = 0;
}
for (i = 0; i < num; i++)
if (Visited[i] == 0)
{
BFS(i);
ConnComp++;
}
return ConnComp;
}
補充完類Graph中兩個方法補充后、就可以進行界面設計,設計界面如下:
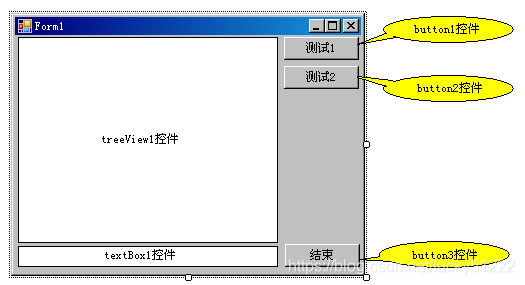
根據圖1的界面設計,則廣度優先遍歷程式中連通分量為1的圖在button1下,于是有:
private void button1_Click(object sender, EventArgs e)
{
int m;
int[,] A = {
{0, 1, 1, 0, 0, 0, 0, 0},
{1, 0, 0, 1, 1, 0, 0, 0},
{1, 0, 0, 0, 0, 1, 1, 0},
{0, 1, 0, 0, 0, 0, 0, 1},
{0, 1, 0, 0, 0, 0, 0, 1},
{0, 0, 1, 0, 0, 0, 1, 0},
{0, 0, 1, 0, 0, 1, 0, 0},
{0, 0, 0, 1, 1, 0, 0, 0}
};
string[] V = { "V1", "V2", "V3", "V4", "V5", "V6", "V7", "V8" };
Graph G = new Graph(8);
G.Arc = A; G.Vertex = V;
m = G.BFSTraverse();
treeView1.Nodes.Clear();
treeView1.Nodes.Add(G.DFSResult);
textBox1.Text = "該圖連接分量為" + m.ToString();
}
由于類設計中、廣泛使用了原有的代碼,所以這段程式看起來和深度優先遍歷的測驗代碼差別很小,同理,在有多個連通分量的情況下,在button2下的代碼是:
private void button2_Click(object sender, EventArgs e)
{
int m;
int[,] A = {
{0, 1, 1, 0, 0, 0, 0},
{1, 0, 0, 1, 0, 0, 0},
{1, 0, 0, 1, 0, 0, 0},
{0, 1, 1, 0, 0, 0, 0},
{0, 0, 0, 0, 0, 1, 1},
{0, 0, 0, 0, 1, 0, 1},
{0, 0, 0, 0, 1, 1, 0}
};
string[] V = { "A", "B", "C", "D", "E", "F", "G" };
Graph G = new Graph(7);
G.Arc = A; G.Vertex = V;
m = G.BFSTraverse();
treeView1.Nodes.Clear();
G.AddInTreeView(treeView1);
textBox1.Text = "該圖連接分量為" + m.ToString();
}
請自行補充button3下的代碼,
程式運行結果就是:
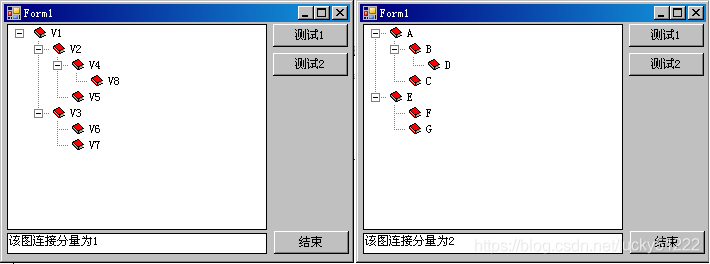 圖的廣度優先遍歷到此結束,通過上述編程我們可以發現:大量使用已有的代碼,可以大大簡化編程的復雜程度,
圖的廣度優先遍歷到此結束,通過上述編程我們可以發現:大量使用已有的代碼,可以大大簡化編程的復雜程度,
問題:
我們在C#的程式中、并沒有使用類似C語言那樣的技術:在資料檔案中保存圖的資料,這首先是基于我們對C#的使用方式造成的,C#最重要的應用場合是連接資料庫服務器和前端的用戶瀏覽器,這個場合下C#提供一個正確的運算類就足夠了,其資料要來自于資料庫,而結果要給到瀏覽器上的程式,瀏覽器下的程式就是JavaScript,這樣的情況下C#不做資料檔案讀取、而要做的是資料庫上資料讀取,至于送到JavaScript,這個對C#、就要通過一種叫WebService的技術,而在JavaScript上、則要用到一種叫Ajax技術讀寫這些資料,而這些都是下學期的重要實驗任務,
JavaScript語言實作圖的廣度優先遍歷、并顯示廣度優先遍歷生成樹
對JavaScript而言,是沒有佇列類的,盡管陣列的型別直接泛型,但僅有堆疊而無佇列,我們需要最低代價完成一個佇列系統,所以要再次查看JavaScript陣列的所有方法和屬性:
其中:FF: Firefox, IE: Internet Explorer
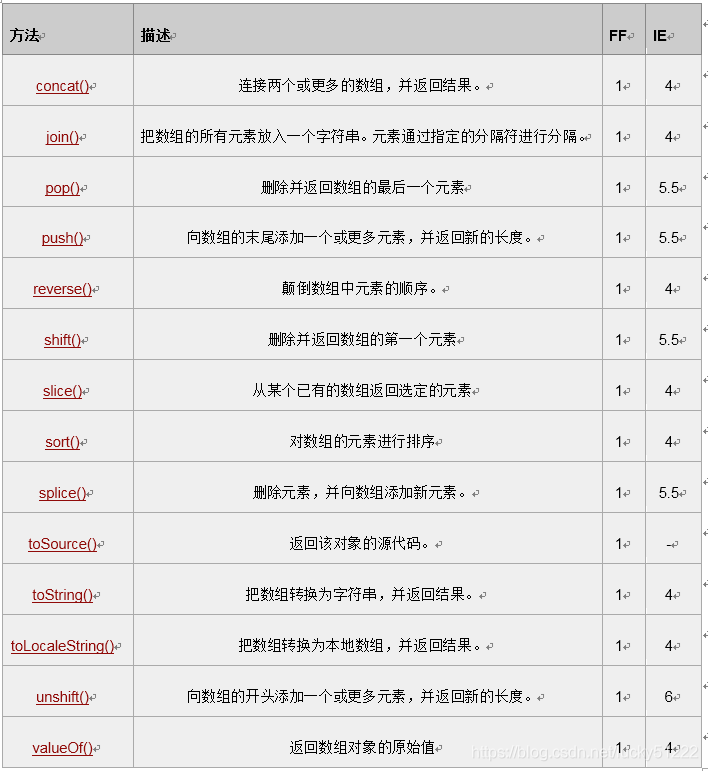
而這個物件提供的屬性,則如下表:FF: Firefox, IE: Internet Explorer

回顧堆疊和佇列的差異,一個是先進后出、一個是先進先出,查找上述陣列的方法,有個方法是reverse(),含義是顛倒陣列元素的次序,很顯然:
如果進佇列是陣列的push()操作,那么出佇列則就是顛倒陣列次序、然后pop()操作,有這個思路,按這個演算法構造佇列類就是:
function Queue()
{
this.Q=new Array();
this.EnQueue=function(E)
{
this.Q.push(E);
}
this.DeQueue=function()
{
var E;
this.Q=this.Q.reverse();
E=this.Q.pop();
this.Q=this.Q.reverse();
return E;
}
this.Count=function()
{
return this.Q.length;
}
}
一定注意這個類的第13行,顛倒次序出堆疊后一定要再次顛倒這個陣列的次序,保證進堆疊資料的次序,這樣,我們就用最小代價完成了一個佇列系統,然后補充多次進出佇列的測驗網頁,就是:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<title>一個呼叫Ext類別庫的模板頁面</title>
<script type="text/javascript" src="Queue.js"></script>
<script type="text/javascript" src="ext-3.0.0/adapter/ext/ext-base.js"></script>
<script type="text/javascript" src="ext-3.0.0/ext-all.js"></script>
<link rel="stylesheet" type="text/css" href="ext-3.0.0/resources/css/ext-all.css" />
</head>
<body bgcolor="#FFFFFF">
<div id="hello"></div>
<script type="text/javascript">
function fun()
{
var Q=new Queue();
Q.EnQueue(1);
Q.EnQueue(2);
Q.EnQueue(3);
while(Q.Count()>0)
{
document.write(Q.DeQueue()+'<br>');
}
Q.EnQueue(4);
Q.EnQueue(5);
while(Q.Count()>0)
{
document.write(Q.DeQueue()+'<br>');
}
}
Ext.onReady(fun);
</script>
</body>
</html>
注意第5行一定要參考Queue.js這個檔案,否則程式無法運行,
補充廣度優先遍歷程式
根據廣度優先遍歷的演算法、以及表1的佇列物件,不難寫出廣度優先遍歷程式,但寫以前我們要回顧深度優先遍歷函式的入口引數:
A[][]: 鄰接矩陣
vCount: 頂點個數
m: 進入遍歷的頂點編號
Visited[] :頂點訪問狀態表
T[]: Ext.tree.TreeNode物件陣列,遍歷結果樹
我們回顧這些的原因是:我們新的遍歷函式、也要盡量和舊的方法使用的引數一致,這樣就對后續的編程提供了大量的方便,如果意義相近的方法、其函式入口引數差異很大、這樣對后續的編程造成很多困惑,
//A[][]: 鄰接矩陣
//vCount: 頂點個數
//m: 進入遍歷的頂點編號
//Visited[] :頂點訪問狀態表
//T[]: Ext.tree.TreeNode物件陣列,遍歷結果樹
function BFS(A,vCount,m,Visited,T)
{
var i,n;
var Q=new Queue();
Q.EnQueue(m);
Visited[m]=1;
while(Q.Count()>0)
{
n = Q.DeQueue();
for (i = 0; i <vCount; i++)
if (A[n][i] == 1 && Visited[i] == 0)
{
T[n].appendChild(T[i]);
Visited[i] = 1;
Q.EnQueue(i);
}
}
}
表3 JavaScript語言圖的廣度優先遍歷,見工程B0.html
該函式演算法不在介紹,程式原理和C、C#沒什么差別,
從深度優先遍歷網頁補充廣度優先遍歷程式
從深度優先遍歷網頁G8.html復制檔案到B0.html,在F3區域的鄰接矩陣編輯視窗補充命令按鈕“廣度優先遍歷”,就是表4.
對這個表中的程式,注意是一個程式框架,而不是全部,現在就要在合適的位置補充廣度優先遍歷的初始化程式,
var grid=new Ext.grid.EditorGridPanel({
renderTo:"GRID",
title:"圖的鄰接矩陣編輯",
height:400,
width:400,
cm:colM,
store:gstore,
tbar: [
{
text: "深度優先遍歷圖",
handler: function()
{
//已有的深度遍歷代碼
}
},
{
text:"廣度優先遍歷圖",
handler: function()
{
//以下寫進遍歷的代碼
}
}
]
});
注意表4,其第20行就是補充廣度優先遍歷程式的地方,這程式本質就是給BFS()準備合適的資料、并初始化、然后呼叫BFS()函式,所以這地方和深度優先遍歷的代碼是一致的,于是有:
text:"廣度優先遍歷圖",
handler: function()
{
//以下寫進遍歷的代碼
var m=gstore.getCount();
var n=gstore.getAt(m-1).get('row')+1;
var Visited=Array();
var A=Array();
var i,j;
for(i=0;i<n;i++)
{
Visited[i]=0;
A[i]=Array();
T[i]=new Ext.tree.TreeNode({id:vstore.getAt(i).get('id'),text:vstore.getAt(i).get('V')});
}
for(i=0;i<m;i++)
{
var r=gstore.getAt(i).get('row');
var c=gstore.getAt(i).get('col');
var v=gstore.getAt(i).get('Value');
A[r][c]=v;
}
var Concom=0;
for(i=0;i<n;i++)
if(Visited[i]==0)
{
BFS(A,n,i,Visited,T);Concom++;
}
var TR=new Ext.tree.TreeNode({id:10000,text:'廣度優先遍歷樹,連通分量'+Concom});
for(i=0;i<n;i++)
if(T[i].parentNode==null)
TR.appendChild(T[i]);
treeView1.setRootNode(TR);
}
}
和前面深度優先遍歷的程式完全一致,僅僅是呼叫了不同的遍歷函式,
遍歷網頁的進一步修改和完善:構造圖類
從B0.html這個網頁程式看,首先在兩個遍歷的命令按鈕程式上有大量重復代碼,其次是有關圖的計算,其鄰接矩陣、頂點矩陣、頂點訪問狀態矩陣、遍歷函式等都是分離的變數和函式,而沒有構成一個類、從而也就沒有圖的物件,這樣對后續的編程也造成很多不利,
為此,我們要構造一個JavaScript的圖類,整體參照C#,
對任何一個語言的類編程而言,都存在資料如何進入物件、以及資料如何從物件里給出這兩個基本問題,在使用Ext程序中,我們熟悉了大量的Ext物件屬性獲得方法,那么我們這里也將按同樣的方法來構造類,詳細的介紹參見json教程,以下類名稱是Graph,其中G是屬性引數:
function Graph(G)
{
this.A=G.A;
this.V=G.V;
this.Visited=G.Visited;
this.num=G.num;
this.T=G.T;
}
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<title>一個呼叫Ext類別庫的模板頁面</title>
<script type="text/javascript" src="G0.js"></script>
<script type="text/javascript" src="ext-3.0.0/adapter/ext/ext-base.js"></script>
<script type="text/javascript" src="ext-3.0.0/ext-all.js"></script>
<link rel="stylesheet" type="text/css" href="ext-3.0.0/resources/css/ext-all.css" />
</head>
<body bgcolor="#FFFFFF">
<div id="hello"></div>
<script type="text/javascript">
function fun()
{
var G=new Graph({
A:[[1,2,3],[4,5,6],[7,8,9]],V:['A','B','C'],Visited:[0,0,0]
});
}
Ext.onReady(fun);
</script>
</body>
</html>
注意第16行,其中建構式的引數里:
{A:[[1,2,3],[4,5,6],[7,8,9]],V:['A','B','C'],Visited:[0,0,0]}
整體構成物件G,進入類后,進入表5程式后,由第3到第5行的程式賦值給物件相應的屬性,再次參照表5程式,其中的this,對應在表6的程式是G,廣義上,實體化的物件就是表5中的this,
有了上述分析,我們就可以在表5的程式中加入一個公共方法,用來獲得屬性中V陣列的內容,代碼就是:
function Graph(G)
{
this.A=G.A;
this.V=G.V;
this.Visited=G.Visited;
this.num=G.num;
this.T=G.T;
this.VName=function()
{
var i;
for(i=0;i<this.num;i++)
document.write(this.V[i]);
}
}
這樣寫的方法類似是C#中的public void VName(),這樣的寫法可以在實體物件中參考這樣方法,如:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<title>一個呼叫Ext類別庫的模板頁面</title>
<script type="text/javascript" src="G1.js"></script>
<script type="text/javascript" src="ext-3.0.0/adapter/ext/ext-base.js"></script>
<script type="text/javascript" src="ext-3.0.0/ext-all.js"></script>
<link rel="stylesheet" type="text/css" href="ext-3.0.0/resources/css/ext-all.css" />
</head>
<body bgcolor="#FFFFFF">
<script type="text/javascript">
function fun()
{
var G=new Graph({
A:[[1,2,3],[4,5,6],[7,8,9]],
V:['A','B','C'],
Visited:[0,0,0],
num:3
});
G.VName();
}
Ext.onReady(fun);
</script>
</body>
</html>
上述程序完成后,可以加入一個求V陣列中每行平均值的方法,涉及到求平均值,首先我們需要一個求指定行和的函式,這個函式定義成私有的,如同表9的程式中的Sum(),私有函式定義和普通的JavaScript函式完全一致,
但在實際使用中,錯誤首先在第17行,表示this.num是沒有定義,
造成這樣的結果,主要是私有的函式Sum()并不包含在物件中,這點和C#是完全不一樣,所以私有函式中要參考物件的資料,要首先獲得該物件的實體,就是要有這樣的方法:
var Ob=this;
function Sum()
{
…
for(i=0;i<Ob.num;i++)
…
}
function Graph(G)
{
this.A=G.A;
this.V=G.V;
this.Visited=G.Visited;
this.num=G.num;
this.T=G.T;
this.VName=function()
{
var i;
for(i=0;i<this.num;i++)
document.write(this.V[i]);
}
function Sum(n)
{
var s=0,i;
for(i=0;i<this.num;i++) //私有方法中錯誤參考物件資料
s+=this.A[n][i];
return s;
}
this.AVG=function(n)
{
var s;
s=Sum(n)/this.num;
}
}
function Graph(G)
{
this.A=G.A;
this.V=G.V;
this.Visited=G.Visited;
this.num=G.num;
this.T=G.T;
this.VName=function()
{
var i;
for(i=0;i<this.num;i++)
document.write(this.V[i]);
}
function Sum(n)
{
var s=0,i;
for(i=0;i<this.num;i++) //私有方法中錯誤參考物件資料
s+=this.A[n][i];
return s;
}
this.AVG=function(n)
{
var s;
s=Sum(n)/this.num;
}
}
function Graph(G)
{
this.A=G.A;
this.V=G.V;
this.Visited=G.Visited;
this.num=G.num;
this.T=G.T;
var Ob=this;
//公共方法
this.VName=function()
{
var i;
for(i=0;i<this.num;i++)
document.write(this.V[i]);
}
//私有方法
function Sum(n)
{
var s,i;
s=0;
for(i=0;i<Ob.num;i++)
s+=Ob.A[n][i];
return s;
}
//公共方法
this.AVG=function(n)
{
var a;
a=Sum(n)/this.num;
return a;
}
}
通過上述實驗程序,則有兩個遍歷方法的圖類就是:
function Graph(G)
{
this.A=G.A;
this.V=G.V;
this.Visited=G.Visited;
this.num=G.num;
this.T=G.T;
var Ob=this;
//私有方法:深度優先遍歷
function DFS(m)
{
var i;
Ob.Visited[m]=1;
for(i=0;i<Ob.num;i++)
{
if(Ob.A[m][i]!=0&&Ob.Visited[i]!=1)
{
Ob.T[m].appendChild(Ob.T[i]);
DFS(i);
}
}
}
//公共方法:深度優先遍歷、以及初始化
this.DSFTraverse=function()
{
var i,Comcon=0;
if (this.num==0||this.num==undefined) return -1;
for(i=0;i<this.num;i++)
{
this.Visited[i]=0;
this.T[i]=new Ext.tree.TreeNode({id:i,text:this.V[i]});
}
for(i=0;i<this.num;i++)
if(this.Visited[i]==0)
{
DFS(i);Comcon++;
}
return Comcon;
}
//私有方法:廣度優先遍歷
function BFS(m)
{
var i,n;
var Q=new Queue();
Q.EnQueue(m);
Ob.Visited[m]=1;
while(Q.Count()>0)
{
n = Q.DeQueue();
for (i = 0; i <Ob.num; i++)
if (Ob.A[n][i] == 1 && Ob.Visited[i] == 0)
{
Ob.T[n].appendChild(Ob.T[i]);
Ob.Visited[i] = 1;
Q.EnQueue(i);
}
}
}
//公共方法:深度優先遍歷、以及初始化
this.BSFTraverse=function()
{
var i,Comcon=0;
if (this.num==0||this.num==undefined) return -1;
for(i=0;i<this.num;i++)
{
this.Visited[i]=0;
this.T[i]=new Ext.tree.TreeNode({id:i,text:this.V[i]});
}
for(i=0;i<this.num;i++)
if(this.Visited[i]==0)
{
BFS(i);
Comcon++;
}
return Comcon;
}
//獲得遍歷結果樹,適應多個連接分量情況下,
this.getTree=function()
{
for(i=1;i<this.num;i++)
if(this.T[i].parentNode==null)
this.T[0].appendChild(this.T[i]);
return this.T[0];
}
}
有了上述圖類后,則相應的界面上“深度優先遍歷”按鈕下的相應程式就是:
text: "深度優先遍歷圖",
handler: function()
{
//以下寫進遍歷的代碼
var m=gstore.getCount();
var n=gstore.getAt(m-1).get('row')+1;
var Visited=Array();
var A=Array();
var i,j;
for(i=0;i<n;i++)
{
Visited[i]=0;
A[i]=Array();
}
//獲得鄰接矩陣資料
for(i=0;i<m;i++)
{
var r=gstore.getAt(i).get('row');
var c=gstore.getAt(i).get('col');
var v=gstore.getAt(i).get('Value');
A[r][c]=v;
}
//獲得鄰接矩陣資料
var V=new Array();
//獲得頂點名稱
for(i=0;i<vstore.getCount();i++)
V[i]=vstore.getAt(i).get('V');
//用變數給物件各個屬性賦值
var G=new Graph({
A:A,V:V,T:T,num:n,Visited:Visited
});
m=G.DSFTraverse();
var TR=new Ext.tree.TreeNode({id:10000,text:'深度優先遍歷樹,連通分量'+m});
TR.appendChild(G.getTree());
treeView1.setRootNode(TR);
}
上面僅僅給出深度優先遍歷的回應程式,廣度優先遍歷的代碼同上述程序基本一樣,僅僅是在第32行處為:m=G.BSFTraverse();
到此,JavaScript的兩種遍歷全部完成,這里,圖的資料來自Ext.data.ArrayStore物件,目前是常數定義或者控制元件輸入,以后還要加入Ajax方法、從C#讀遠程資料庫的資料,這都是下學期的任務了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/286615.html
標籤:其他