HDFS小檔案優化
1. 小檔案弊端
HDFS 上每個檔案都要在NameNode 上創建對應的元資料,這個元資料的大小約為150byte,這樣當小檔案比較多的時候,就會產生很多的元資料檔案,一方面會大量占用NameNode 的記憶體空間,另一方面就是元資料檔案過多,使得尋址索引速度變慢
小檔案過多,在進行MR 計算時,會生成過多切片,需要啟動過多的 MapTask,每個
MapTask 處理的資料量小,導致 MapTask 的處理時間比啟動時間還小,白白消耗資源
2. 小檔案解決方案
2.1 資料源頭
在資料采集的時候,就將小檔案或小批資料合成大檔案再上傳 HDFS
2.2 存盤方向
Hadoop Archive是一個高效的將小檔案放入HDFS 塊中的檔案存檔工具,能夠將多個小檔案打包成一個HAR檔案,HAR檔案對內還是一個一個獨立檔案,對 NameNode 而言卻是一個整體,從而達到減少 NameNode的記憶體使用
-
歸檔檔案
把/inputs 目錄里面的所有檔案歸檔成一個叫 inputs.har 的歸檔檔案,并把歸檔后檔案存盤到/output 路徑下[codecat@hadoop102 hadoop-3.1.3]$ hadoop archive -archiveName inputs.har -p /inputs /output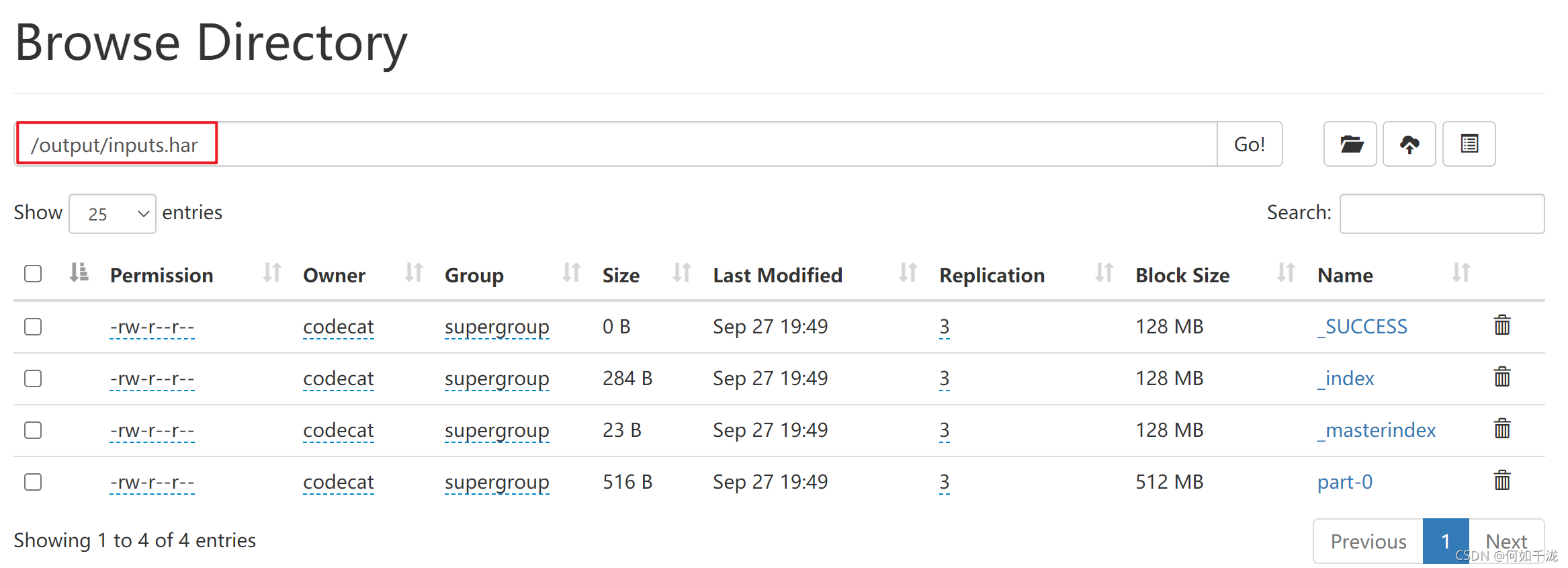
-
查看歸檔
[codecat@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /output/inputs.har Found 4 items -rw-r--r-- 3 codecat supergroup 0 2021-09-27 19:49 /output/inputs.har/_SUCCESS -rw-r--r-- 3 codecat supergroup 284 2021-09-27 19:49 /output/inputs.har/_index -rw-r--r-- 3 codecat supergroup 23 2021-09-27 19:49 /output/inputs.har/_masterindex -rw-r--r-- 3 codecat supergroup 516 2021-09-27 19:49 /output/inputs.har/part-0 [codecat@hadoop102 hadoop-3.1.3]$ hadoop fs -ls har:///output/inputs.har Found 3 items -rw-r--r-- 3 codecat supergroup 193 2021-09-27 19:37 har:///output/inputs.har/hello.txt -rw-r--r-- 3 codecat supergroup 80 2021-09-27 19:37 har:///output/inputs.har/kv.txt -rw-r--r-- 3 codecat supergroup 243 2021-09-27 19:37 har:///output/inputs.har/nline.txt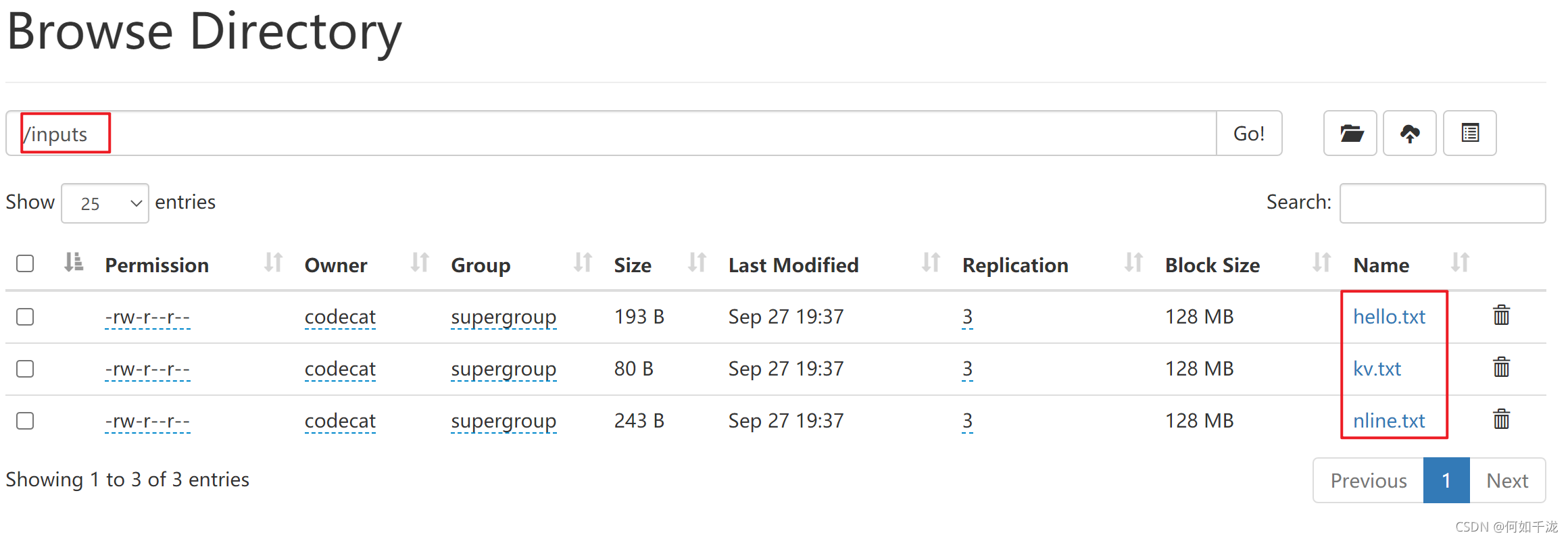
-
解歸檔檔案
[codecat@hadoop102 hadoop-3.1.3]$ hadoop fs -cp har:///output/inputs.har/* /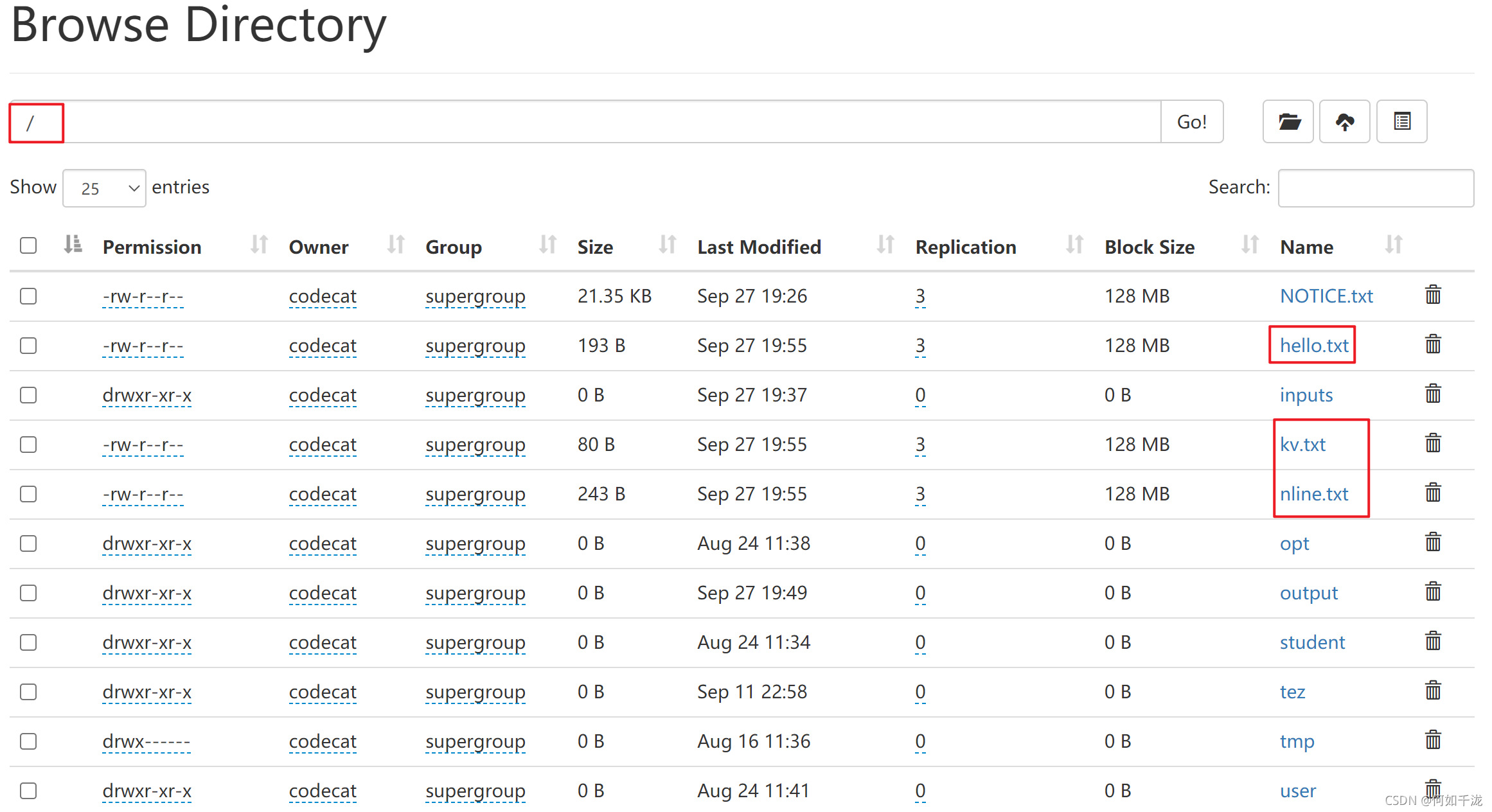
2.3 計算方向
2.3.1 CombineTextInputFormat
CombineTextInputFormat 用于將多個小檔案在切片程序中生成一個單獨的切片或者少
量的切片,
2.3.2 開啟 uber 模式,實作 JVM 重用
默認情況下,每個 Task 任務都需要啟動一個JVM 來運行,如果 Task 任務計算的資料量很小,我們可以讓同一個 Job 的多個 Task 運行在一個 JVM 中,不必為每個 Task 都開啟一個 JVM
-
未開啟
uber模式,在/inputs路徑上上傳多個小檔案并執行wordcount程式[codecat@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /inputs /output
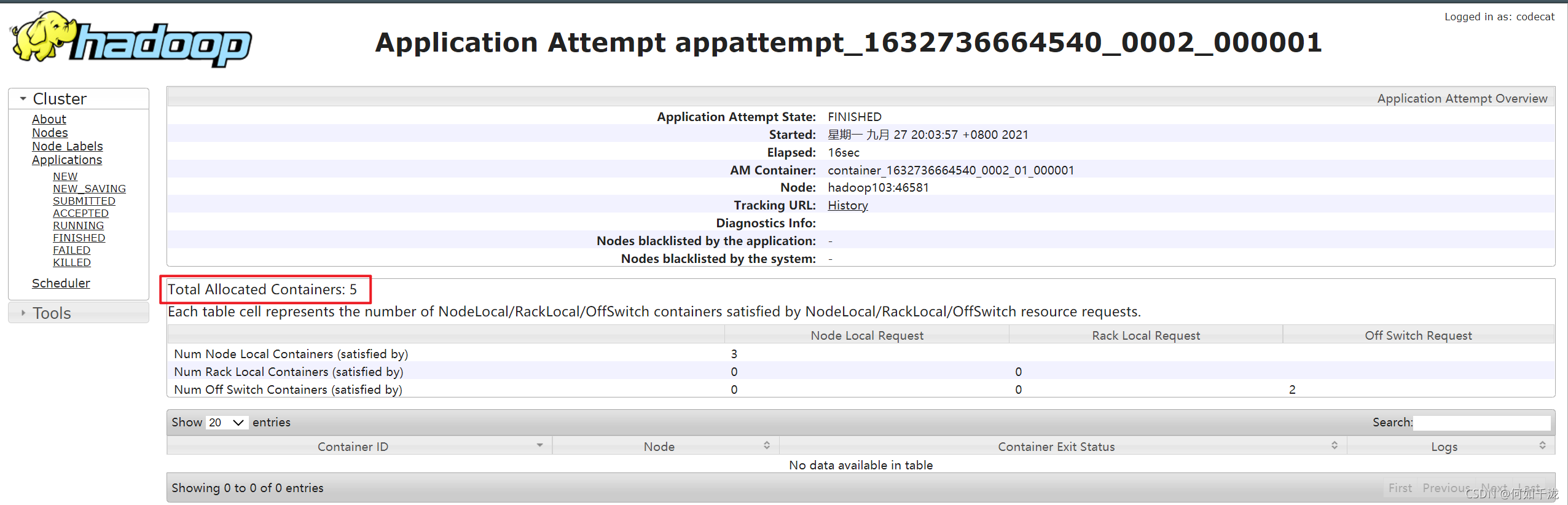
-
開啟
uber模式,在mapred-site.xml中添加如下配置并分發集群<!-- 開啟 uber 模式,默認關閉 --> <property> <name>mapreduce.job.ubertask.enable</name> <value>true</value> </property> <!-- uber 模式中最大的 mapTask 數量,可向下修改 --> <property> <name>mapreduce.job.ubertask.maxmaps</name> <value>9</value> </property> <!-- uber 模式中最大的 reduce 數量,可向下修改 --> <property> <name>mapreduce.job.ubertask.maxreduces</name> <value>1</value> </property> <!-- uber 模式中最大的輸入資料量,默認使用 dfs.blocksize 的值,可向下修 改 --> <property> <name>mapreduce.job.ubertask.maxbytes</name> <value></value> </property> -
再次執行
wordcount程式[codecat@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /inputs /output1
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/304091.html
標籤:其他