這個問題真的讓我很困惑。他們沒有提供足夠的細節。不管他們提供了什么,我都寫在下面。
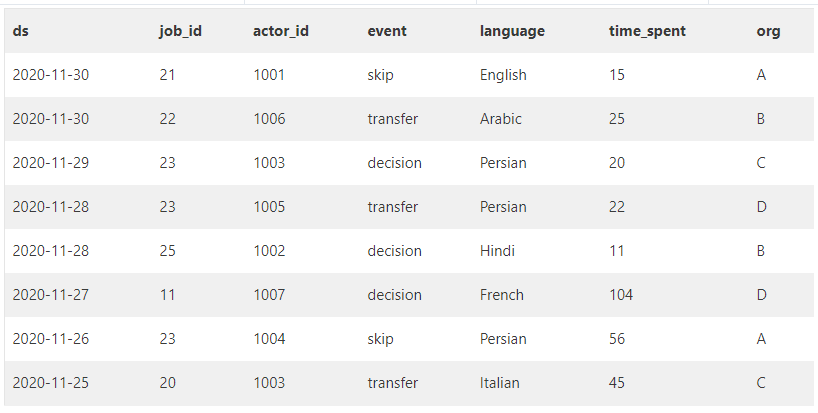
CREATE TABLE job_data
(
ds DATE,
job_id INT NOT NULL,
actor_id INT NOT NULL,
事件 VARCHAR(15) NOT NULL。
language VARCHAR(15) Not NULL,
time_spent INT NOT NULL,
org CHAR(2)
);
INSERT INTO job_data (ds, job_id, actor_id, event, language, time_spent, org)
VALUES ('2020-11-30', 21, 1001, 'skip', 'English', 15, 'A')。)
('2020-11-30', 22, 1006, 'transfer', 'Arabic', 25, 'B')。)
('2020-11-29', 23, 1003, 'decision', 'Persian', 20, 'C')。)
('2020-11-28', 23, 1005, 'transfer', 'Persian', 22, 'D')。)
('2020-11-28', 25, 1002, 'decision', 'Hindi', 11, 'B')。)
('2020-11-27', 11, 1007, 'decision', 'French', 104, 'D')。)
('2020-11-26', 23, 1004, 'skip', 'Persian', 56, 'A')。)
('2020-11-25', 20, 1003, 'transfer', 'Italian', 45, 'C')。)
下面是資料。需要考慮的要點:
該事件是什么意思?審查時要考慮什么?
這是我試過的查詢:
這是我試過的查詢。
SELECT ds。COUNT(*)/24 As no_of_job
FROM job_data
WHERE ds BETWEEN '2020-11-01' AND '2020-11-30'
GROUP BY ds。
uj5u.com熱心網友回復:
檢查下面的方法,如果它是你正在尋找的東西。
select ds,count(job_id) as jobs_per_day。sum(time_spent)/3600 作為 hours_spent
from job_data
where ds > ='2020-11-01' and ds <='2020-11-30' >。
group by ds ;
Demo MySQL 5.6。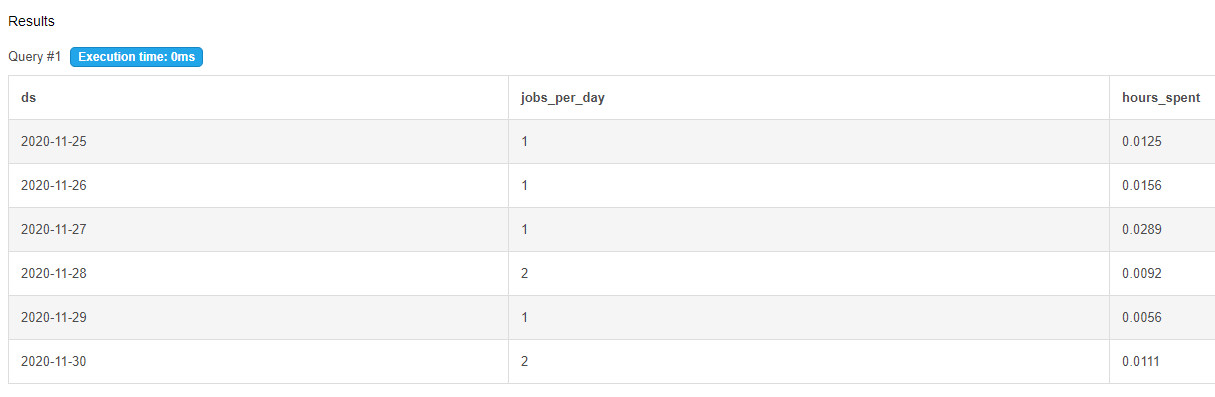
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/306813.html
標籤: