這個想法是在 CSV 檔案中讀取如下表:
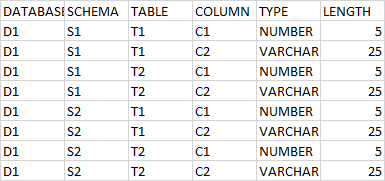
DATABASE,SCHEMA,TABLE,COLUMN,TYPE,LENGTH
D1,S1,T1,C1,NUMBER,5
D1,S1,T1,C2,VARCHAR,25
D1,S1,T2,C1,NUMBER,5
D1,S1,T2,C2,VARCHAR,25
D1,S2,T1,C1,NUMBER,5
D1,S2,T1,C2,VARCHAR,25
D1,S2,T2,C1,NUMBER,5
D1,S2,T2,C2,VARCHAR,25
并在python中在字串變數中創建相應的查詢,例如:
create table <s1>.<t1> (c1 number(5), c2 varchar(25));
create table <s1>.<t2> (c1 number(5), c2 varchar(25));
create table <s2>.<t1> (c1 number(5), c2 varchar(25));
create table <s2>.<t2> (c1 number(5), c2 varchar(25));
我的想法是將表存盤在 json 陣列中,或者我可以使用 Pandas,但我不知道根據要使用的迭代執行它的最簡單方法是什么
uj5u.com熱心網友回復:
假設您的 DataFrame 是df,請使用:
groups = df.groupby(["SCHEMA", "TABLE"]).agg({"COLUMN": list, "TYPE": list, "LENGTH": list})
for (schema, table), row in groups.iterrows():
record = zip(row["COLUMN"], row["TYPE"], row["LENGTH"])
columns = ", ".join(f"{column} {type_}({length})" for column, type_, length in record)
sentence = f"create table <{schema}>.<{table}> {columns};"
print(sentence)
輸出
create table <S1>.<T1> C1 NUMBER(5), C2 VARCHAR(25);
create table <S1>.<T2> C1 NUMBER(5), C2 VARCHAR(25);
create table <S2>.<T1> C1 NUMBER(5), C2 VARCHAR(25);
create table <S2>.<T2> C1 NUMBER(5), C2 VARCHAR(25);
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/318285.html
下一篇:python:按多個字典鍵分組