我在使用 iris 資料集時遇到分類問題,我可以在原始資料集上創建一個配對圖,如下所示 hue='species'
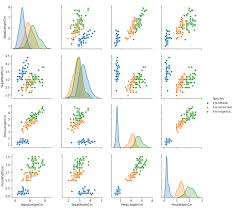
但是hue在將資料集拆分為 X_train,y_train 后如何使用,因為物種類正在被分離?
X = DATA.drop(['class'], axis = 'columns')
y = DATA['class'].values
X_train, X_test, y_train, y_test=train_test_split(X,y, test_size=0.20,random_state =42)
gbl_pl=[]
gbl_pl.append(('standard_scaler_gb',
StandardScaler(copy=cpystadscl, with_mean=wthmenstadscl, with_std=withstdscl)))
gblpq=Pipeline((gbl_pl))
scaled_df=gblpq.fit_transform(X_train,y_train)
sns.pairplot(data=scaled_df)
plt.show()
輸出
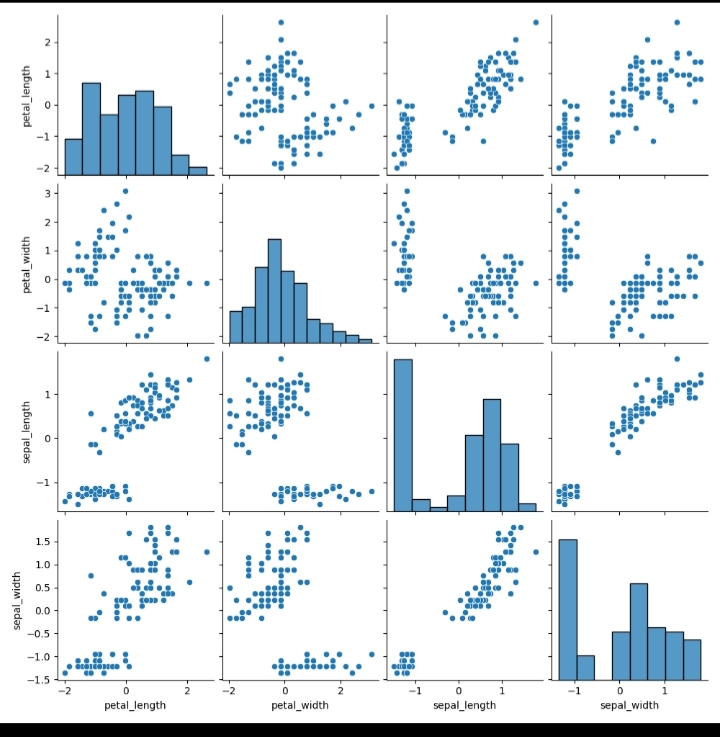
期望(與不包括測驗資料的拆分資料集類似)
uj5u.com熱心網友回復:
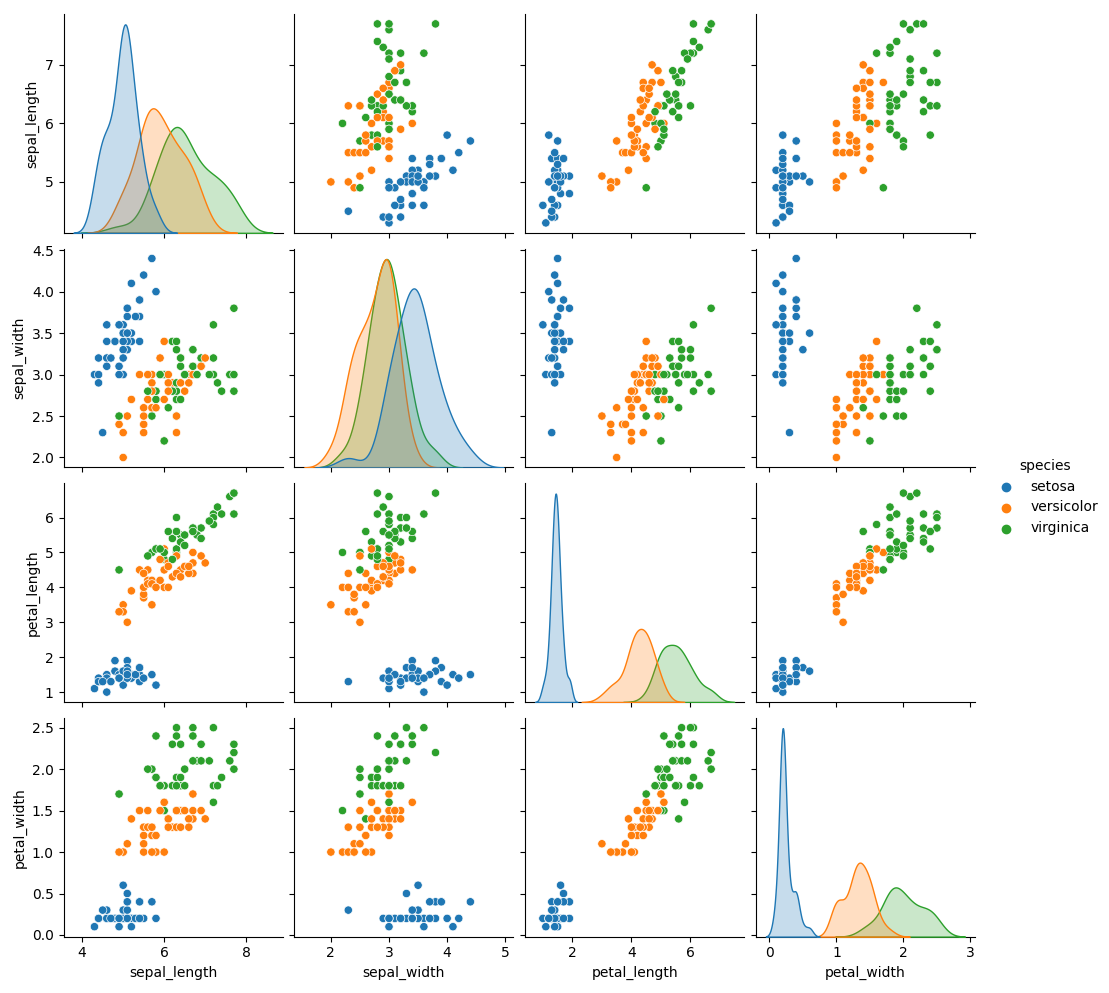
您可以將 y_train 作為列連接到 X_train。
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
import seaborn as sns
import pandas as pd
import numpy as np
iris = sns.load_dataset('iris')
X = iris.drop(columns='species')
y = iris['species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)
sns.pairplot(data=pd.concat([X_train, y_train], axis=1), hue=y_train.name)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/323198.html