我的data.frame
structure(list(a = c("12, "asd"。 "zxc", "123")。 b = c("45",
"qwe", "curced"。 "64")。 c = c("78"。 "tyu", "454"。 "76"))。 class = "data. frame",行。 names = c(NA,)
-4L))
我想在另一列下添加一列,并為這些列分配和指定組。例如,為第一列 "1",為第二前列 "2",為第三列移 "3",等等。我知道如何將列轉移到另一列之下,但我不知道如何給它們分配組
。我想得到的是:
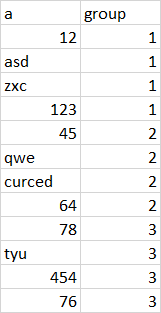
uj5u.com熱心網友回復:
如果我理解,這里有兩種不同的方法
。library(tidyverse)
1-) 將名字與矢量字母進行比較
這里我把每個名字與它們在字母表中的位置進行比較,使用矢量字母
df %>%
pivot_longer(cols = everything()) %> %
rowwise() %> %
mutate(group = which(name == 信))
2-) 創建一個輔助性的資料框架
在這個備選方案中,創建一個帶有變數name和group的data.frame。
df %>%
pivot_longer(cols = everything()) %> %
left_join()
tibble()
name = c("a"/span>。 "b","c"),
組 = 1:3
)
)
# A tibble: 12 x 3
名稱值組
<chr> < chr> <int>/span>
1 a 12 1
2 b 45 2
3 c 78 3
4 a asd 1
5 b qwe 2
6 c tyu 3
7 a zxc 1
8 b curced 2
9 c 454 3
10 a 123 1
11 b 64 2
12 c 76 3
uj5u.com熱心網友回復:
使用Map
result <- do.call(rbind, Map(data. frame, a = df, 組= seq_along(df)))
另一種方法是使用tidyverse函式。
library(dplyr)
library(tidyr)
df%>%
pivot_longer(cols = everything()。 names_to = 'group') %> %
mutate(group = match(group, unique(group)) %> %
arrange(group)
# group值
# <int> <chr>
# 1 1 12
# 2 1 asd
# 3 1 zxc # 3 1 zxc
# 4 1 123 # 4 1 123
# 5 2 45 # 5 2 45
# 6 2 qwe # 6 2 qwe
# 7 2 curced # 2 curced
# 8 2 64 # 2 64
# 9 3 78
#10 3 tyu #10 3 tyu
#11 3 454
#12 3 76
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/326406.html
標籤:
上一篇:改進應用/Lambda的運行時間