我想用pandas風格寫一個多指標資料框架到excel,但我得到了一個錯誤。
import pandas as pd
import numpy as np
df=pd.DataFrame(np.random.randn(9,4), pd.MultiIndex. from_product([['A', 'B','C'], ['r1', 'r2','r3']], columns=[['E1', 'E1','E2','E2'], ['d1', 'd2','d1','d2']] )
def highlight_max(s, props='') 。
return np.where(s == np.nanmax(s.values), props, ''/span>)
def highlight_all_by_condition (value, condition, props='') 。
return np.where(value >= condition, props, '')
def highlight_max_value_by_condition(value, condition, props=''>) 。
return np.where(np.nanmax(value) >= condition, props, ''/span>)
df_formatted = df.style.set_properties(**{'font-family': 'Arial','font-size': '10pt'})
unique_column_list = list(set(df.columns.get_level_values(0) )
idx = pd.IndexSlice
for each in unique_column_list:
slice_=idx[idx[each]]
df_formatted = df_formatted.apply(highlight_max, props='color:black; font-weight: bold'/span>, axis=1, subset=slice_)
.apply(highlight_all_by_condition, condition = 0.55, props='color:red; font-weight: bold; background-color: #ffe6e6'/span>, axis=1, subset=slice_)
.apply(highlight_max_value_by_condition, condition = 1, props='color:green; font-weight: bold; background-color: #ffff33'/span>, axis=1, subset=slice_)
df_formatted.to_excel("test.xlsx", engine = 'openpyxl')
我得到了以下錯誤:
我得到了以下錯誤。
ValueError: Function <function highlight_max_value_by_condition at 0x000001EE1394E940> returned the wrong shape.
結果有形狀。(9,)
預期的形狀。 (9, 2)
第二個造型函式(highlight_max_value_by_condition)是一個條件性的造型,它需要在滿足條件的情況下突出顯示最大值,如果我洗掉這個造型函式,那么我不會得到任何錯誤。
如果有任何幫助,我將非常感激。謝謝。
uj5u.com熱心網友回復:
假設我們正在尋找highlight_max_value_by_condition是為了將樣式應用于既是子集中的最大值又滿足條件的單元格,我們可以添加一個&來組合條件:
def highlight_max_value_by_condition(value, condition, props='')。)
return np.where(
(value == np.nanmax(value)) & (value >= condition) 。
支持。
''/span>
)
然而,除此之外,我們還可以做很多事情來清理一般的方法。
Styler物件自然是復合的,沒有必要再分配回去。此外,與其使用list(set()來獲取級別值,不如使用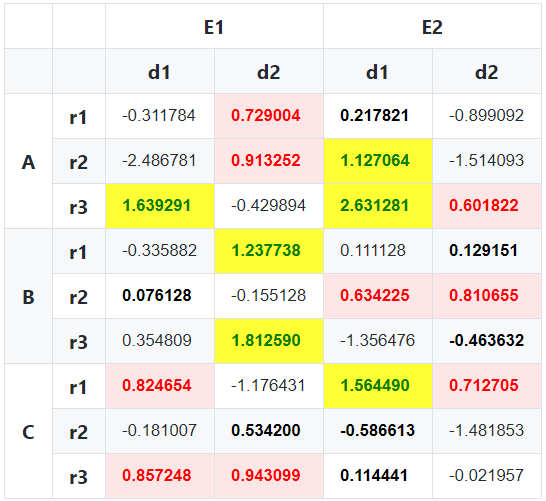
用seed(6)和修改后的函式使設定具有可重復性
。import numpy as np
import pandas as pd
np.random.seed(6)
df = pd.DataFrame(
np.random.randn(9, 4)。
pd.MultiIndex. from_product([['A'/span>, 'B'/span>, 'C'/span>], ['r1'/span>, 'r2'/span>, 'r3'/span>]]。
columns=[['E1'/span>, 'E1'/span>, 'E2'/span>, 'E2'/span>]。['d1', 'd2', 'd1', 'd2'] ]
)
def highlight_max(s, props='') 。
return np.where(s == np.nanmax(s.values), props, ''/span>)
def highlight_all_by_condition(value, condition, props='') 。
return np.where(value >= condition, props, ''/span>)
def highlight_max_value_by_condition(value, condition, props=''>) 。
return np.where(
(value == np.nanmax(value)) & (value >= condition) 。
支持。
''/span>
)
df:
E1 E2
d1 d2 d1 d2
A r1 -0.311784 0.729004 0.217821 -0.899092
r2 -2.486781 0.913252 1.127064 -1.514093
r3 1.639291 -0.429894 2.631281 0.601822[/span
B r1 -0.335882 1.237738 0.111128 0.129151[/span
r2 0.076128 -0.155128 0.634225 0.810655
r3 0.354809 1.812590 -1.356476 -0.463632[/span
C r1 0.824654 -1.176431 1.564490 0.712705[/span
r2 -0.181007 0.534200 -0.586613 -1.481853[/span
r3 0.857248 0.943099 0.114441 -0.021957
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/332406.html
標籤: