我有以下 RDD
2019-09-24,Debt collection,transworld systems inc. is trying to collect a debt that is not mine not owed and is inaccurate.
2019-09-19,Credit reporting credit repair services or other personal consumer reports,
3個元素中的每一個都相應地表示
- 日期
- 標簽
- 注釋
我需要應用過濾器轉換,以便僅保留以“201”(日期)開頭的記錄并包含注釋(它們具有值并且在第三個元素中不是空字串)。
我使用以下代碼來計算每次過濾轉換減少了多少記錄:
countA = rdd.count()
countB = rdd.filter(lambda x: x.startswith('201')).count()
countC = rdd.filter(lambda x: x.startswith('201') & (x.split(",")[2] != None) & (len(x.split(",")[2]) > 0)).count()
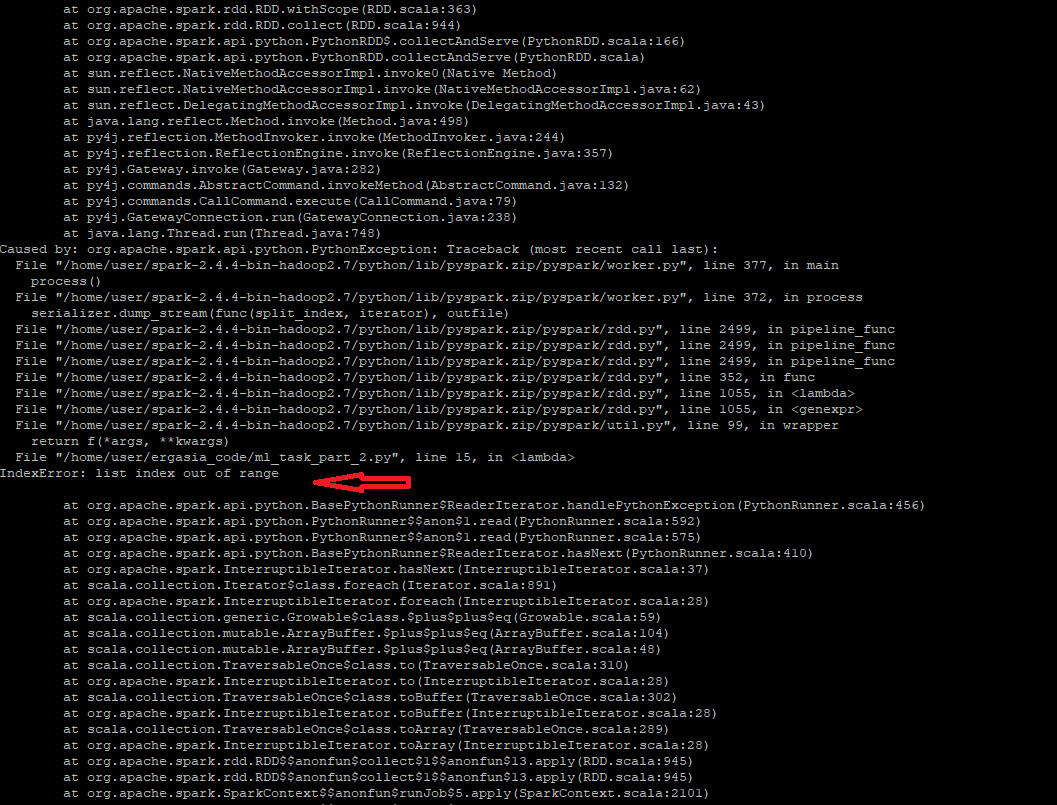
我的代碼在計算時崩潰了countC,雖然看起來過濾在我的進一步計算中起作用,但我也得到了更多的錯誤......
uj5u.com熱心網友回復:
你收到錯誤:
IndexError:串列索引超出范圍
因為您正在嘗試訪問2串列的索引(拆分的結果),如果資料集中的某些行只有日期或日期和標簽,或者為空或可能有格式問題,則該索引可能不存在。
在您的 lambda 函式中,您可以利用 python 中的短路在嘗試訪問此索引之前首先檢查是否至少有 3 個元素(即2可以使用len(x.split(",")) >=3代替 代替 的(x.split(",")[2] != None)索引)。
這可以寫成:
countC = rdd.filter(lambda x: x.startswith('201') and (len(x.split(",")) >=3) and (len(x.split(",")[2]) > 0))
讓我知道這是否適合您。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/333873.html