我有一個如下所示的資料集:
campaign_name
abcloancde
abcsolcdf
abcemicdef
emic_estore
Personalloa-nemic_sol
personalloa_nemic
abc/emic-dg-upi:bol
campaign_name列名在哪里。我還有一個dictionary像下面這樣:
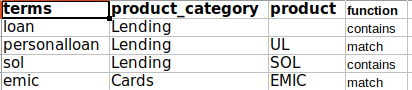
根據我的用例,我必須根據長度terms降序對字典進行排序,并且必須將其與campaign_name列進行映射。無論terms是首次發現的campaign_name,其相關的product_category和product應該接走。為此,我撰寫了以下代碼并且它作業正常:
#Dataset loaded below
initialData = spark.read.option("header", "true").csv("file://..../sample_data.csv")
initialData.show()
#Dictionary loaded below
df = spark.read.option("header",
"true").csv("file://..../mapper.csv")
df_contains = df.filter(df.function == 'contains').drop("function")
df_contains = df_contains.orderBy(length(col("terms")).desc())
w = Window.partitionBy(lit('A')).orderBy(length(col("terms")).desc())
df_contains = df_contains.withColumn("rw", row_number().over(w))
df3 = df_contains.na.fill("").groupBy(lit(1)).agg(collect_list(
concat(col("rw"), lit(":"), col("terms"), lit(":"), col("product_category"), lit(":"), col("product"))).alias(
"Check")).withColumn("Check", concat_ws(",", col("Check"))).drop("1")
def categoryFunction(name, Check):
# checkList = Check.lower().split(",")
out = ""
match = False
for Key in Check.lower().split(","):
keyword = Key.split(":", 2)
terms = keyword[1]
tempOut = keyword[2]
if terms in name.lower():
out = tempOut
match = True
if match:
break
return out
def categoryFunction1(name, Check):
# checkList = Check.lower().split(",")
out = ""
match = False
for Key in Check.lower().split(","):
keyword = Key.split(":", 2)
terms = keyword[1]
tempOut = keyword[2]
if terms == name.lower():
out = tempOut
match = True
if match:
break
return out
categoryUDF = udf(categoryFunction, StringType())
categoryUDF1 = udf(categoryFunction1, StringType())
df4 = initialData.crossJoin(df3)
finalDF = df4.withColumn("out", categoryUDF(col("campaign_name"), col("Check"))).drop("Check").withColumn("out", split(
col("out"), ":")).withColumn("product_category", col("out")[0]).withColumn("product", col("out")[1]).drop(
"out").withColumn("prod", when(col("product").isNull(), "other").otherwise(col("product"))).withColumn("prod_cat",
when(
col("product_category") == "",
"other").otherwise(
col("product_category"))).drop(
"product", "product_category")
它給了我以下正確的輸出:
--------------------- ----- --------
|campaign_name |prod |prod_cat|
--------------------- ----- --------
|abcloancde | |lending |
|abcsolcdf |sol |lending |
|abcemicdef |other|other |
|emic_estore |other|other |
|personalloan-emic_sol| |lending |
|personalloan_emic | |lending |
|abc/emic-dg-upi:bol |other|other |
--------------------- ----- --------
現在,我只想選擇campaign_nameswhereprod和prod_catvalues are other。獲得這樣以后campaign_names我有分裂campaign_names的基礎上"_",再次對運行狀況dictionary,其中function="match"并挑選product和product_category為完成contains
I have written a categoryFunction1 UDF for this and it actually works when I am filtering out the required dataset for the match condition and doing whatever I need to do and then doing union with the above output(which updates the values for "other").
Is there any way like by using "case...when..then" which explodes the data as I need and doing the crossJoin and then picking up the FIRST EXACT MATCH value? Because I am dealing with billions of records so wanted to think of a more optimal solution.
Final expected output(contains exact):
--------------------- ----- --------
|campaign_name |prod |prod_cat|
--------------------- ----- --------
|abcloancde | |lending |
|abcsolcdf |sol |lending |
|abcemicdef |other|other |
|emic_estore |emic |cards |
|personalloan-emic_sol| |lending |
|personalloan_emic | |lending |
|abc/emic-dg-upi:bol |other|other |
--------------------- ----- --------
Catch:
我在問題中遺漏了一種情況。在比較包含和精確匹配時,我必須消除所有分隔符,我可以考慮所有分隔符,但只需要在基礎上拆分單詞"_"然后比較它們。
任何建議都非常感謝。
uj5u.com熱心網友回復:
與使用可以利用 spark 優化的 spark api 相比,spark 集群上的 UDF 可能很昂貴。我理解您創建df3包含在您的 udfs 中的原因,但這可能不是必需的。特別是當您的字典資料的大小可能會增長并且要創建的聚合df3可能很昂貴并導致資料溢位(從記憶體到磁盤)時,因為您將所有內容分組為 1 行。如果它比活動資料小得多,您可以選擇broadcast帶有字典資料的資料框。
根據您的樣本資料df_contains具有以下內容
df_contains = dictionaryDf.filter(dictionaryDf.function == 'contains').drop("function").na.fill("")
df_contains.show(truncate=False)
----- ---------------- -------
|terms|product_category|product|
----- ---------------- -------
|loan |Lending | |
|sol |Lending |SOL |
----- ---------------- -------
僅使用 spark api 的另一種方法是:
方法一
第1部分
注意。您已經使用 UDF 完成了第 1 部分
- 左加入字典資料(廣播,如果這可以提高您的性能)關于該術語是否位于廣告系列名稱中。
- 然后,您可以首先使用視窗函式行號來識別最長的項,或者按照您的描述:
我必須根據術語的長度降序對字典進行排序,并且必須將其與 Campaign_name 列進行映射
- 選擇您想要的列并使用您的案例運算式邏輯(即與何時)
該方法可以編碼如下:
from pyspark.sql import functions as F
output_df = (
# Step 1
initial_data.join(
F.broadcast(df_contains),
F.col("campaign_name").contains(F.col("terms")),
"left"
)
# Step 2
.withColumn(
"rn",
F.row_number().over(
Window.partitionBy("campaign_name")
.orderBy(
F.length(F.col("terms")).desc()
)
)
)
.filter("rn=1")
# Step 3
.select(
"campaign_name",
F.when(
F.col("product").isNull(),"other"
).otherwise(F.col("product")).alias("prod"),
F.when(
F.col("product_category").isNull(),"other"
).otherwise(F.col("product_category")).alias("prod_cat")
)
)
output_df.show(truncate=False)
這會導致以下輸出(注意,spark 中的行排序是不確定的,除非指定了順序):
--------------------- ----- --------
|campaign_name |prod |prod_cat|
--------------------- ----- --------
|abc/emic-dg-upi:bol |other|other |
|abcemicdef |other|other |
|abcloancde | |Lending |
|abcsolcdf |SOL |Lending |
|emic_estore |other|other |
|personalloan-emic_sol| |Lending |
|personalloan_emic | |Lending |
--------------------- ----- --------
第2部分
我們可能會使用與上述類似的方法解決您的其余問題
- Split the
campaign_nameby_and useexplodeto get multiple rows for each piece - Left Join on the split campaign name, aliased below as
cname_split, and whereprodandprod_catare equal tootherfor the split campaign names - Instead of using a when/case expression to check for null matches and re-assign the original value we may use
coalescewhich assigns the first non-null value - Since we have multiple rows for each
campaign_nameafter the explode, we may aggregate, however in the example below, I've usedrow_numberto filter the duplicate entries and order by availableproductnames.
NB. df_match as referenced below was retrieved using
df_match = dictionaryDf.filter(dictionaryDf.function == 'match').drop("function").na.fill("")
df_match.show(truncate=False)
------------ ---------------- -------
|terms |product_category|product|
------------ ---------------- -------
|personalloan|Lending |UL |
|emic |Cards |EMIC |
------------ ---------------- -------
Code:
from pyspark.sql import functions as F
output_df2 = (
# Step 1
output_df.select(
"*",
F.explode(F.split("campaign_name","_")).alias("cname_split")
)
# Step 2
.join(
df_match,
(
F.col("campaign_name").contains("_") &
F.col("cname_split").contains(F.col("terms")) &
(F.col("prod") == "other") &
(F.col("prod_cat") == "other")
),
"left"
)
# Step 3
.select(
"campaign_name",
F.coalesce("product","prod").alias("prod"),
F.coalesce("product_category","prod_cat").alias("prod_cat"),
# Step 4
F.row_number().over(
Window.partitionBy("campaign_name")
.orderBy(
F.col("product").isNull()
)
).alias("rn")
)
.filter("rn=1")
.drop("rn")
)
output_df2.show(truncate=False)
--------------------- ----- --------
|campaign_name |prod |prod_cat|
--------------------- ----- --------
|abc/emic-dg-upi:bol |other|other |
|abcemicdef |other|other |
|abcloancde | |Lending |
|abcsolcdf |SOL |Lending |
|emic_estore |EMIC |Cards |
|personalloan-emic_sol| |Lending |
|personalloan_emic | |Lending |
--------------------- ----- --------
Approach 2
This is similar to the approach above however, it is more optimal as it achieves it's aim using less joins.
Code:
from pyspark.sql import functions as F
output_df3 = (
initial_data.withColumn("cname_split",F.explode(F.split("campaign_name","_")))
.join(
dictionaryDf,
(
(
(F.col("function")=="contains") &
F.col("campaign_name").contains(F.col("terms"))
) |
(
(F.col("function")=="match") &
F.col("campaign_name").contains("_") &
F.col("cname_split").contains(F.col("terms"))
)
),
"left"
)
.withColumn(
"empty_is_other",
F.when(
(
F.col("product").isNull() &
F.col("product_category").isNull()
),
"other"
)
)
.withColumn(
"rn",
F.row_number().over(
Window.partitionBy("campaign_name")
.orderBy(
F.when(
F.col("function").isNull(),3
).when(
F.col("function")=="match",2
).otherwise(1),
F.length(F.col("terms")).desc(),
F.col("product").isNull()
)
)
)
.filter("rn=1")
.select(
"campaign_name",
F.coalesce("product","empty_is_other").alias("prod"),
F.coalesce("product_category","empty_is_other").alias("prod_cat"),
)
.na.fill("")
)
output_df3.show(truncate=False)
Outputs
--------------------- ----- --------
|campaign_name |prod |prod_cat|
--------------------- ----- --------
|abc/emic-dg-upi:bol |other|other |
|abcemicdef |other|other |
|abcloancde | |Lending |
|abcsolcdf |SOL |Lending |
|emic_estore |EMIC |Cards |
|personalloan-emic_sol| |Lending |
|personalloan_emic | |Lending |
--------------------- ----- --------
Output before .filter("rn=1") for clarification
--------------------- ------------------- ------------ ---------------- ------- -------- -------------- ---
|campaign_name |cname_split |terms |product_category|product|function|empty_is_other|rn |
--------------------- ------------------- ------------ ---------------- ------- -------- -------------- ---
|abc/emic-dg-upi:bol |abc/emic-dg-upi:bol|null |null |null |null |other |1 |
|abcemicdef |abcemicdef |null |null |null |null |other |1 |
|abcloancde |abcloancde |loan |Lending |null |contains|null |1 |
|abcsolcdf |abcsolcdf |sol |Lending |SOL |contains|null |1 |
|emic_estore |emic |emic |Cards |EMIC |match |null |1 |
|emic_estore |estore |null |null |null |null |other |2 |
|personalloan-emic_sol|personalloan-emic |loan |Lending |null |contains|null |1 |
|personalloan-emic_sol|sol |loan |Lending |null |contains|null |2 |
|personalloan-emic_sol|personalloan-emic |sol |Lending |SOL |contains|null |3 |
|personalloan-emic_sol|sol |sol |Lending |SOL |contains|null |4 |
|personalloan-emic_sol|personalloan-emic |personalloan|Lending |UL |match |null |5 |
|personalloan-emic_sol|personalloan-emic |emic |Cards |EMIC |match |null |6 |
|personalloan_emic |personalloan |loan |Lending |null |contains|null |1 |
|personalloan_emic |emic |loan |Lending |null |contains|null |2 |
|personalloan_emic |personalloan |personalloan|Lending |UL |match |null |3 |
|personalloan_emic |emic |emic |Cards |EMIC |match |null |4 |
--------------------- ------------------- ------------ ---------------- ------- -------- -------------- ---
Update 1
In response to question update:
Catch:
There is one scenario that I missed in the question. I have to eliminate all the delimiters while comparing for contains and for the exact match I can consider all the delimiters but just have to split the words on the basis of "_" and then compare them.
regexp_replace was used to remove special characters. See update below:
output_df3 = ( # _/:
initial_data.withColumn("cname_split",F.explode(F.split("campaign_name","_")))
.withColumn(
"campaign_name_clean",
F.regexp_replace(
F.lower(F.col("campaign_name")),
'[^a-zA-Z0-9]',
""
)
)
.join(
dictionaryDf,
(
(
(F.col("function")=="contains") &
F.col("campaign_name_clean").contains(F.col("terms"))
) |
(
(F.col("function")=="match") &
F.col("campaign_name").contains("_") &
(F.col("cname_split")==F.col("terms"))
)
),
"left"
)
.withColumn(
"empty_is_other",
F.when(
(
(
(F.col("function")=="contains") | F.col("function").isNull()
) &
F.col("product").isNull() &
F.col("product_category").isNull()
),
"other"
)
)
.withColumn(
"rn",
F.row_number().over(
Window.partitionBy("campaign_name")
.orderBy(
F.when(
F.col("function").isNull(),3
).when(
F.col("function")=="match",2
).otherwise(1),
F.length(F.col("terms")).desc(),
F.col("product").isNull()
)
)
)
.filter("rn=1")
.select(
"campaign_name",
F.coalesce("product","empty_is_other").alias("prod"),
F.coalesce("product_category","empty_is_other").alias("prod_cat"),
)
.na.fill("")
)
output_df3.show(truncate=False)
Outputs:
--------------------- ----- --------
|campaign_name |prod |prod_cat|
--------------------- ----- --------
|Personalloa-nemic_sol| |Lending |
|abc/emic-dg-upi:bol |other|other |
|abcemicdef |other|other |
|abcloancde | |Lending |
|abcsolcdf |SOL |Lending |
|emic_estore |EMIC |Cards |
|personalloa_nemic | |Lending |
--------------------- ----- --------
Output before .filter("rn=1") for debugging purposes
--------------------- ------------------- ------------------- ----- ---------------- ------- -------- -------------- ---
|campaign_name |cname_split |campaign_name_clean|terms|product_category|product|function|empty_is_other|rn |
--------------------- ------------------- ------------------- ----- ---------------- ------- -------- -------------- ---
|Personalloa-nemic_sol|Personalloa-nemic |personalloanemicsol|loan |Lending |null |contains|null |1 |
|Personalloa-nemic_sol|sol |personalloanemicsol|loan |Lending |null |contains|null |2 |
|Personalloa-nemic_sol|Personalloa-nemic |personalloanemicsol|sol |Lending |SOL |contains|null |3 |
|Personalloa-nemic_sol|sol |personalloanemicsol|sol |Lending |SOL |contains|null |4 |
|abc/emic-dg-upi:bol |abc/emic-dg-upi:bol|abcemicdgupibol |null |null |null |null |other |1 |
|abcemicdef |abcemicdef |abcemicdef |null |null |null |null |other |1 |
|abcloancde |abcloancde |abcloancde |loan |Lending |null |contains|null |1 |
|abcsolcdf |abcsolcdf |abcsolcdf |sol |Lending |SOL |contains|null |1 |
|emic_estore |emic |emicestore |emic |Cards |EMIC |match |null |1 |
|emic_estore |estore |emicestore |null |null |null |null |other |2 |
|personalloa_nemic |personalloa |personalloanemic |loan |Lending |null |contains|null |1 |
|personalloa_nemic |nemic |personalloanemic |loan |Lending |null |contains|null |2 |
--------------------- ------------------- ------------------- ----- ---------------- ------- -------- -------------- ---
Let me know if this works for you.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/333875.html