我有一個包含字串的列的熊貓 DF。
(我以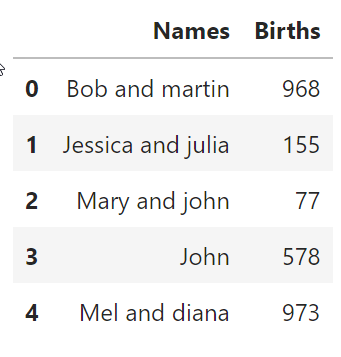
給出一個像“martin andrew bob”這樣的字串,我想過濾DF以獲得subDF,其中的行在名稱中包含字串的所有單詞(以任何順序和大小寫)。
最好的方法是什么?我的解決方案將涉及一個 for 回圈,將掩碼添加為布林值串列,但在我看來,這個解決方案很麻煩。
uj5u.com熱心網友回復:
這是我的建議:
my_str = 'martin andrew bob'
a[a['Names'].str.lower()
.str.split()
.apply(set(my_str.lower().split()).issubset)
].reset_index(drop=True)
輸出:
Names Births
0 Bob and martin and Andrew 968
1 martin bob diana and Andrew 968
我正在向lower()my_str添加函式,但是如果您確定字串總是以小寫形式給出,則可以跳過它。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/336992.html