我試圖從下面的串列中創建一個資料框,其中第一列是“網頁”,它是索引號,第二列是“destination_nodes”,它是 dest_nodes 的串列。
for col in range(10001):
print(col)
dest_nodes = M.index[M[col] == 1.0].tolist()
print(dest_nodes)
print(col) 和 print(dest_nodes) 的輸出示例如下所示:
0
[2725, 2763, 3575, 4377, 6221, 7798, 7852, 8014, 8753, 9575]
1
[137, 753, 1434, 2182, 3163, 3646, 3684, 3702, 3966, 4353, 4410, 5029, 5610, 5671, 6149, 6505, 6835, 7027, 7030, 7127, 7724, 7876, 8006, 8676, 8821, 9069, 9226, 9321]
2
[473, 1843, 6748]
3
[67, 433, 537, 1068, 1118, 1191, 1236, 1953, 2285, 2848, 3296, 3816, 4155, 4507, 4704, 4773, 5028, 5333, 5341, 5613, 5656, 5858, 6068, 6169, 6239, 7367, 7897, 7909, 8973, 9113, 9576, 9799, 9909]
4
[]
我嘗試了以下但它似乎沒有給我我所需要的。
dest_node = pd.DataFrame (col, dest_nodes, columns = ["webpage","destination_nodes"])
我想要的輸出資料幀是這樣的:
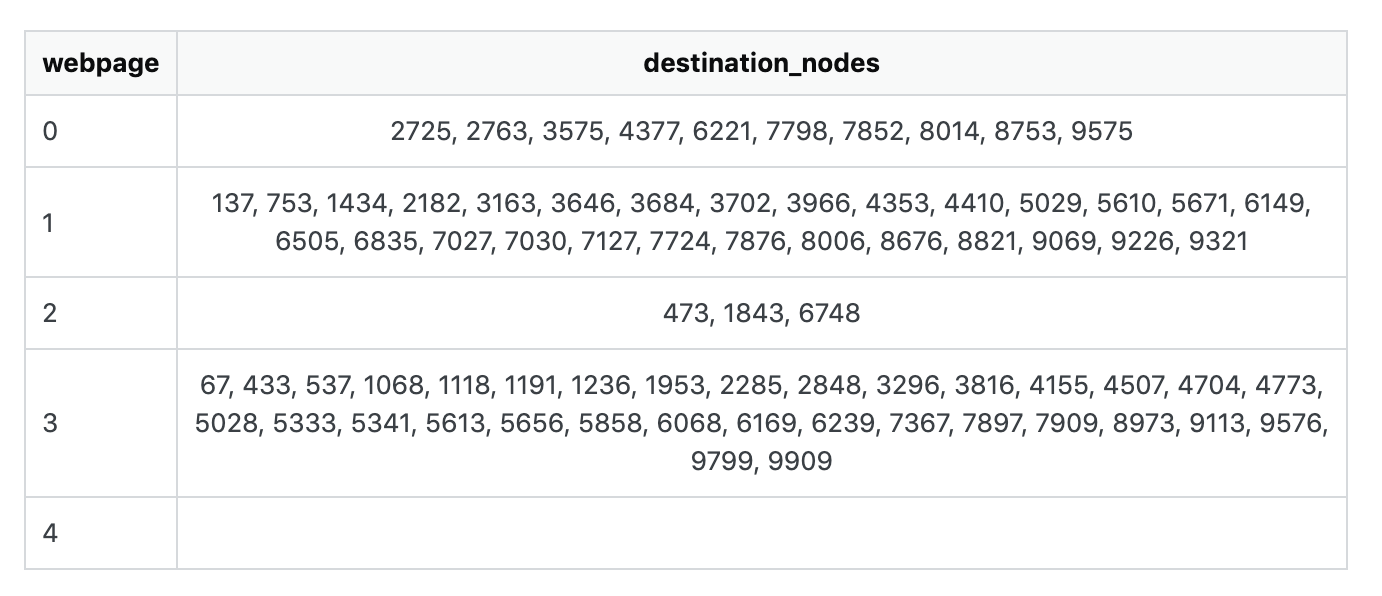
非常感謝我能得到的任何幫助!
uj5u.com熱心網友回復:
您可以使用 zip 來實作。像這樣
pd.DataFrame(zip(col, dest_nodes), columns=["webpage","destination_nodes"])
如果要洗掉括號并希望與影像中顯示的表示完全相同,請先運行以下代碼,然后創建一個 DataFrame。
dest_nodes = [str(l1).replace('[', '').replace(']','') for l1 in dest_nodes]
uj5u.com熱心網友回復:
也許你可以M直接使用:
df = pd.DataFrame(
{'webpage': M.columns,
'destination_nodes': M.eq(1).apply(lambda x: M[x].index.tolist())}
)
print(df)
# Output
webpage destination_nodes
0 0 [0, 2]
1 1 [0, 1]
2 2 []
3 3 [1]
4 4 [1, 2]
設定:
data = {'0': [1, 0, 1],
'1': [1, 1, 0],
'2': [0, 0, 0],
'3': [0, 1, 0],
'4': [0, 1, 1]}
M = pd.DataFrame(data)
print(M)
# Output:
0 1 2 3 4
0 1 1 0 0 0
1 0 1 0 1 1
2 1 0 0 0 1
uj5u.com熱心網友回復:
我會使用串列理解來設定dictionary:
df = pd.DataFrame({col:[M.index[M[col] == 1.0].tolist()] for col in range(10001)}, index="nodes")
df.index.name = "website"
print(df.traspose())
uj5u.com熱心網友回復:
這有效
# Make list
colLst = [i for i in range(10001)]
dest_nodesLst =[M.index[M[col] == 1.0].tolist() for col in range(1001)]
# Make data frame
dic = {"col":colLst,"M":dest_nodesLst}
dest_node = pd.DataFrame(data=dic)
# print head of dataframe
print(dest_node.head())
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/340162.html
上一篇:Python,索引超出范圍,串列