當我在基數 R 中對字符向量使用 sum 時,按預期計數:
Letters <- c("A","A","B", "B")
Pass <- c("Pass", "Fail", "Pass", "Fail")
df <- data.frame( Letters, Pass)
sum(df$Pass=="Fail")
[1] 2
當我在 dplyr 中使用 sum 時,它的計數方式不同:
Pass_summary <- df %>% group_by(Letters) %>%
summarise(n=n(),
Pass=sum(Pass=="Pass"),
Fail=sum(Pass=="Fail")
)
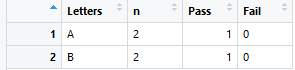
我現在從 MrGrumble 的評論中了解到 Pass 將在第 3 行重新分配。雖然我認為有必要使用 mutate() 來參考在 summarise() 階段分配的變數?
uj5u.com熱心網友回復:
你壓倒一切Pass!
嘗試切換順序summarize:
df %>% group_by(Letters) %>%
summarise(n=n(),
Fail=sum(Pass=="Fail"),
Pass=sum(Pass=="Pass")
)
輸出:
Letters n Fail Pass
<chr> <int> <int> <int>
1 A 2 1 1
2 B 2 1 1
或者只是不要將其命名為“通過”!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/341298.html
下一篇:為列中的每個組創建線性回歸模型