您好,我有一個簡單的問題,我需要在 txt 檔案中找到特定行,它們必須包含“LG”,如下所示:
>NC_037638.1 Apis mellifera strain DH4 linkage group LG1, Amel_HAv3.1, whole genome shotgun sequence
那么我需要在這種情況下NC_037638.1用LG1
LG替換數字,并且每一行的數字都會不同
結果應該是這樣的:
>LG1, Apis mellifera strain DH4 linkage group LG1, Amel_HAv3.1, whole genome shotgun sequence
我在一個檔案中有 3 百萬行,我只需要找到那些帶有 LG 的行,后跟一些數字,如示例中所示 LG1
所以基本上我需要從中得到:
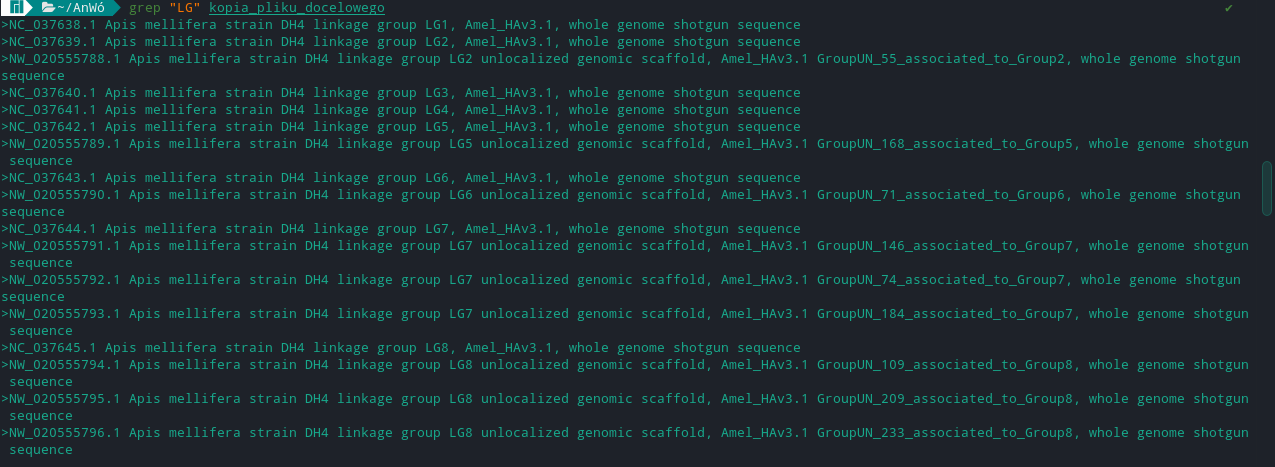
對此:
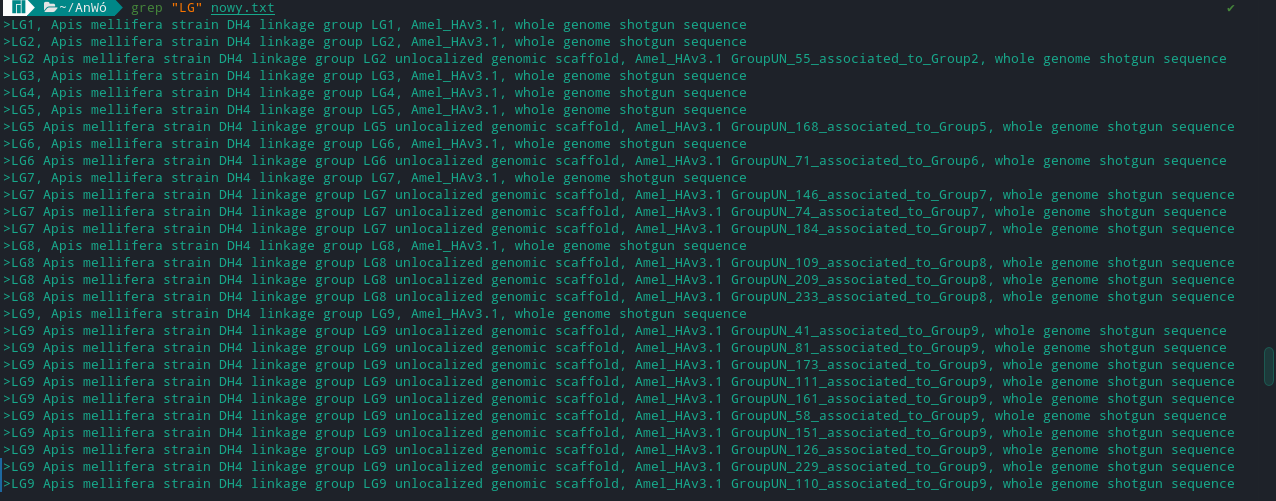
我寫了這樣的東西:
#!/bin/bash
while IFS= read -r line; do
if [[ $line =~ "LG" ]]; then
echo $line | awk ' { t = $1; $1 = $8; print; } ' | sed -e 's/^/>/' >> nowy.txt
else
echo $line >> nowy.txt
fi
done < kopia_pliku_docelowego
它可以作業,但它的速度非常慢,腳本結束需要 3 分鐘
我想到了解決方案,我想我可以 grep 行索引并只更改那些行,然后在與新重寫的索引相同的索引上交換舊行。
我知道如何找到索引(grep -n)
,我知道如何更改線路(談論與 LG 交換號碼),但我不知道如何將它們放在一起。
我真的很感激一些幫助
uj5u.com熱心網友回復:
我真的不明白問題描述。聽起來您只想用第 8 列替換包含LG. 如果是這種情況,請執行以下操作:
awk '/LG/{ $1 = $8 }1' kopia_pliku_docelowego > nowy.txt
但也許您想限制匹配,以便僅在第 8 列中出現“LG”時才進行替換。你可以這樣做:
awk '$8 ~ /LG/{ $1 = $8 }1'
如果您要求LG其后跟一串數字,請使用:
awk '$8 ~ /LG[0-9] /{ $1 = $8 }1'
如果您有第 8 列是LGxxxAAA(數字后面的非字串值)的行,并且您只想用匹配的字串部分替換第一列LG[0-9 ],則可以使用:
awk 'match($8,/LG[0-9] /){ $1 = substr($8,0,RLENGTH) }1'
awk毫無疑問可以解決您的問題,但您需要明確說明您要匹配的內容。您的sed解決方案似乎插入了>根據您的描述似乎沒有必要的前導。需要更多的特異性。
uj5u.com熱心網友回復:
您可以一次完成此操作sed:
sed -i.bak -E 's/^>NC_037638\.1(.* (LG[0-9] ))/>\2\1/' file
cat file
>LG1 Apis mellifera strain DH4 linkage group LG1, Amel_HAv3.1, whole genome shotgun sequence
解釋:
^>:>開始位置后匹配NC_037638\.1: 匹配文本NC_037638.1(.*: Nn 捕獲組 #1 匹配并捕獲后跟空格后跟...的任何文本(LG[0-9] )): 匹配LG后跟捕獲組 #2 中的 1 數字>\2\1:替換部分>后跟LG子字串(我們在組 #2 中捕獲的內容),然后是捕獲組 #1 的反向參考
uj5u.com熱心網友回復:
只是 awk,也許:
awk '{
for(i=1;i<NF-1;i )
if($i=="linkage" && $(i 1)=="group")
break
if(i!=NF-1)
$1=$(i 2)
print
}' file.txt
我們搜索兩個連續的詞“鏈接”和“組”,以防萬一它們在行中并不總是位于相同的位置。我懷疑這可能是因為“ Apis mellifera ”看起來像一個包含空格的單個欄位。如果我們找到這兩個詞,我們將第一個欄位替換為“鏈接組”之后的欄位。
如果按照“現場聯動組”必須被進一步限制,例如要LGnnn在那里nnn是數字一些字串,我們可以改一下條件:
awk '{
for(i=1;i<NF-1;i )
if($i=="linkage" && $(i 1)=="group" && $(i 2) ~ /^LG[[:digit:]] /)
break;
if(i!=NF-1)
$1=$(i 2)
print
}' file.txt
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/363377.html