我有一個 CSV 檔案,它看起來像
K1
,Value
M1,0
M2,10
M3,3
K2
,Value,Value,Value
M1,4,6,3
M2,7,3,4
M3,10,2,6
K1
,Value,Value
M1,0,4
M2,10,2
M3,3,7
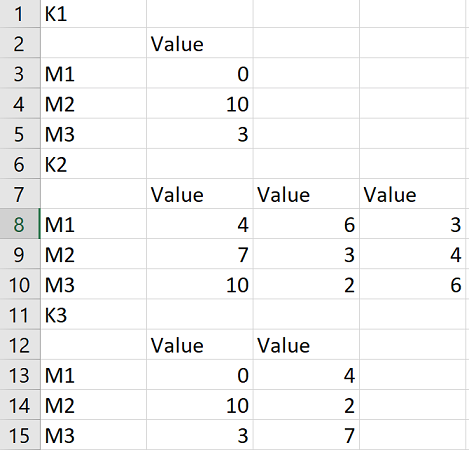
該檔案按 5 行分組。例如,第一組的名稱是 K1,后面跟著一個固定的 3 行 1 列的資料框。組中的行數是固定的,但列數是可變的。K1有1列,K2有3列,K3有2列。我想閱讀它以形成一個字典,其中鍵是組名,K1、K2 或 K3,值是與組名關聯的資料幀。
簡單的read_csv喜歡df = pd.read_csv('test.batch.csv')失敗并出現以下錯誤
Traceback (most recent call last):
File "test.py", line 8, in <module>
df = pd.read_csv('test.batch.csv')
File "/home/mahmood/.local/lib/python3.8/site-packages/pandas/io/parsers.py", line 610, in read_csv
return _read(filepath_or_buffer, kwds)
File "/home/mahmood/.local/lib/python3.8/site-packages/pandas/io/parsers.py", line 468, in _read
return parser.read(nrows)
File "/home/mahmood/.local/lib/python3.8/site-packages/pandas/io/parsers.py", line 1057, in read
index, columns, col_dict = self._engine.read(nrows)
File "/home/mahmood/.local/lib/python3.8/site-packages/pandas/io/parsers.py", line 2061, in read
data = self._reader.read(nrows)
File "pandas/_libs/parsers.pyx", line 756, in pandas._libs.parsers.TextReader.read
File "pandas/_libs/parsers.pyx", line 771, in pandas._libs.parsers.TextReader._read_low_memory
File "pandas/_libs/parsers.pyx", line 827, in pandas._libs.parsers.TextReader._read_rows
File "pandas/_libs/parsers.pyx", line 814, in pandas._libs.parsers.TextReader._tokenize_rows
File "pandas/_libs/parsers.pyx", line 1951, in pandas._libs.parsers.raise_parser_error
pandas.errors.ParserError: Error tokenizing data. C error: Expected 2 fields in line 7, saw 4
我知道該檔案的格式不適合 read_csv(),所以我想知道是否還有其他類似的讀取函式可以使用。對此有什么想法嗎?
uj5u.com熱心網友回復:
我的想法是從一個空的中間字典開始。
然后從輸入檔案(鍵)中讀取一行,并將其后的 4 行作為值并將它們添加到字典中。
最后一步是“映射”這個字典,使用字典理解,將每個(字串)值更改為一個 DataFrame。
為此,您可以使用read_csv,將當前鍵的值作為源內容傳遞。
所以源代碼可以是:
wrk = {}
with open('Input.csv') as fp:
while True:
cnt1 = 1
line = fp.readline()
if not line:
break
key = line.strip()
txt = [ fp.readline().strip() for i in range(4) ]
txt = '\n'.join(txt)
wrk[key] = txt
result = { k: pd.read_csv(io.StringIO(v), index_col=[0]) for k, v in wrk.items() }
但是請注意read_csv 的作業方式產生的副作用:
如果列名不是唯一的,那么Pandas會在這樣的“重復”列中添加一個點和連續的數字。
因此,例如結果中K2鍵的內容是:
Value Value.1 Value.2
M1 4 6 3
M2 7 3 4
M3 10 2 6
或者每個輸入“部分”中的實際列名可能不一樣?
總而言之,至少這段代碼允許您在讀取單個 DataFrame 時規避有關相同列數的限制。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/368369.html