我想改變我使用 networkD3 R 包制作的桑基圖,以便多個鏈接從一個節點流出,這是我到目前為止所做的:
隨機資料樣本的標題:
Study Category Class
<chr> <chr> <chr>
1 study17 cat H class B;class C
2 study32 cat A;cat B class A
3 study7 cat F class A
4 study21 cat F class C
5 study24 cat F class B;class C
6 study15 cat E;cat K class C
# example data
d <- read.csv(text = "Study,Category,Class
study17,cat H,class B;class C
study32,cat A;cat B,class A
study7,cat F,class A
study21,cat F,class C
study24,cat F,class B;class C
study15,cat E;cat K,class C")
使用此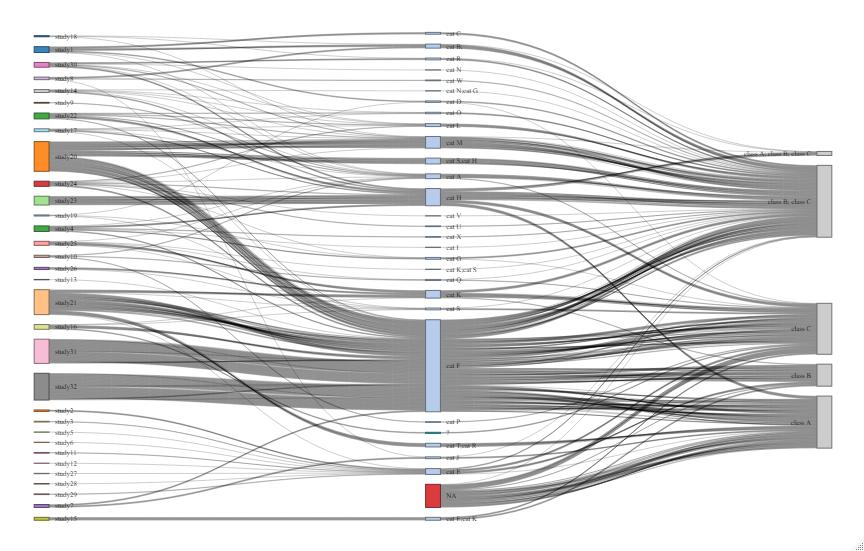
但是,正如您所看到的,第二列和第三列現在包括“復合節點”,例如“貓 A;貓 B”和“B 類;C 類”。
我想讓 2 個節點從研究 32 流出:一個到貓 A,一個到貓 B。同樣,我希望從貓 F(第 5 行)流出兩個節點:一個到 B 類,一個到 C 類。
從本質上講,我在問是否可以進行鏈接拆分之類的操作?我知道我可以定期拆分它們并為每個實體創建一個新行,但這會扭曲此影像中的事實..
uj5u.com熱心網友回復:
我們可以根據拆分更新矩形值的大小。這應該避免歪曲事實。
library(networkD3)
library(data.table)
setDT(d)
# make links
links <- rbind(d[, .(source = Study, target = Category) ],
d[, .(source = Category, target = Class) ])
links[, rn := .I]
# adjust value, based on "split"
links <- links[, strsplit(source, split = ";", fixed = TRUE), by = .(source, target, rn)
][, .(source = V1, target, rn)
][, strsplit(target, split = ";", fixed = TRUE), by = .(source, target, rn)
][, .(source, target = V1, rn)
][, .(source, target, value = 1/.N), by = rn]
# make nodes
nodes <- data.frame(name = unique(unlist(links[,.(source, target)])))
nodes$label <- nodes$name
# update link ids
links$source_id <- match(links$source, nodes$name) - 1
links$target_id <- match(links$target, nodes$name) - 1
# plot
sankeyNetwork(Links = links, Nodes = nodes, Source = 'source_id',
Target = 'target_id', Value = 'value', NodeID = 'label')
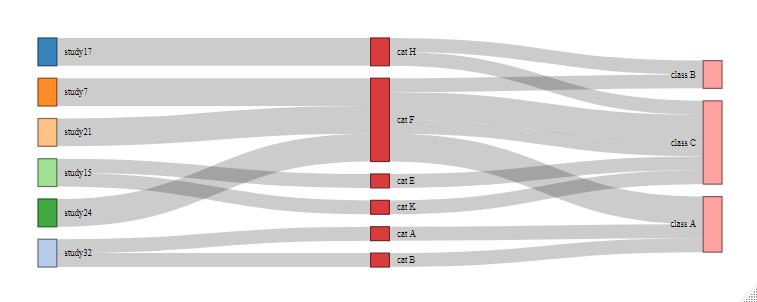
uj5u.com熱心網友回復:
我想這就是你已經做的......
library(dplyr)
library(tidyr)
library(networkD3)
data <- tibble::tribble(
~Study, ~Category, ~Class,
"study17", "cat H", "class B;class C",
"study32", "cat A;cat B", "class A",
"study7", "cat F", "class A",
"study21", "cat F", "class C",
"study24", "cat F", "class B;class C",
"study15", "cat E;cat K", "class C"
)
links <-
data %>%
mutate(row = row_number()) %>% # add a row id
pivot_longer(-row, names_to = "column", values_to = "source") %>% # gather all columns
mutate(column = match(column, names(data))) %>% # convert col names to col ids
group_by(row) %>%
mutate(target = lead(source, order_by = column)) %>% # get target from following node in row
ungroup() %>%
filter(!is.na(target)) %>% # remove links from last column in original data
mutate(source = paste0(source, '_', column)) %>%
mutate(target = paste0(target, '_', column 1)) %>%
select(source, target)
nodes <- data.frame(name = unique(c(links$source, links$target)))
nodes$label <- sub('_[0-9]*$', '', nodes$name) # remove column id from node label
links$source_id <- match(links$source, nodes$name) - 1
links$target_id <- match(links$target, nodes$name) - 1
links$value <- 1
sankeyNetwork(Links = links, Nodes = nodes, Source = 'source_id',
Target = 'target_id', Value = 'value', NodeID = 'label')
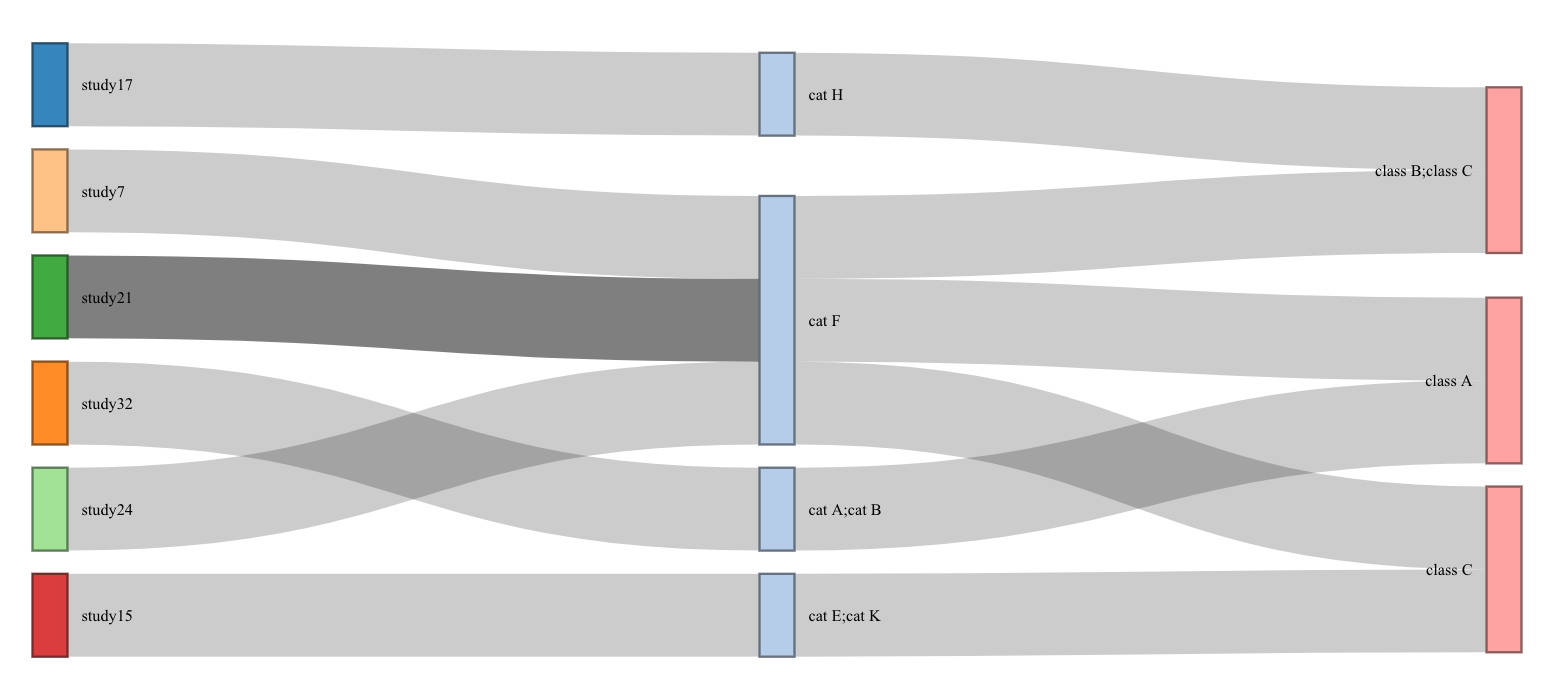
你可以像這樣重塑你的原始資料
data2 <- data %>% tidyr::separate_rows(everything(), sep = ";")
data2
#> # A tibble: 10 × 3
#> Study Category Class
#> <chr> <chr> <chr>
#> 1 study17 cat H class B
#> 2 study17 cat H class C
#> 3 study32 cat A class A
#> 4 study32 cat B class A
#> 5 study7 cat F class A
#> 6 study21 cat F class C
#> 7 study24 cat F class B
#> 8 study24 cat F class C
#> 9 study15 cat E class C
#> 10 study15 cat K class C
links <-
data2 %>%
mutate(row = row_number()) %>% # add a row id
pivot_longer(-row, names_to = "column", values_to = "source") %>% # gather all columns
mutate(column = match(column, names(data2))) %>% # convert col names to col ids
group_by(row) %>%
mutate(target = lead(source, order_by = column)) %>% # get target from following node in row
ungroup() %>%
filter(!is.na(target)) %>% # remove links from last column in original data
mutate(source = paste0(source, '_', column)) %>%
mutate(target = paste0(target, '_', column 1)) %>%
select(source, target)
nodes <- data.frame(name = unique(c(links$source, links$target)))
nodes$label <- sub('_[0-9]*$', '', nodes$name) # remove column id from node label
links$source_id <- match(links$source, nodes$name) - 1
links$target_id <- match(links$target, nodes$name) - 1
links$value <- 1
sankeyNetwork(Links = links, Nodes = nodes, Source = 'source_id',
Target = 'target_id', Value = 'value', NodeID = 'label')

轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/369332.html
上一篇:總結后如何考慮組內較大的日期
下一篇:R中資料框列的呼叫