java,從入土到出棺——2.資料結構(從容器(集合等)到底層原理)
- 1 資料結構
- 1.1 概述
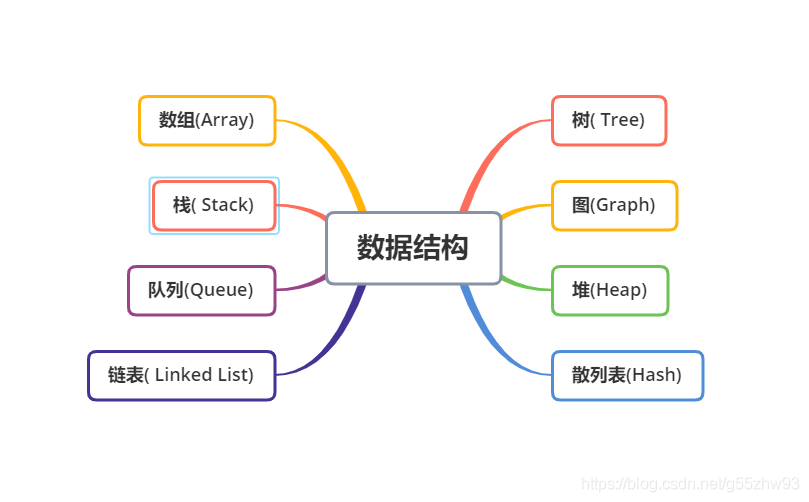
- 1.2 資料結構的種類
- 1.2.1 陣列(Array)
- 1.2.2 堆疊(Stack)
- 1.2.3 佇列(Queue)
- 1.2.4 鏈表(Linked List)
- 1.2.5 樹(Tree)
- 1.2.6 圖(Graph)
- 1.2.7 堆(Heap)
- 1.2.8 散串列(Hash)
- 2 常用集合
- 2.1 單列集合Collection
- 2.1.1 List
- 2.1.2 Set
- 2.1.3 Queue
- 2.2 雙列集合Map
- 2.2.1 HashMap
- 2.2.2 SortedMap
- 3 較常用集合家族圖
- 4 常用集合優缺點
- 5 常用集合底層原理
寫在前面:
??其實這個系列的文章更加偏向于總結向,是對以往一些知識做個系統的總結,也是為已經有一定基礎的人鋪路,提供一個系統的思考,
??對新人可能是很不友好的,可能有些人是剛接觸,上來就是組合代理的,建議新人上網先做個學習,再把我這個對比記憶,說不定還能發現我的錯誤呢,說不準哦,三人行,必有我師;如果想和我討論的,可以直接留言,也可以和我私信,我會很樂意和大家來討論的,
??同時也請大佬們不吝賜教!
1 資料結構
??這些最基礎的概念性問題還是有必要說一說的,基本的資料結構的分類掌握清楚,有助于理解第三部分的底層原理,所以雖然是總結性文章,但是這一章的內容還是較為瑣碎的,不耐煩的話可以直接跳到下面看集合的匯總以及集合底層原理的總結,拿好扯呼😄😄😄😄~~~~
1.1 概述
??資料結構是計算機存盤、組織資料的方式,這里有兩個重點,一個是儲存:畢竟我們計算機如果存盤不了資料,那也只是個一次性的物件,每次運算都去去源重新呼叫,計算的結果在沒法重復使用,就無法進行復雜的計算;另一個是組織:通過內在的邏輯將資料有序(并不只是常識認知上的有序)地存放,以便后期取用時可以更高效,對演算法提供大力的支持,
??資料基本的八種型別如下圖:
1.2 資料結構的種類
1.2.1 陣列(Array)
??陣列(Array)是有序的元素序列,陣列中的元素通過陣列下標進行訪問,陣列下標從0開始,存取有序,所以按照其下標(索引值)來查找資料是很快的,
??其長度是在初始化的時候就宣告了的,不可更改,這也就造成了陣列增刪困難,其特性也就限制了他的應用場景:頻繁查詢,很少增加和洗掉的情況,
??特別注意:
- 陣列是相同資料型別的元素的集合;
- 陣列中的各元素的存盤是有先后順序的,它們在記憶體中按照這個先后順序連續存放在一起;
- 陣列大小一經宣告不可改變,
??友情提醒:
??雖然陣列有不可改變長度的缺點,但是在有些地方用起來還是比較順手的,比如二維陣列(旋轉影像、楊輝三角),三維陣列等方面,陣列是不二之選,
1.2.2 堆疊(Stack)
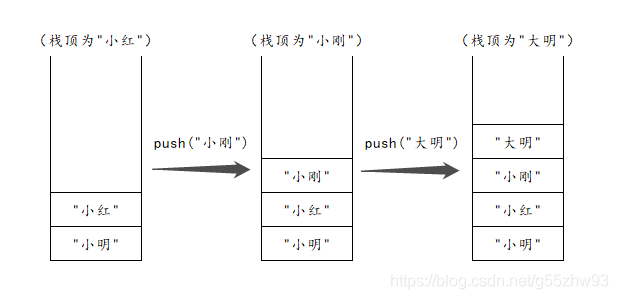
??堆疊是一種特殊的線性表,它只能在表的一端進行資料結點的插入和洗掉操作(即堆疊頂操作,堆疊底不允許操作),堆疊按照后進先出的原則來存盤資料,也就是說,先插入的資料將被壓入堆疊底(稱為壓堆疊),最后插入的資料在堆疊頂,讀出資料時,從堆疊頂開始逐個讀出(稱為彈堆疊),
??堆疊的儲存規則:
 ??堆疊的移除規則(后進先出,pop方法回傳取出的元素):
??堆疊的移除規則(后進先出,pop方法回傳取出的元素):
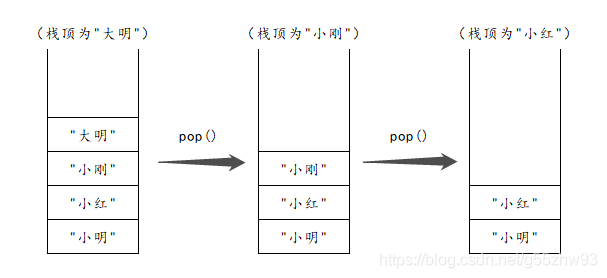
??特別注意:
- 堆疊是后進先出的,只能從堆疊頂呼叫資料;
??友情提醒:
- 由于堆疊的固有限制,一般不會見到單獨宣告stack的用法,一般都會采用ArrayDeque(Queue的子介面——Deque的實作類)來替代使用,畢竟更加高等(不像堆疊一樣從哪兒吃,從哪兒拉🤭🤭🤭🤭哈哈哈哈)
1.2.3 佇列(Queue)
??佇列是一種特殊的線性表,特殊之處在于它只允許在表的前端(front——洗掉指標)進行洗掉操作,而在表的后端(rear——添加指標)進行插入操作,和堆疊一樣,佇列是一種操作受限制的線性表,在佇列中插入一個佇列元素稱為入隊,從佇列中洗掉一個佇列元素稱為出隊,
??佇列的操作:
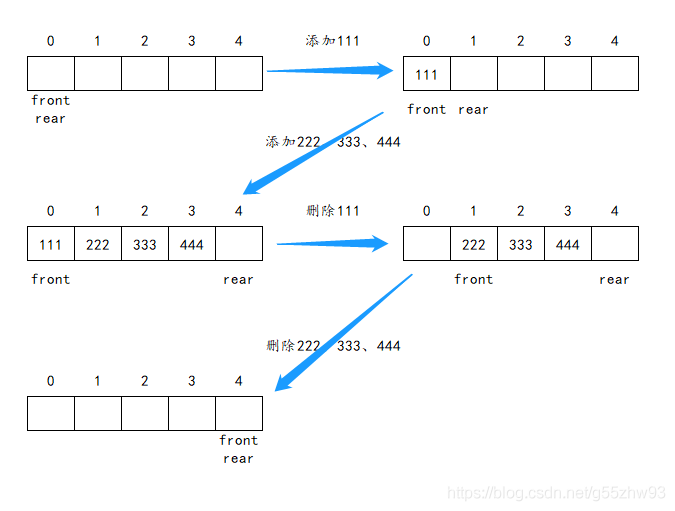
??特別注意:
- 佇列是先進先出的,只能尾部插入資料,頭部取出資料;
??友情提醒:
- 雖然佇列的限制是比較多的,但是他也為后來的新的類的產生提供了思路,ArrayDeque(Queue的子介面——Deque的實作類)便替代了堆疊和佇列,可以雙向存取資料,但是ArrayDeque插入元素不能為null,
1.2.4 鏈表(Linked List)
??鏈表是一種物理存盤單元上非連續、非順序的存儲結構,資料元素的邏輯順序是通過鏈表中的指標鏈接次序實作的,它由一系列結點(鏈表中每一個元素稱為結點)組成,每個結點包括兩個部分:一個是存盤資料元素的資料域,另一個是存盤下一個結點地址的指標域,鏈表有很多種不同的型別:單向鏈表,雙向鏈表以及回圈鏈表,使用鏈表結構可以克服陣列鏈表需要預先知道資料大小的缺點,鏈表結構可以充分利用計算機記憶體空間,實作靈活的記憶體動態管理,
??鏈表的表頭插入:
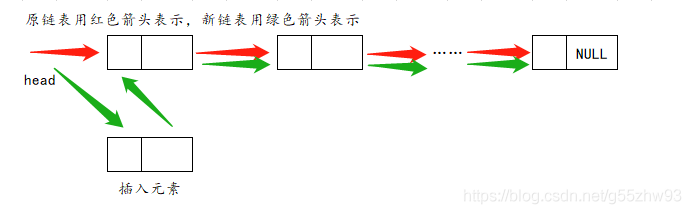
??鏈表的表中插入:
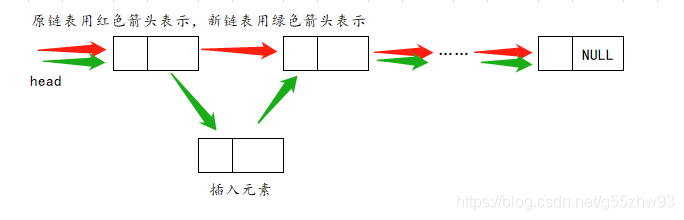
??鏈表的表尾插入:
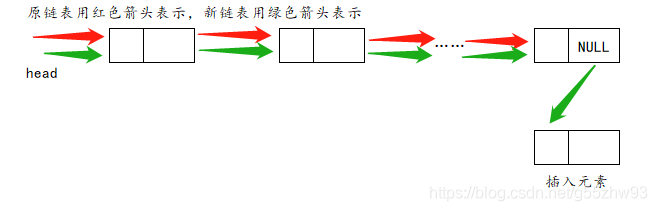
??特別注意:
- 相對于陣列來說,鏈表失去了陣列隨機讀取的優點,同時鏈表由于增加了結點的指標域,空間開銷比較大;
- 不允許隨機存取;
- 不需要初始化容量,可以任意加減元素;
- 查找元素需要遍歷鏈表來查找,非常耗時,
1.2.5 樹(Tree)
??樹是由n(n>=1)個有限結點組成一個具有層次關系的集合,把它叫做“樹”是因為它看起來像一棵倒掛的樹,也就是說它是根朝上,而葉朝下的,每個結點有零個或多個子結點;沒有父結點的結點稱為根結點;每一個非根結點有且只有一個父結點;除了根結點外,每個子結點可以分為多個不相交的子樹;
??樹的分類:
- 無序樹:樹中任意節點的子結點之間沒有順序關系,這種樹稱為無序樹,也稱為自由樹;
- 有序樹:樹中任意節點的子結點之間有順序關系,這種樹稱為有序樹;
- 二叉樹:每個節點最多含有兩個子樹的樹稱為二叉樹;
- 滿二叉樹:葉節點除外的所有節點均含有兩個子樹的樹被稱為滿二叉樹
- 完全二叉樹:有個節點的滿二叉樹稱為完全二叉樹
- 哈夫曼樹(最優二叉樹):帶權路徑最短的二叉樹稱為哈夫曼樹或最優二叉樹;
??二叉樹:
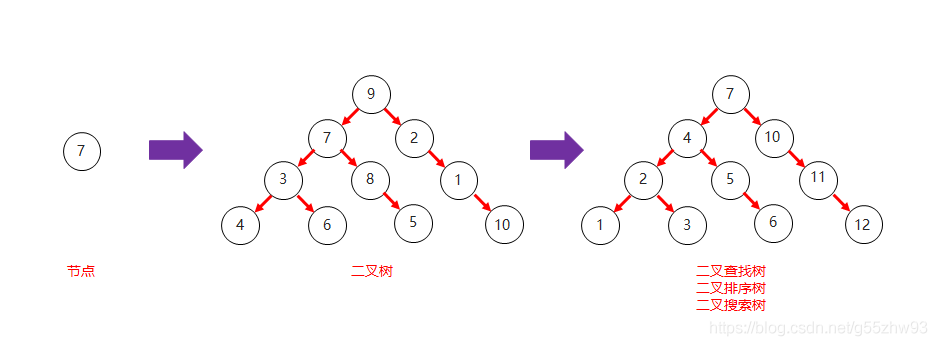
??紅黑樹:
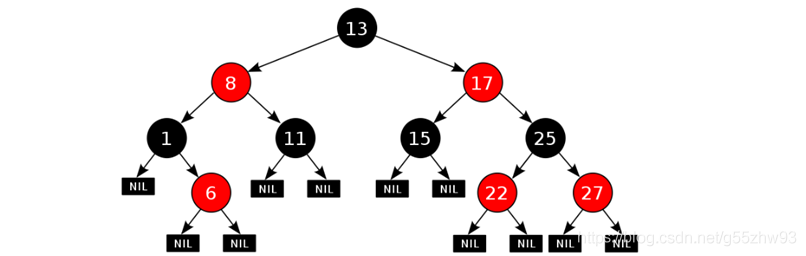
??特別注意:
- 二叉樹,紅黑樹這些常用的樹狀圖,會大大縮短需要遍歷的資料數量,節約查找時間;
- 相當于整合了陣列與鏈表的優點,可以處理大量的資料,
1.2.6 圖(Graph)
??圖(Graph)是另一種非線性資料結構,在圖結構中,資料結點一般稱為頂點,而邊是頂點的有序偶對,如果兩個頂點之間存在一條邊,那么就表示這兩個頂點具有相鄰關系,如果給圖的每條邊規定一個方向,那么得到的圖稱為有向圖,在有向圖中,與一個節點相關聯的邊有出邊和入邊之分,相反,邊沒有方向的圖稱為無向圖,
??特別注意:
- 圖的遍歷方法有深度優先搜索法和廣度(寬度)優先搜索法,
1.2.7 堆(Heap)
??堆(Heap)是計算機科學中一類特殊的資料結構的統稱,堆通常是一個可以被看做一棵完全二叉樹的陣列物件,
??特別注意:
- 堆中某個節點的值總是不大于或不小于其父節點的值;
- 堆是一棵完全二叉樹
1.2.8 散串列(Hash)
??散串列(Hash table,也叫哈希表),是根據關鍵碼值(Key value)而直接進行訪問的資料結構,也就是說,它通過把關鍵碼值映射到表中一個位置來訪問記錄,以加快查找的速度,這個映射函式叫做散列函式,存放記錄的陣列叫做散串列,如下圖,陣列中實作鏈表的儲存,是實作散串列的關鍵:
??散串列:
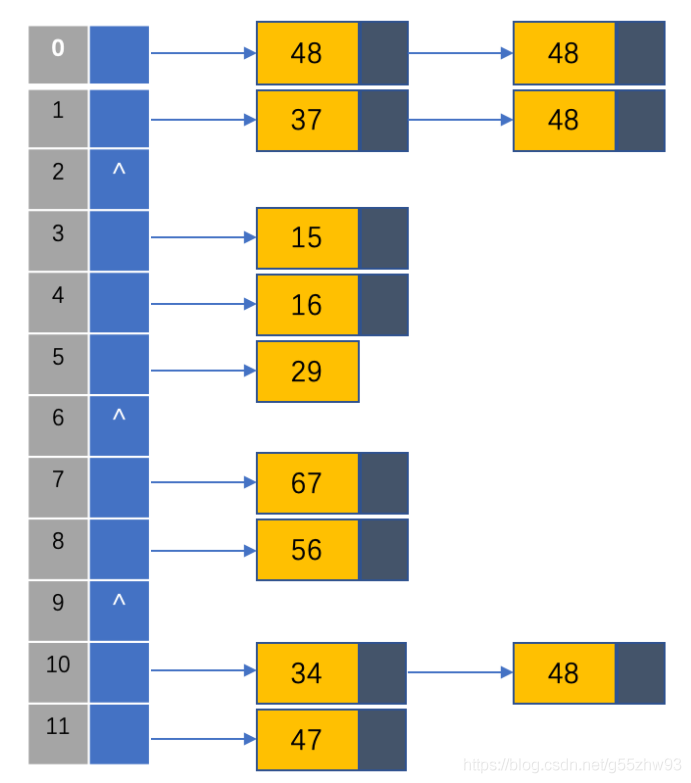
??特別注意:
- 使用散串列一定要注意哈希沖突的問題;
- 查找程序中,關鍵碼的比較次數,取決于產生沖突的多少,產生的沖突少,查找效率就高,產生的沖突多,查找效率就低
2 常用集合
??這一段不再進行概念的匯總,主要列出集合中的一些常用介面以及實作類,理清關系,嫌字看著迷可以直接看圖,然后會列出部分常用集合的優缺點以及應用環境,對于某單個集合的概念性問題,可以直接問我或者查看別人的文章,還是那句話,主要是做個匯總,以便復習,溫故知新~~
??一些不常用的(比如:ConcurrentSkipListSet執行緒安全的有序的集合、EnumSet列舉集合、DelayQueue延遲佇列、SynchronousQueue同步佇列、RoleList角色串列、RoleUnresolvedList(RoleUnresolved 物件串列)、AttributeList屬性串列等)就沒有列出來,感興趣的可以結合原始碼以及API幫助檔案自己進行查詢鞏固,
2.1 單列集合Collection
??單列集合中用的最多的就是List的實作類以及Set的實作類了,所以對于這兩點稍微展開說一下,對于佇列可以了解一個ArrayDeque,有興趣的可以對于其他的介面以及抽象方法做具體的了解學習,
2.1.1 List
①ArrayList
??ArrayList實作了List的介面,繼承自AbstractList,其中間接實作的介面或繼承有:AbstractCollection抽象類、Collection介面、Iterable介面(復制以及序列化介面不在討論范圍內,下面所有的類均是如此),通過名字可以看出來,其底層是通過Array陣列實作的,并且其實作了Iterable介面,是可以用迭代器進行創建Iterator物件,進而遍歷操作,創建時不需要指定容量,
??特別注意:
- 如果多個執行緒同時訪問一個 ArrayList 實體,而其中至少一個執行緒從結構上修改了串列,那么它必須 保持外部同步,解決方法:使用 Collections.synchronizedList 方法將該串列“包裝”起來,這最好在創建時完成,以防止意外對串列進行不同步的訪問:List list = Collections.synchronizedList(new ArrayList(…));
②LinkedList
??LinkedList實作了List和Deque介面,繼承自AbstractSequentialList,其中間接實作的介面或繼承有:AbstractList抽象類、AbstractCollection抽象類、Queue介面、Collection介面、Iterable介面,底層資料結構是鏈表,
??特別注意:
- 與ArrayList特別注意相同,
③Vector
??Vector實作了List介面,繼承自AbstractList,其中間接實作的介面或繼承有:AbstractCollection抽象類、Collection介面、Iterable介面,Vector 類可以實作可增長的物件陣列,與陣列一樣,它包含可以使用整數索引進行訪問的組件,但是,Vector 的大小可以根據需要增大或縮小,以適應創建 Vector 后進行添加或移除項的操作,
④Stack
??前文已經說明,stack在作為元素容器使用時,限制太多了,已經被ArrayDeque取代,這里不再說明,
2.1.2 Set
①HashSet
??HashSet實作了Set介面,繼承自AbstractSet,其中間接實作的介面或繼承有:AbstractCollection抽象類、Collection介面、Iterable介面,此類允許使用 null 元素,HashSet的底層通過HashMap實作的,而HashMap在1.7版本之前之前使用的是陣列+鏈表實作,在1.8版本之后使用的陣列+鏈表+紅黑樹實作,HashSet的底層實作和HashMap使用的是相同的方式,HashSet也無法保證順序,
??特別注意:
- 執行緒不同步;
②LinkedHashSet
??LinkedHashSet實作了Set介面,繼承自HashSet,其中間接實作的介面或繼承有:AbstractSet抽象類、AbstractCollection抽象類、Collection介面、Iterable介面,LinkedHashSet具有可預知迭代順序的 Set 介面的哈希表和鏈接串列實作,此實作與 HashSet 的不同之外在于,后者維護著一個運行于所有條目的雙重鏈接串列,
??特別注意:
- 執行緒不同步;
③TreeSet
??TreeSet實作了NavigableSet介面,繼承自AbstractSet,其中間接實作的介面或繼承有:AbstractCollection抽象類、SortedSet介面、Set介面、Collection介面、Iterable介面,TreeSet基于 TreeMap 的 NavigableSet 實作,使用元素的自然順序對元素進行排序,或者根據創建 set 時提供的 Comparator 進行排序,具體取決于使用的構造方法,
??特別注意:
- 執行緒不同步;
- 如果想把自定義類的物件存入TreeSet進行排序, 那么必須實作Comparable介面,
2.1.3 Queue
①ArrayDeque
??ArrayDeque實作了Deque介面,繼承自AbstractCollection,其中間接實作的介面或繼承有:Queue介面、Collection介面、Iterable介面,ArrayDeque是Deque 介面的大小可變陣列的實作,陣列雙端佇列沒有容量限制;它們可根據需要增加以支持使用,它們不是執行緒安全的;在沒有外部同步時,它們不支持多個執行緒的并發訪問,禁止 null 元素,此類很可能在用作堆疊時快于 Stack,在用作佇列時快于 LinkedList,
??特別注意:
- 執行緒不同步;
2.2 雙列集合Map
2.2.1 HashMap
①HashMap
??HashMap實作了Map介面,繼承自AbstractMap抽象類(復制以及序列化介面不在討論范圍內,下面所有的類均是如此,HashMap提供所有可選的映射操作,并允許使用 null 值和 null 鍵,(除了非同步和允許使用 null 之外,HashMap 類與 Hashtable 大致相同,)此類不保證映射的順序,特別是它不保證該順序恒久不變,HashMap 的實體有兩個引數影響其性能:初始容量 和加載因子,通常,默認加載因子 (0.75) 在時間和空間成本上尋求一種折衷,加載因子過高雖然減少了空間開銷,但同時也增加了查詢成本 ,
??特別注意:
- 一般通過對自然封裝該映射的物件進行同步操作來完成,如果不存在這樣的物件,則應該使用 Collections.synchronizedMap 方法來“包裝”該映射,最好在創建時完成這一操作,以防止對映射進行意外的非同步訪問: Map m = Collections.synchronizedMap(new HashMap(…));
- JDK1.8在JDK1.7的基礎上針對增加了紅黑樹來進行優化,即當鏈表超過8時,鏈表就轉換為紅黑樹,利用紅黑樹快速增刪改查的特點提高HashMap的性能,其中會用到紅黑樹的插入、洗掉、查找等演算法,
②LinkedHashMap
??LinkedHashMap實作了Map介面,繼承自HashMap,其中間接實作的介面或繼承有:AbstractMap抽象類,與 HashMap 的不同之處在于,后者維護著一個運行于所有條目的雙重鏈接串列,提供了AccessOrder引數,用來指定LinkedHashMap的排序方式,遍歷的時候會比HashMap慢(因為linkedhashmap需要保存插入的順序屬于需要額外開銷),不過,當HashMap容量很大,實際資料較少時,遍歷起來可能會比LinkedHashMap慢,因為LinkedHashMap的遍歷速度只和實際資料有關,和容量無關,而HashMap的遍歷速度和他的容量有關,
??特別注意:
- 一般通過對自然封裝該映射的物件進行同步操作來完成,如果不存在這樣的物件,則應該使用 Collections.synchronizedMap 方法來“包裝”該映射,最好在創建時完成這一操作,以防止對映射進行意外的非同步訪問: Map m = Collections.synchronizedMap(new LinkedHashMap(…));
- 輸出的順序和輸入的相同,
2.2.2 SortedMap
①TreeMap
??TreeMap實作了NavigableMap(基于紅黑樹(Red-Black tree))介面,繼承自AbstractMap抽象類,其中間接實作的介面或繼承有:SortedMap介面、Map介面,TreeMap根據其鍵的自然順序進行排序,或者根據創建映射時提供的 Comparator 進行排序,具體取決于使用的構造方法,
??特別注意:
- 一般通過對自然封裝該映射的物件進行同步操作來完成,如果不存在這樣的物件,則應該使用 Collections.synchronizedSortedMap 方法來“包裝”該映射,最好在創建時完成這一操作,以防止對映射進行意外的非同步訪問: SortedMap m = Collections.synchronizedSortedMap(new TreeMap(…));
- 如果想把自定義類的物件存入TreeMap進行排序, 那么必須實作Comparable介面,
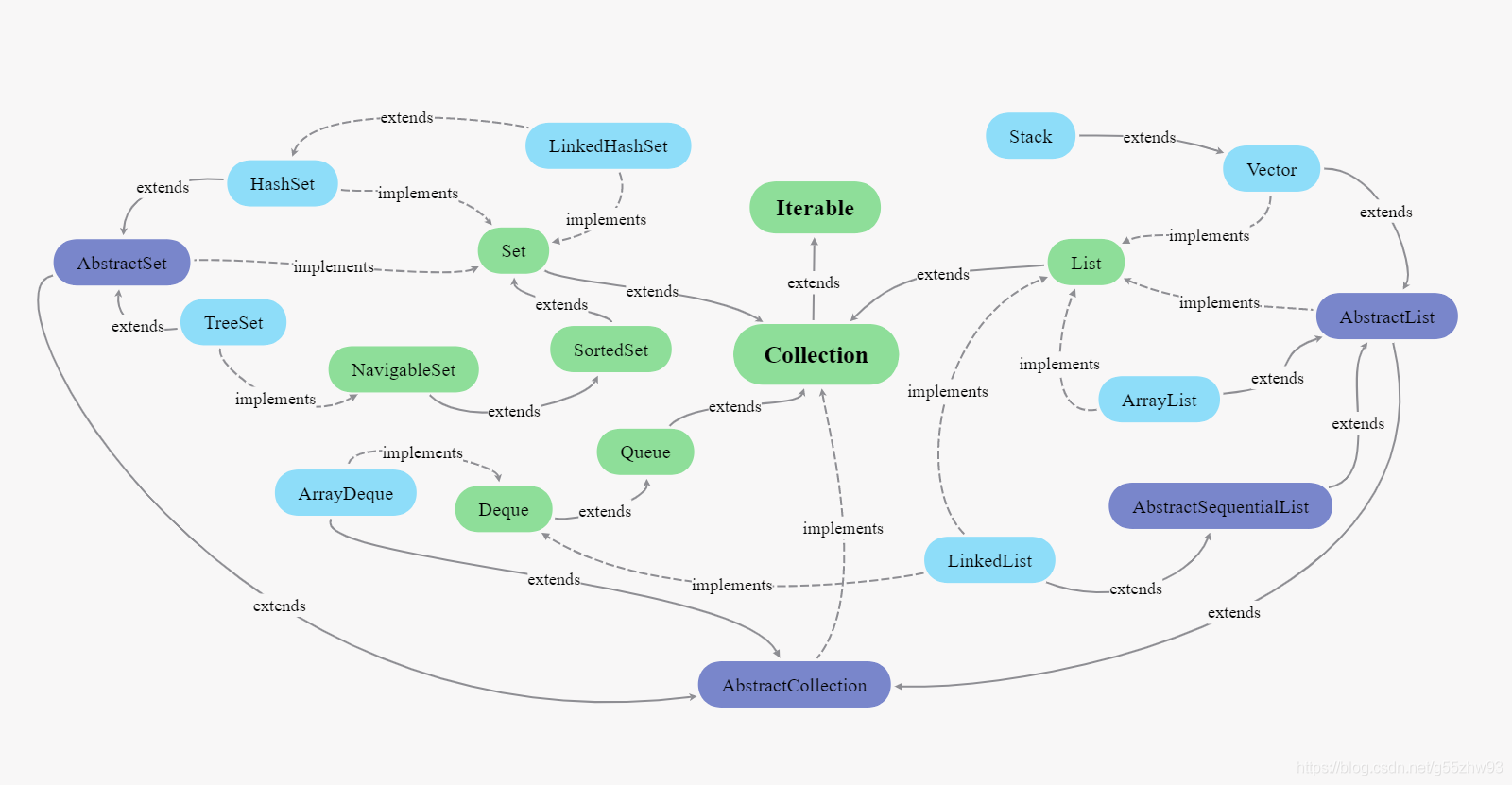
3 較常用集合家族圖
??單列集合Collection家族圖:
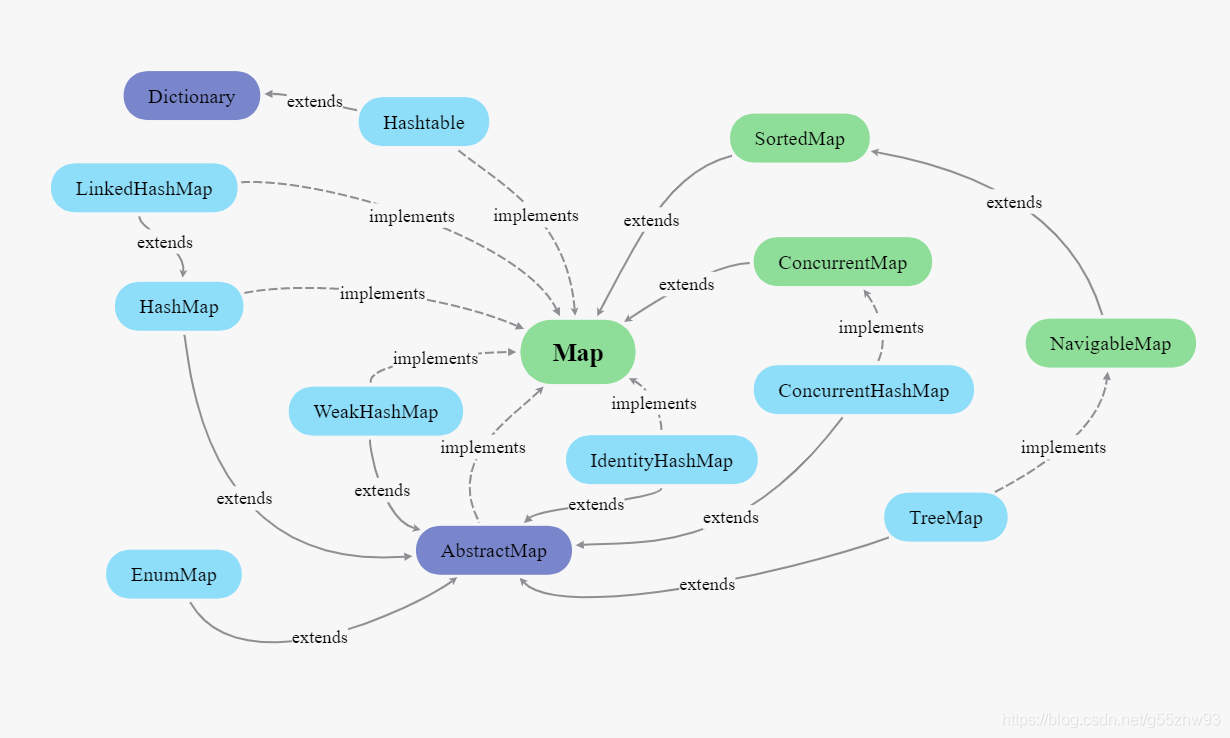
??雙列集合Map家族圖:
4 常用集合優缺點
??單列集合Collection:
| 好處 | 弊端 | 使用頻率 | |
|---|---|---|---|
| ArrayList | ①可以自動擴容(相對于陣列來說,所有集合共性,以下不再重復列出) ②根據下標訪問、遍歷元素效率較高 ③在陣列的基礎上封裝了對元素操作的方法 | ①執行緒不安全 ②插入和洗掉的效率比較低 ③根據內容查找元素的效率較低 | 常用 |
| LinkedList | ①比ArrayList效率高 ②洗掉和添加資料所消耗的資源比ArrayList少 | ①執行緒不安全 ②查找消耗的資源大 ③不支持高效的隨機元素訪問 | 常用 |
| Vector | ①執行緒安全 ②隨機訪問方便,即支持[ ]運算子和vector.at() ②不指定一塊記憶體大小的陣列的連續存盤,可以進行動態操作, | ①在內部進行插入洗掉操作效率低 ②只能在vector的尾部進行push和pop,不能在vector的頭進行push和pop ③當動態添加的資料超過vector默認分配的大小時要進行整體的重新分配、拷貝與釋放 | sun推薦使用ArraList來取代vector |
| HashSet | ①可以去除重復元素 ②查詢和洗掉和增加元素的效率高 | ①執行緒不安全 ②不能保證元素的順序,元素是無序的(指的是存取無序,其實也不能算劣勢) ③會浪費許多無用的空間 | 常用 |
| LinkedHashSet | ①有序(存取有序) ②可以去除重復元素 ③查詢和洗掉和增加元素的效率高 | ①執行緒不安全 ②會浪費許多無用的空間 | 常用 |
| TreeSet | ①有序(存取無序,但是指定規則排序) ②可以去除重復元素 ③查詢和洗掉和增加元素的效率高 | ①執行緒不安全 ②資源消耗高 | 較常用,一般是喲個HashSet,除非要求排序 |
| ArrayDeque | ①既可以當堆疊使用,也可以當佇列使用;當用作堆疊時,性能優于Stack,當用于佇列時,性能優于LinkedList ②兩端插入和洗掉效率比陣列高,其是一個回圈陣列 | ①執行緒不安全 ②不能儲存NULL ③相對于stack兩端都可以操作,但是相對于其他集合,依然是劣勢 ④根據元素內容查找和洗掉的效率較低,沒有位置索引的概念 | 一般 |
??雙列集合Map:
| 好處 | 弊端 | 使用頻率 | |
|---|---|---|---|
| HashMap | ①可以自動擴容(相對于陣列來說,所有集合共性,以下不再重復列出) ②隨機訪問資料速度快 | ①執行緒不安全 ②需要額外計算一次hash值 ③遍歷速度慢(相對于List與Set) | 常用 |
| LinkedHashMap | ①有序(存取有序) ②隨機訪問資料速度快 | ①執行緒不安全 ②資料較少時,遍歷速度比HashMap還慢 | 常用 |
| TreeMap | ①有序(存取無序,但是指定規則排序) ②可以去重 | ①執行緒不安全 ②查詢效率低 | 較常用 |
5 常用集合底層原理
??這一段也不再進行概念的匯總,直接表格奉上,白嫖黨的勝利,哈哈哈😄😄😄😄,
| 底層結構 | 特殊說明 | |
|---|---|---|
| ArrayList | 陣列 | |
| LinkedList | 雙向鏈表 | JDK1.6 之前為雙向回圈鏈表,JDK1.7 取消了回圈 |
| Vector | 陣列 | |
| HashSet | HashMap | 底層采用 HashMap 來保存元素 |
| LinkedHashSet | LinkedHashMap | |
| TreeSet | 紅黑樹 | |
| ArrayDeque | 佇列 | ①實作回圈陣列 ② ③ |
| HashMap | 哈希表 | 即陣列+鏈表組成,Java 8版本以后當鏈表長度大于閾值(默認為8)時,則鏈表變成紅黑樹 |
| LinkedHashMap | 哈希表+雙向鏈表 | 加一條雙向鏈表,使得整體結構可以保持鍵值對的插入順序,同時通過對鏈表進行相應的操作,實作了訪問順序的相關邏輯 |
| TreeMap | 紅黑樹 |
PS
??這篇文章因為太忙了,比承諾的時間晚了兩天,再次向期待的朋友們表示歉意,
??文章有些倉促,也許有些錯誤,希望朋友們直接指出,
??有不了解的先動手自己查查,實在不明白了來問我,不是裝13,而是這樣大家自己搜索只是并且整合知識的能力才會增強,我是真的不支持白嫖,原因就是這會影響大家的學習態度,不過來問我我是來者不拒的,😄😄
??再次謝謝大家支持!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/37328.html
標籤:其他