哈希表
- 一、哈希表原理
- 二、哈希表的概念
- 三、哈希化沖突問題
- 1、鏈地址法
- 2、開放地址法
- 1、線性探索
- 2、二次探索
- 3、再哈希法
- 四、哈希函式的實作
- 五、封裝哈希表
- 六、哈希表操作
- 1、插入&修改操作
- 2、獲取操作
- 3、洗掉操作
- 4、判斷哈希表是否為空
- 5、獲取哈希表的元素個數
- 七、哈希表擴容
- 1、哈希表擴容思想
- 2、哈希表擴容實作
- 八、完整代碼
一、哈希表原理
哈希表是一種非常重要的資料結構,幾乎所有的編程語言都有直接或者間接的應用這種資料結構,它通常是基于陣列實作的,當時相對于陣列,它有更多的優勢:
- 它可以提供非常快速的插入-洗掉-查找操作,
- 哈希表的速度比數還要快,基本可以瞬間查找到想要的元素
- 哈希表相對于數來說編碼要容易的多,
但是哈希表相對于陣列也有一些不足:
- 哈希表中的陣列是沒有順序的,所以不能以一種固定的方式(比如從小到大)來遍歷其中的元素,
- 通常情況下,哈希表中的key是不允許重復的,不能放置相同的key,用于保存不同的元素,
那么,哈希表到底是什么呢?
它的結構是陣列,但是神奇的地方在于對下標值的一種變換,這種變換我們可以稱之為哈希函式,通過哈希函式可以獲得到HashCode,
接下來,我們可以來看一個例子:
使用一種資料結構來存盤單詞資訊,比如有50000個單詞,找到單詞后每個單詞有自己的具題應用等等,我們應該怎樣操作呢?
或許我們可以嘗試將字母轉化成合適的下標,但是怎樣才能將一個字符轉化成陣列的下標值呢?有沒有一種方案,可以將單詞轉化成陣列的下標值呢?如果單詞轉化為陣列的下標,以后如果我們要查找某個單詞的資訊,直接按照下標值一步即可訪問到想要的元素,那么怎樣將字串轉化為下標值呢?
其實計算機有很多的編碼方案就是用數字代替單詞的字符,就是字符編碼,當然, 我們可以設計自己的編碼系統,比如a是1,b是2,c是3等等,但是有了編碼系統以后,一個單詞如何轉化成數字呢?
在這里,我們有兩種方案:
方案一:數字相加
一種轉換單詞的簡便方法就是把單詞每個字符的編碼求和
例如單詞cats轉成數字:3+1+20+19=43,那么43就作為cats單詞下標存在陣列中
但是按照這種方案有一個很明顯的問題就是很多單詞最終的下標可能都是43
我們知道陣列中一個下標值位置只能存盤一個資料,如果存入后來的資料,必然會造成資料的覆寫,故而,一個下標存盤這么多單詞顯然是不合理的,
方案二:冪的連乘
其實我們平時用的大于10的數字,就可以用冪的連乘來表示其唯一性,比如:6543 = 6 *103+5 *102+4 *10 + 4
我們的單詞也可以使用這種方案來表示,比如cats = 3 * 273+1 * 272 + 20 * 27+17 = 60337
這樣得到的數字可以基本保證其唯一性,不會和別的單詞重復,
但是存在一個問題,如果一個單詞是zzzzzzzzzz.那么得到的數字超過7000000000000.陣列不一定能夠表示這么大的下標值,就算能夠創建這么大的陣列,事實上有很多的無效單詞,并沒有意義,
兩種方案總結:
第一種方案(把數字相加求和)產生的陣列下標太少,第二種方案(與27的冪相乘求和)產生的陣列下標又太多,
所以現在需要一種壓縮方法,把冪的連乘方案系統中得到的巨大整數范圍壓縮到可接收的陣列范圍中,有一種簡單的方法就是使用取余運算子,他的作用是得到一個數被另一個數整除后的余數,
取余操作的實作:(0-199之間的數字)
- 假設把從0-199的數字,(large),壓縮為0-9的數字(small)
- 下標的結果index = large % small
- 當一個數被10整除時,余數一定在0-9之間
- 例如16%10 = 6,23%10 = 3
- 這中間還是會有重復,不過重復的數量明顯小了,比如說在0-199中間取5個數字,放在一個長度為10的陣列,也會重復,但是重復的概率非常小,
二、哈希表的概念
了解了哈希化的原理,我們就可以來看幾個概念:
哈希化:將大數字轉化為陣列范圍內下標的程序,就稱之為哈希化
哈希函式:例如將單詞轉化為大數字,大數字在進行哈希化的代碼實作放在一個函式中,這個函式就是哈希函式,
哈希表:最終將資料插入到這個陣列,對整個結構的封裝,就可以稱之為一個哈希表,
三、哈希化沖突問題
前面提到了,通過哈希化的下標值依然可能會重復,就會導致沖突,比如說我們將0-199的數字選取5個放在長度為10的單元格里,如果我們隨機選出來的是33,45,27,86,92,那么最終他們的位置會是3-5-7-6-2,沒有發生沖突,但是其中如果還有一個86,一個66呢?此時就會發生沖突,該如何解決這個問題呢?
常用的解決方案有兩種:
1、鏈地址法
鏈地址法是一種比較常見的解決沖突的方案(也稱拉鏈法)
如下圖所示:
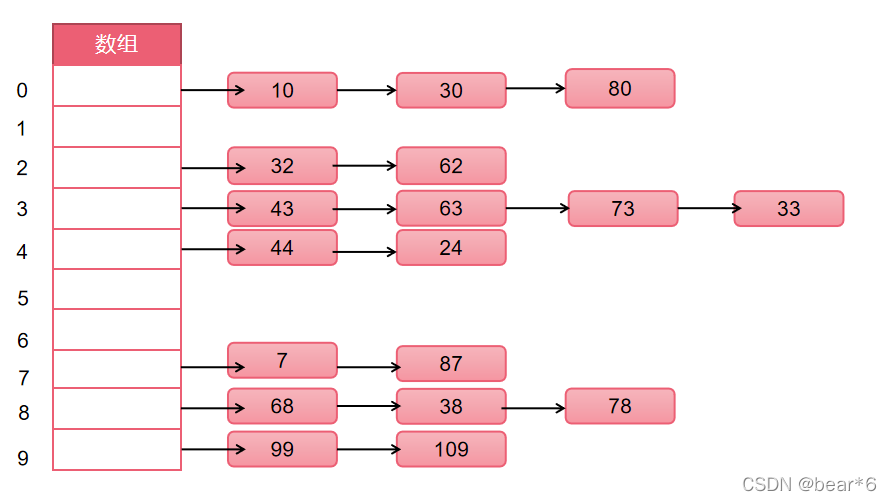
創建了一個記憶體為10的陣列,現在,需要將一些數字存到陣列內部,這些數字哈希化后可能會重復,將下標值相同的數通過鏈表或者陣列鏈接起來的方法叫做鏈地址法,當我們要查找某值的時候,就可以先根據其下標找到對應的鏈表或者陣列再在其內部尋找,
從圖片中,我們可以看出,鏈地址法解決沖突的辦法是每個陣列單元中存盤的不再是單個資料而是一個鏈條,這個鏈條常用的結構是陣列或者鏈條,那在具體應用中應該采用哪一種方式呢?其實這兩種方法都可以,效率上也差不多,當然在某些實作中,會將新插入的資料放在陣列或者鏈表的最前面,這種情況最好用鏈表,因為陣列再首位插入資料是需要所有其他項后移的的,而鏈表就沒有這樣的問題,
2、開放地址法
開放地址法的主要作業方式是尋找空白的單元格來添加重復的資料,如下圖所示:

如果有一個數字32,現在要將其插入到陣列中,我們的解決方案為:
- 新插入的32本來應該插入到52的位置,但是該位置已經包含資料,
- 可以發現3、5、9的位置是沒有任何內容的
- 這個時候就可以尋找對應的空白位置來放這個資料
但是探索這個位置的方式不同,有三種方式:
1、線性探索
即線性的查找空白單元
插入32
- 經過哈希化得到的index=2,但是在插入的時候,發現該位置已經有52
- 此時就從index+1的位置開始一點點查找合適的位置來放置32
- 探測到的第一個空的位置就是該值插入的位置
查詢32
- 首先經過哈希化得到index= 2,比較2的位置結果和查詢的數值是否相同,相同則直接回傳
- 不相同則線性查找,從index位置+1查找和32一樣的,
需要注意的是:如果32的位置之前沒有插入,并不需要將整個哈希表查詢一遍來確定該值是否存在,而是如果查詢到空位置,就停止,因為32之前不可能跳過空位置去其他的位置,
線性探測也有一個問題就是:如果之前插入的資料是連續插入的,則新插入的資料就需要很長的探測距離,
2、二次探索
二次探索就在線性探索的基礎上進行了優化,
線性探測,我們可以看做是步長為1的探測,比如從下標值x開始,從x+1,x+2,x+3依次探測,
二次探測對步長做了優化,比如從下標值x開始,x+12,x+22,x+32依次探測,
但是二次探測依然存在問題:比如我們連續插入的是32-112-82-42-52,那么他們依次累加的時候步長是相同的,也就是這種情況下會造成步長不一的一種聚集,還是會影響效率,怎樣解決這個問題呢?來看看再哈希法,
3、再哈希法
再哈希法的做法就是:把關鍵字用另一個哈希函式在做一次哈希化,用這次哈希化的結果作為步長,對于指定的關鍵字,步長在整個探測中是不變的,不同的關鍵字使用不同的步長,
第二次哈希化需要具備以下特點:
- 和第一個哈希函式不同
- 不能輸出為0(否則,將沒有步長,每次嘆詞都是原地踏步,演算法進入死回圈)
而計算機專家已經設計好了一種作業很好的哈希函式,
stepSize = constant - (key % constant)
其中constant是質數,且小于陣列的容量,key是第一次哈希化得到的值,
例如:stepSize = 5-(key%5),滿足需求,并且結果不可能為0,
四、哈希函式的實作
哈希表的主要優點在于它的速度,提高速度的一個方法就是讓哈希函式中有盡量少的乘法和除法,設計好的哈希函式需要具備以下優點:
(1)快速的計算
(2)均勻的分布
來具體實作一下:
首先我們所實作的哈希函式最主要的操作是:將字符創轉化為比較大的數字和將大的數字壓縮到陣列范圍之內,如下所示:
function hashFunc(str,size){
//定義hashCode變數
var hashCode = 0;
//根據霍納演算法,計算hashCode的值
//先將字串轉化為數字編碼
for(var i =0;i<str.length;i++){
hashCode = 37*hashCode + str.charCodeAt(i)
}
//取余操作
var index = hashCode % size;
return index;
}
代碼測驗:
console.log( hashFunc('abc',7));
console.log( hashFunc('cba',7));
console.log( hashFunc('nba',7));
console.log( hashFunc('rgt',7));
測驗結果為:
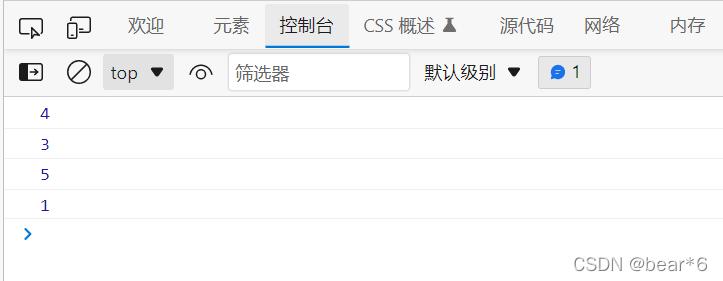
可以發現我們得到的字串對應的下標值分布還是很均勻的,
五、封裝哈希表
這里我將采用鏈地址法來實作哈希表:
其中定義了三個屬性:
storage:作為陣列,存放相關元素count:記錄當前已存放的資料量
-limit:標記陣列中一共可以存放多少資料
實作的哈希表(基于storage的陣列)每個index對應的是一個陣列(bucket),bucket里面存放的是(key和value),最終哈希表的資料格式是:[[[k,v],[k,v],[k,v],[[k,v],[k,v]],[k,v]]
如下圖所示:

代碼如下:
function HashTable(){
// 定義屬性
this.storage = [];
this.count = 0;
this.limit = 8;
}
在將我們前面封裝好的哈希函式通過原型添加進去:
function HashTable(){
// 定義屬性
this.storage = [];
this.count = 0;
this.limit = 8;
HashTable.prototype.hashFunc = function(str,size){
//定義hashCode變數
var hashCode = 0;
//先將字串轉化為數字編碼
for(var i =0;i<str.length;i++){
hashCode = 37*hashCode + str.charCodeAt(i)
}
//取余操作
var index = hashCode % size;
return index;
}
}
六、哈希表操作
1、插入&修改操作
哈希表的插入和修改操作是同一個函式,因為當使用者傳入一個<key,value>時,如果原來不存在該key,那么就是插入操作,如果已經存在該key,對應的就是修改操作,
具體實作思路為:先根據傳入的key獲取對應的hashCode,即陣列的index,接著從哈希表的Index位置中取出另一個陣列(bucket),查看上一步的bucket是否為空,如果為空的話,表示之前在該位置沒有放置過任何的內容,則新建一個陣列[];再查看是否之前已經放置過key對應的value,如果放置過,那么就是依次替換操作,而不是插入新的資料,如果不是修改操作的話,那么插入新的資料,并且讓資料項加1,
實作代碼為:
//插入和修改操作
HashTable.prototype.put = function(key,value){
//根據key獲取對應的index
var index = this.hashFunc(str,this.limit);
//根據index取出對應的bucket
var bucket = this.storage[index];
//如果值為空,給bucket賦值一個陣列
if(bucket === null){
bucket = [];
this.storage[index] = bucket;
}
//判斷是否是修改資料
for(let i =0;i<bucket.length;i++){
var tuple = bucket[i];
if(tuple[0] === key){
tuple[1] = value;
return;
}
}
//進行添加操作
bucket.push([key,value]);
this.count += 1;
}
測驗代碼:
ht.put('a',12)
ht.put('b',67)
ht.put('c',88)
ht.put('d',66)
console.log('ht',ht);
列印結果為:
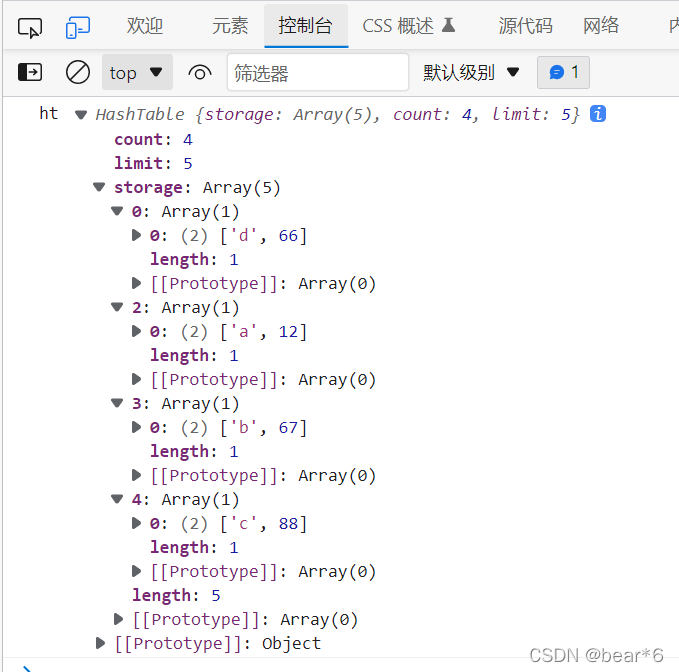
測驗成功
2、獲取操作
首先根據key獲取對應的index,在根據對應的index獲取對應的bucket;判斷bucket是否為空,如果為空,回傳null,否則,線性查找bucket中的key和傳入的key是否相等,如果相等,直接回傳對應的value值,否則,直接回傳null,
實作代碼為:
HashTable.prototype.get = function(key){
//根據key獲取對應的index
var index = this.hashFunc(key,this.limit);
//根據index獲取對應的bucket
var bucket = this.storage[index];
//判斷是否為空
if(bucket == null){
return null;
}
//線性查找
for(let i = 0;i<bucket.length;i++){
var tuple = bucket[i];
if(tuple[0] === key){
return tuple[1];
}
}
return null;
}
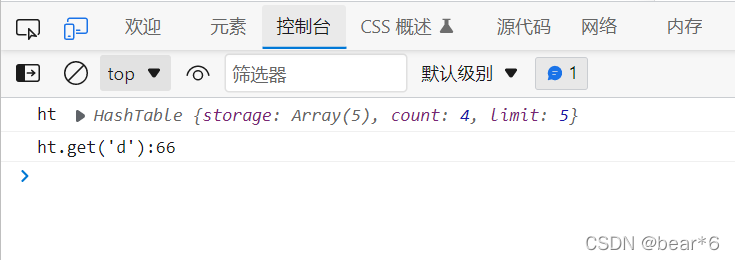
測驗代碼:比如回去key為d的元素的值
console.log("ht.get('d'):"+ht.get('d'));
3、洗掉操作
方法和獲取操作的方法相似,首先根據key獲取對應的index,在根據對應的index獲取對應的bucket;判斷bucket是否為空,如果為空,回傳null,否則,線性查找bucket中的key和傳入的key是否相等,如果相等,則進行洗掉,否則,直接回傳null,
HashTable.prototype.remove = function(key){
//根據key獲取對應的index
var index = this.hashFunc(key,this.limit);
//根據index獲取對應的bucket
var bucket = this.storage[index];
//判斷是否為空
if(bucket == null){
return null;
}
//線性查找并通過splice()洗掉
for(let i =0;i<bucket.length;i++){
var tuple = bucket[i];
if(tuple[0] === key){
bucket.splice(i,1);
this.count -= 1;
return tuole[1];
}
}
return null;
}
測驗代碼:洗掉key為b的元素
console.log("ht.remove('b'):"+ht.remove('b'));
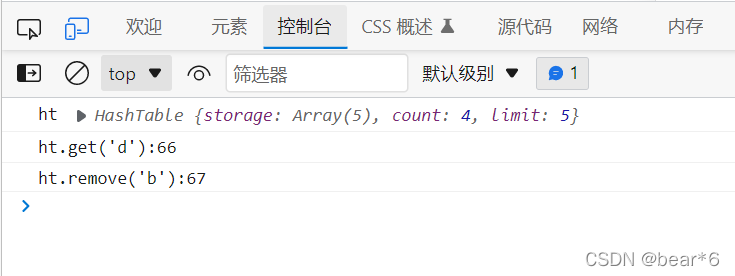
4、判斷哈希表是否為空
HashTable.prototype.isEmpty = function(){
return this.count === 0;
}
代碼測驗:
console.log("是否為空:"+ht.isEmpty());
結果:
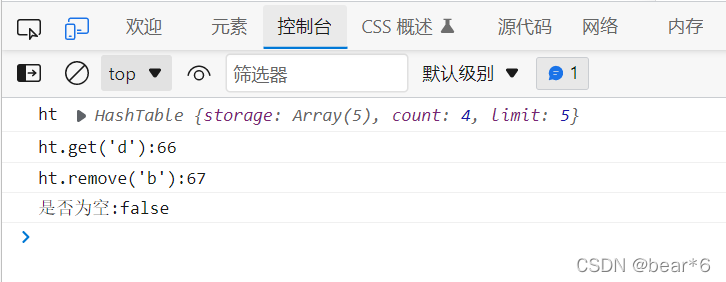
5、獲取哈希表的元素個數
HashTable.prototype.size = function(){
return this.count;
}
代碼測驗:
console.log("哈希表元素個數:"+ht.size());
結果:
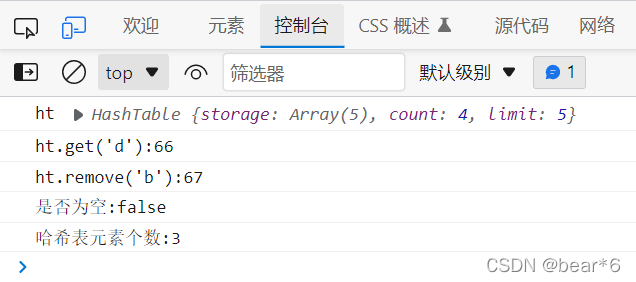
七、哈希表擴容
1、哈希表擴容思想
上述代碼的封裝中,我們是將所有的資料項放在長度為5的陣列中,因為我們使用的是鏈地址法,所以哈希表當前的資料量和總長度的比值可以大于1,這個哈希表可以無限制的插入新資料,但是,隨著資料量的增多,每一個index對應的bucket會越來越長,也會造成效率的降低,所以,在合適的情況下對陣列進行擴容是很有必要的,那應該如何進行擴容呢?擴容可以簡單的將容量增大兩倍,但是在這種情況下,所有的資料項一定要同時進行修改(重新呼叫哈希函式,獲取到不同的位置)什么情況下擴容呢?比較常見的是:當哈希表當前的資料量和總長度的比值可以大于0.75的時候就可以進行擴容,
2、哈希表擴容實作
實作思路:首先,保存舊的陣列內容,然后重置所有的屬性,遍歷保存的舊陣列的內容,判斷bucket是否為空,為空的話,進行跳過,否則,取出資料,重新插入,實作代碼為:
HashTable.prototype.resize = function(newLimit){
//保存舊陣列的內容
var oldStorge = this.storage;
//重置所有屬性
this.storage = [];
this.count = 0;
this.limit = newLimit;
//遍歷舊陣列的內容
for(var i =0;i<oldStorge.length;i++){
//取出對應的bucket
var bucket = oldStorge[i];
//判斷backet是否為空
if(bucket == null){
continue;
}
//取出資料重新插入
for(var j =0;j<bucket.length;j++){
var tuple = bucket[j];
this.put(tuple[0],tuple[1]);
}
}
}
封裝完成后,每添加一個資料項的時候,就進行是否擴容判斷,需要的話,在進行擴容,代碼為:
if(this.count > this.limit*0.75){
this.resize(this.limit*2);
}
那么,有對應的擴大容量,就有對應的縮小容量,當我們洗掉資料項的時候,如果剩余的資料項很小,我們就可以進行縮小容量,代碼如下:
if(this.limit > 5 && this.count < this.limit/2){
this.resize(Math.floor(this.limit/2))
}
八、完整代碼
function HashTable(){
// 定義屬性
this.storage = [];
this.count = 0;
this.limit = 5;
HashTable.prototype.hashFunc = function(str,size){
//定義hashCode變數
var hashCode = 0;
//根據霍納演算法,計算hashCode的值
//先將字串轉化為數字編碼
for(var i =0;i<str.length;i++){
hashCode = 37*hashCode + str.charCodeAt(i)
}
//取余操作
var index = hashCode % size;
return index;
}
//插入和修改操作
HashTable.prototype.put = function(key,value){
//根據key獲取對應的index
var index = this.hashFunc(key,this.limit);
//根據index取出對應的bucket
var bucket = this.storage[index];
//如果值為空,給bucket賦值一個陣列
if(bucket == null){
bucket = [];
this.storage[index] = bucket;
}
//判斷是否是修改資料
for(let i =0;i<bucket.length;i++){
var tuple = bucket[i];
if(tuple[0] === key){
tuple[1] = value;
return;
}
}
//進行添加操作
bucket.push([key,value]);
this.count += 1;
//進行擴容判斷
if(this.count > this.limit*0.75){
this.resize(this.limit*2);
}
}
//獲取操作
HashTable.prototype.get = function(key){
//根據key獲取對應的index
var index = this.hashFunc(key,this.limit);
//根據index獲取對應的bucket
var bucket = this.storage[index];
//判斷是否為空
if(bucket == null){
return null;
}
//線性查找
for(let i = 0;i<bucket.length;i++){
var tuple = bucket[i];
if(tuple[0] === key){
return tuple[1];
}
}
return null;
}
//洗掉操作
HashTable.prototype.remove = function(key){
//根據key獲取對應的index
var index = this.hashFunc(key,this.limit);
//根據index獲取對應的bucket
var bucket = this.storage[index];
//判斷是否為空
if(bucket == null){
return null;
}
//線性查找并通過splice()洗掉
for(let i =0;i<bucket.length;i++){
var tuple = bucket[i];
if(tuple[0] === key){
bucket.splice(i,1);
this.count -= 1;
return tuple[1];
//縮小容量
if(this.limit > 5 && this.count < this.limit/2){
this.resize(Math.floor(this.limit/2))
}
}
}
return null;
}
//擴容
HashTable.prototype.resize = function(newLimit){
//保存舊陣列的內容
var oldStorge = this.storage;
//重置所有屬性
this.storage = [];
this.count = 0;
this.limit = newLimit;
//遍歷舊陣列的內容
for(var i =0;i<oldStorge.length;i++){
//取出對應的bucket
var bucket = oldStorge[i];
//判斷backet是否為空
if(bucket == null){
continue;
}
//取出資料重新插入
for(var j =0;j<bucket.length;j++){
var tuple = bucket[j];
this.put(tuple[0],tuple[1]);
}
}
}
HashTable.prototype.isEmpty = function(){
return this.count === 0;
}
HashTable.prototype.size = function(){
return this.count;
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/386619.html
標籤:其他