我是 SQL 查詢的新手,我有一些資料,我正在嘗試找到如下所示的結果。
在我的示例資料中,由于多個位置,我的客戶 ID 重復多次,我想要做的是創建一個查詢,以影像輸出格式顯示輸出,
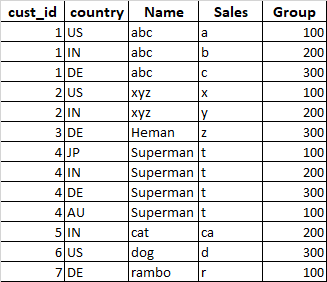
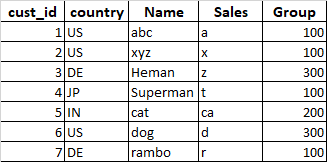
- 如果客戶只存在一次我采取該行
- 如果客戶存在不止一次,我檢查國家;如果
Country = 'US',我拿走那一行并丟棄其他人 - 如果客戶存在不止一次并且國家不是美國,那么我選擇第一行
請注意:我有 35 列,我不想更改 ROWS 順序,因為我必須選擇第一行,以防客戶存在多次且國家/地區不是“美國”。
我嘗試過的:我正在嘗試使用 rank 函式執行此操作,但未成功。不確定我的方法是否正確,請任何人分享該問題的 T-SQL 查詢。
問候, 拉胡爾
樣本資料:
需要的輸出:
uj5u.com熱心網友回復:
我創建了一個(短)dbfiddle
簡短說明(只需在 SO 上重復此處的代碼):
步驟1:
-- select everyting, and 'US' as first row
SELECT
cust_id,
country,
sales,
CASE WHEN country='US' THEN 0 ELSE 1 END X,
ROW_NUMBER() OVER (PARTITION BY cust_id
ORDER BY (CASE WHEN country='US' THEN 0 ELSE 1 END)) R
FROM table1
ORDER BY cust_id, CASE WHEN country='US' THEN 0 ELSE 1 END;
第2步:
-- filter only rows which are first row...
SELECT *
FROM (
SELECT
cust_id,
country,
sales,
CASE WHEN country='US' THEN 0 ELSE 1 END X,
ROW_NUMBER() OVER (PARTITION BY cust_id
ORDER BY (CASE WHEN country='US' THEN 0 ELSE 1 END)) R
FROM table1
-- ORDER BY cust_id, CASE WHEN country='US' THEN 0 ELSE 1 END
) x
WHERE x.R=1
uj5u.com熱心網友回復:
我不能保證性能,但它應該適用于 SQL Server 2005。假設您的表名為 CustomerData 試試這個:
select cust_id, country, Name, Sales, [Group]
from CustomerData
where country = 'US'
union
select c.* from CustomerData c
join (
select cust_id, min(country) country
from CustomerData
where cust_id not in (
select cust_id
from CustomerData
where country = 'US'
)
group by cust_id
) a on a.cust_id = c.cust_id and a.country = c.country
它的作業原理是找到所有記錄以美國為國家的人,然后將其與所有記錄中沒有美國為國家的第一個國家聯合起來。如果 min() 沒有得到你想要的國家,那么你需要找到一個替代的聚合函式來選擇你想要的國家。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/389924.html