我正在一個使用 keras(來自 tensorflow)的神經網路進行大學專案。我對這個庫很陌生,所以我真的不知道我應該如何將資料輸入模型以使訓練正常作業。我已經在互聯網上搜索了幾個小時,但找不到有關如何執行此操作的正確教程/檔案。
這是我正在使用的模型,可能是最簡單的模型之一:
model = keras.Sequential([
keras.layers.Dense(20, input_dim=1,activation = activations.relu),
keras.layers.Dense(10, activation= activations.relu),
keras.layers.Dense(8, activation= activations.sigmoid)
])
model.compile(optimizer = "adam", loss = "sparse_categorical_crossentropy",
metrics = ["accuracy"])
網路的輸入是一個包含 20 個浮點數的串列,輸出一個包含 8 個浮點數的串列,范圍從 0 到 1(置信度),所以我認為這個模型是可以的,如果我錯了,請告訴我。
這是我正在嘗試構建和訓練的模型的圖表:
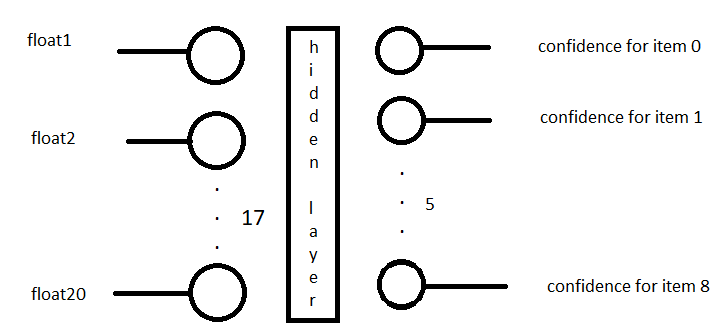
假設我有:
- 預期輸出 [1,0,0,0,0,0,0,0] 的 10 個輸入示例(10 個 20 個浮點數的串列)
- 預期輸出 [0,1,0,0,0,0,0,0,0,0] 的 10 個輸入示例
- ...
- 預期輸出的 10 個輸入示例 [0,0,0,0,0,0,0,1]
我應該如何準備這些資料以便將其用于
model.fit(training_inputs,expected_outputs,epochs = NUM_EPOCHS) ?
training_inputs 到底應該是什么?和預期的輸出?
任何幫助將不勝感激。感謝您的時間!
uj5u.com熱心網友回復:
首先,您的模型中有兩個問題。根據你的描述,你的輸入資料是20維的,所以在第一層你應該有input_dim=20. 然后,你有一個交叉熵損失,所以我假設你正在訓練一個 8 類分類器。如果是這種情況,那么keras.layers.Dense(8, activation= activations.sigmoid)你應該使用
keras.layers.Dense(8, activation=None),
keras.layers.Softmax()
因為這可確保您獲得每個輸入資料點的類分布。
現在關于您的輸入資料問題,在您的情況下training_inputs,張量(或 numpy 陣列,可以很容易地轉換)是否應該具有形狀(n_points, 20)。因此,expected_outputs應該有形狀(n_points, 8)。因此,只需沿著第一個維度 ( axis=0)連接/堆疊您的輸入資料,這樣每一行都對應于您的 20 維資料點。你對 做同樣的expected_outputs事情,也許是這樣的,
expected_outputs = np.r_[
np.tile([[1,0,0,0,0,0,0,0]], (10, 1)),
np.tile([[0,1,0,0,0,0,0,0]], (10, 1)),
...
np.tile([[0,0,0,0,0,0,0,1]], (10, 1)),
]
記得設定batch_size和shuffle!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/398281.html