我需要從文本檔案中讀取行并從每行中提取參考的人名和參考的文本。
行看起來類似于這樣:
“我曾經!”,荷馬辛普森回應道。
評論:
提示:使用從 '
open' 方法回傳的物件來獲取檔案處理程式。您閱讀的每一行都應在行尾包含一個換行符。洗掉換行符如下:line_cln =line.strip()
每一行都有選項(假設這三個選項之一): 第一組模式,其中人名出現在參考文本之前。第二組模式,參考的文本出現在人之前。空行。
完成
transfer_raw_text_to_dataframe函式以回傳具有提取的人名和文本的資料框,如上所述。該資訊預計將從給定'filename'檔案的行中提取。
回傳的資料框應包括兩列:
person_name- 包含每行提取的人名。extracted_text- 包含每行提取的參考文本。回傳值:
- 資料框 - 如上所述提取資訊的資料框。
- 重要提示:如果一行不包含任何參考模式,則不應在資料框中的相應行中保存任何資訊。
到目前為止我得到了什么:[編輯]
def transfer_raw_text_to_dataframe(filename):
data = open(filename)
quote_pattern ='"(.*)"'
name_pattern = "\w \s\w "
df = open(filename, encoding='utf8')
lines = df.readlines()
df.close()
dataframe = pd.DataFrame(columns=('person_name', 'extracted_text'))
i = 0
for line in lines:
quote = re.search(quote_pattern,line)
extracted_quotation = quote.group(1)
name = re.search(name_pattern,line)
extracted_person_name = name.group(0)
df2 = {'person_name': extracted_person_name, 'extracted_text': extracted_quotation}
dataframe = dataframe.append(df2, ignore_index = True)
dataframe.loc[i] = [person_name, extracted_text]
i =i 1
return dataframe
資料框是用正確的形狀創建的,問題是,每行中的人名是:'Oh man',參考是'Oh man,that guy's hard to love。(在所有這些中)這很奇怪,因為它甚至不在 txt 檔案中......
誰能幫我解決這個問題?
編輯:我需要從一個僅包含以下行的簡單 txt 檔案中提取:
"Am I ever!", Homer Simpson responded.
"Hmmm. So... is it okay if I go to the women's conference with Chloe?", Lisa Simpson answered.
"Really? Uh, sure.", Bart Simpson answered.
"Sounds great.", Bart Simpson replied.
Homer Simpson responded: "Danica Patrick in my thoughts!"
C. Montgomery Burns: "Trust me, he'll say it, or I'll bust him down to Thursday night vespers."
"Gimme that torch." Lisa Simpson said.
"No! No, I've got a lot more mothering left in me!", Marge Simpson said.
"Oh, Homie, I don't care if you're a billionaire. I love you just because you're..." Marge Simpson said.
"Damn you, e-Bay!" Homer Simpson answered.
uj5u.com熱心網友回復:
可能是這樣的:
import pandas as pd
import re
# do smth
with open("C:\\12.txt","r") as f:
data= f.read()
# print(data)
########### findall text in quotes
m = re.findall(r'\"(. )\"', data)
print("RESULT: \n", m)
df= pd.DataFrame({'rep':m})
print(df)
########### retrieve and replace text in quotes for nothing
m= re.sub(r'\"(. )\"', r'', data)
########### get First Name & Last Name from the rest text in each line
regex = re.compile("([A-Z]{1}[a-z] [A-Z]{1}[a-z] )")
mm= regex.findall(m)
df1= pd.DataFrame({'author':mm})
print(df1)
########### join 2 dataframes
fin=pd.concat([df, df1], axis=1)
print(fin)
所有列印只是為了檢查(讓它們離開以獲得更清晰的代碼)。只是“C. Montgomery Burns”正在丟失他的第一封信......
uj5u.com熱心網友回復:
檔案夾中的for回圈:
# All files acc. mask ending with .txt
print(glob.glob("C:\\MyFolder\\*.txt"))
mylist=[ff for ff in glob.glob("C:\\MyFolder\\*.txt")]
print("file_list:\n", mylist)
for filepath in mylist:
# do smth with each filepath
收集您從檔案中獲取的所有 dfs - 像這樣(例如通過掩碼讀取 csv-files):
import glob
import pandas as pd
def dfs_collect():
mylist=[ff for ff in glob.glob("C:\\MyFolder\\*.txt")] # all files by-mask
print("file_list:\n", mylist)
dfa=pd.concat((pd.read_csv(file, sep=';', encoding='windows-1250', index_col=False) for file in mylist), ignore_index=True)
但是要獲取檔案的內容-需要內容示例...如果沒有 txt 檔案示例(具有 dummy_info 但保留其真實結構),我懷疑任何人都會嘗試想象它應該是什么樣子
uj5u.com熱心網友回復:
我認為以下可以滿足您的需求。請驗證輸出是否準確。我會解釋任何不清楚的行
import pandas as pd
import numpy as np
import nltk
from nltk.tree import ParentedTree
import typing as t # This is optional
# Using `read_csv` to read in the text because I find it easier
data = pd.read_csv("dialog.txt", header = None, sep = "~", quoting=3)
dialouges = data.squeeze() # Getting a series from the above DF with one column
def tag_sentence(tokenized: t.List[str]) -> t.List[t.Tuple[str, str]]:
tagged = nltk.pos_tag(tokenized)
tagged = [(token, tag) if tag not in {"``", "''"} else (token, "Q") for token, tag in tagged]
keep = {"Q", "NNP"}
renamed = [(token, "TEXT") if tag not in keep else (token, tag) for token, tag in tagged]
return renamed
def get_parse_tree(tagged_sent):
grammar = """
NAME: {<NNP> }
WORDS: {<TEXT> }
DIALOUGE: {<Q><WORDS|NAME> <Q>}
"""
cp = nltk.RegexpParser(grammar)
parse_tree = cp.parse(tagged_sent)
return parse_tree
def extract_info(parse_tree):
ptree = ParentedTree.convert(parse_tree)
trees = list(ptree.subtrees())
root = ptree.root()
for subtree in trees[1:]:
if subtree.parent() == root:
if subtree.label() == "DIALOUGE":
dialouge = ' '.join(word for word, _ in subtree.leaves()[1:-1]) # Skipping quotaton marks
if subtree.label() == "NAME":
person = ' '.join(word for word, _ in subtree.leaves())
return dialouge, person
def process_sentence(sentence):
return extract_info(get_parse_tree(tag_sentence(nltk.word_tokenize(sentence))))
processed = [process_sentence(line) for line in dialouges]
result = pd.DataFrame(processed, columns=["extracted_text", "person_name"])
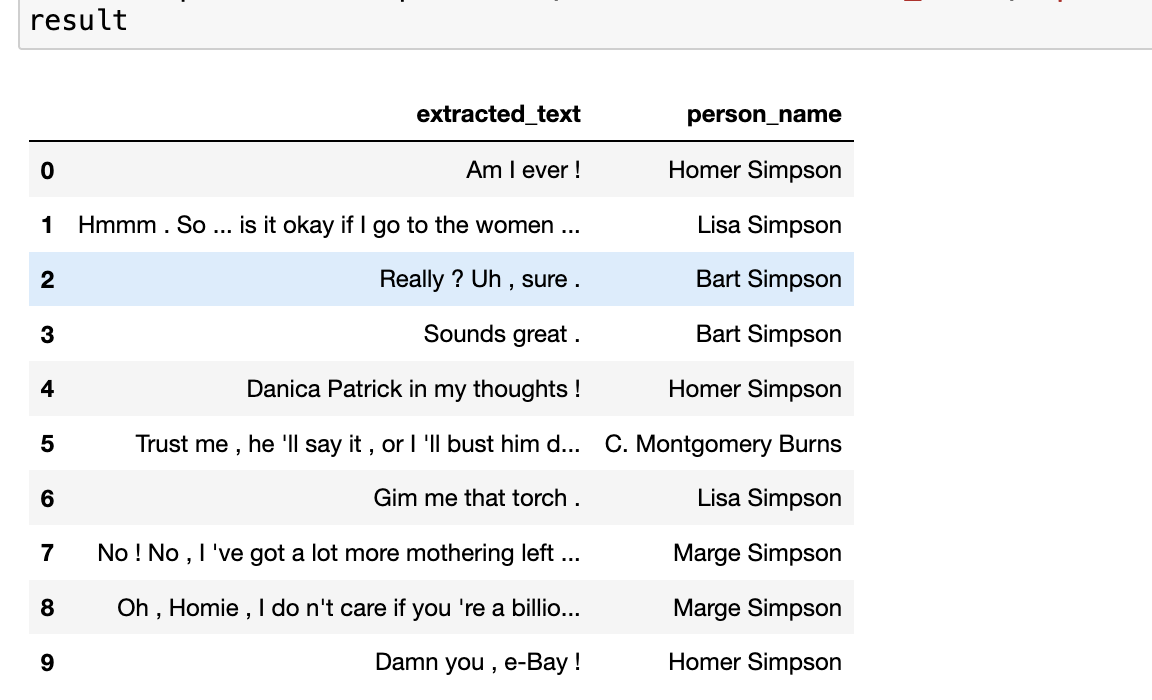
生成的 DataFrame 如下所示:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/406345.html
標籤: