我是使用 LSTM 的新手,我什至很難直觀地理解它們。
我將它們用于回歸問題,我有大約 6000 個資料集,每個時間步有約 450 個時間步,每個時間步有 11 個特征。目標值是 2d ~ [a,b] 并且對于單個資料集它們是相同的。訓練后,我想提供時間步長并預測 2d y 值。
示例: 資料集(6000 個中有 1 個)具有約 450 個不同的時間步長,型別為 x = [1,2,3,4,5,6,7,8,9,10,11],目標值 y = [1, 2]
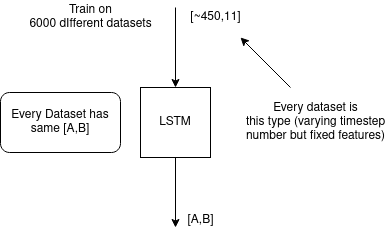
我目前遇到的問題是了解 LSTM 在輸入之間的相關性方面究竟學到了什么,如果我正在處理多個資料集,我應該準確提供哪些資料以及按什么順序提供?我對術語 batch_size 感到困惑,如果我有不同的序列,術語 seq_length 會發生什么......我是否將整個 450 個時間步作為序列傳遞?
我現在所做的是將所有資料合并到一個 csv 檔案中并將它們傳遞給模型。由于記憶體問題,我無法運行它,所以我將它減少到 5000 個時間步長,
下面是我使用的 LSTM 類
''' 類 LSTM(nn.Module):
def __init__(self, num_classes, input_size, hidden_size, num_layers):
super(LSTM, self).__init__()
self.num_classes = num_classes
self.num_layers = num_layers
self.input_size = input_size
self.hidden_size = hidden_size
self.seq_length = seq_length
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h_0 = Variable(torch.zeros(
self.num_layers, x.size(0), self.hidden_size))
c_0 = Variable(torch.zeros(
self.num_layers, x.size(0), self.hidden_size))
# Propagate input through LSTM
ula, (h_out, _) = self.lstm(x, (h_0, c_0))
h_out = h_out.view(-1, self.hidden_size)
out = self.fc(h_out)
return out, h_out
'''
我真的不需要技術答案..我真的很想有人能澄清在這種情況下發生了什么以及我應該如何處理它......我已經在網上搜索了幾十個帖子,但似乎我只是不得到它,否則這不完全是我的情況。
uj5u.com熱心網友回復:
我將嘗試以一種同時解釋詞匯的方式來解釋這一點。
LSTM 通常用于順序資料,例如時間序列,其中您有x_t多個時間步長的資料點t=t0...tN。在這里,N將是序列長度(=seq_length?)。現在這意味著對于 D 維資料,一個“資料集”或更準確地說,一個序列的形狀為N x D。
現在讓我們假設N所有序列都是相等的。這意味著,如果您有B序列,您可以將它們堆疊成B x N x D張量 - 這將對應于實際資料集,這基本上是您使用的所有資料。在這里,B是您的批處理軸,基本上只是指您堆疊獨立序列的軸。如果您選擇同時訓練所有資料,您只需將完整的B x N x D資料集傳遞給模型。然后,您的批量大小將是B. (以下注)
現在,如果序列長度不相等,您可以做很多事情。首先,您應該問自己是否要在完整序列上進行訓練。是否有必要閱讀完整的N步驟來估計結果,還是只看n < N步驟就足夠了?如果是這樣的話,你可以品嘗b(你的新批量大小,你可以定義你怎么樣)長度的序列n,其中n < N的所有序列。
如果序列的某些部分不足以估計結果,它會變得更加復雜。然后我建議單獨提供完整的序列,只訓練單個序列。這基本上意味著 batchsize b=1,因為您不能堆疊序列,因為它們的長度成對不同。在這里,您將為模型提供b x n x D張量。
我不確定這是否是“標準程式”,但這就是我要解決的問題。
注意:對完整資料集進行訓練通常不是一個好習慣。通常,您希望b < B從資料集中隨機抽取批次,從而使您的訓練隨機化。
uj5u.com熱心網友回復:
LSTM 通過識別順序模式(如果以軸為軸,也可以將其視為基于時間的模式)來處理順序資料,以提供順序輸出(每個序列位置的一組輸出,而不是您的情況)或輸出每個序列(你的情況)。此資訊通過記憶體主干(也稱為恒定錯誤輪播)通過網路傳遞,該主干可以通過整個序列,甚至雙向(盡管這在前向和后向傳播之間是分開的)。
PyTorch 解釋了它希望如何處理您的資料:
輸入:當batch_first=False 時形狀張量為(L,N,Hin) 或當batch_first=True 時(N,L,Hin) 為(N,L,H in) 包含輸入序列的特征。輸入也可以是打包的可變長度序列。有關詳細資訊,請參閱 torch.nn.utils.rnn.pack_padded_sequence() 或 torch.nn.utils.rnn.pack_sequence()。
因此,當輸入到 RNN 模型中時,您的資料應該是 3D 張量,盡管請注意 PyTorch 的 rnn.pack_sequence(或 pack_padded_sequence)功能提供了可變長度序列。這些將考慮可變長度,因此您的資料不會受到零填充的影響,當您將批次打亂或推斷單個序列時,這將不是一件好事。
最后,批處理資料是一種一次處理多個資料點(在本例中為序列)的方法,以便通過一次平均多個樣本并聯合反向傳播損失來加速訓練,同時花費相同的時間來完成此操作(大致)作為單個資料點。序列在這方面很棘手,因為它們的長度不一樣是很常見的,但通常這是通過將序列補零到批處理中的最大長度來處理的。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/407300.html
標籤: