我寫了兩個函式來比較 std::vector 和動態分配陣列的時間成本
#include <iostream>
#include <vector>
#include <chrono>
void A() {
auto t1 = std::chrono::high_resolution_clock::now();
std::vector<float> data(5000000);
auto t2 = std::chrono::high_resolution_clock::now();
float *p = data.data();
for (int i = 0; i < 5000000; i) {
p[i] = 0.0f;
}
auto t3 = std::chrono::high_resolution_clock::now();
std::cout << std::chrono::duration_cast<std::chrono::microseconds>(t2 - t1).count() << " us\n";
std::cout << std::chrono::duration_cast<std::chrono::microseconds>(t3 - t2).count() << " us\n";
}
void B() {
auto t1 = std::chrono::high_resolution_clock::now();
auto* data = new float [5000000];
auto t2 = std::chrono::high_resolution_clock::now();
float *ptr = data;
for (int i = 0; i < 5000000; i) {
ptr[i] = 0.0f;
}
auto t3 = std::chrono::high_resolution_clock::now();
std::cout << std::chrono::duration_cast<std::chrono::microseconds>(t2 - t1).count() << " us\n";
std::cout << std::chrono::duration_cast<std::chrono::microseconds>(t3 - t2).count() << " us\n";
}
int main(int argc, char** argv) {
A();
B();
return 0;
}
A() 花費大約 6000 us 來初始化向量,然后花費 1400 us 來填充零。
B() 分配記憶體的成本不到 10 us,然后填充零的成本為 5800 us。
為什么他們的時間成本有如此大的差異?
編譯器:g =9.3.0
標志:-O3 -DNDEBUG
uj5u.com熱心網友回復:
首先,請注意std::vector<float>建構式已經將向量歸零。
對于您觀察到的行為,有許多合理的系統級解釋:
一個非常合理的方法是快取:當您使用 new 分配陣列時,回傳的指標所參考的記憶體不在快取中。當您創建一個向量時,建構式會將分配的記憶體區域歸零,從而將記憶體帶到快取中。因此,隨后的歸零將在快取中命中。
其他原因可能包括編譯器優化。編譯器可能會意識到您的歸零對于 std::vector 是不必要的。鑒于您獲得的數字,我會在這里打折。
uj5u.com熱心網友回復:
QuickBench 是一個很好的工具,可以比較做同一件事的不同方式。
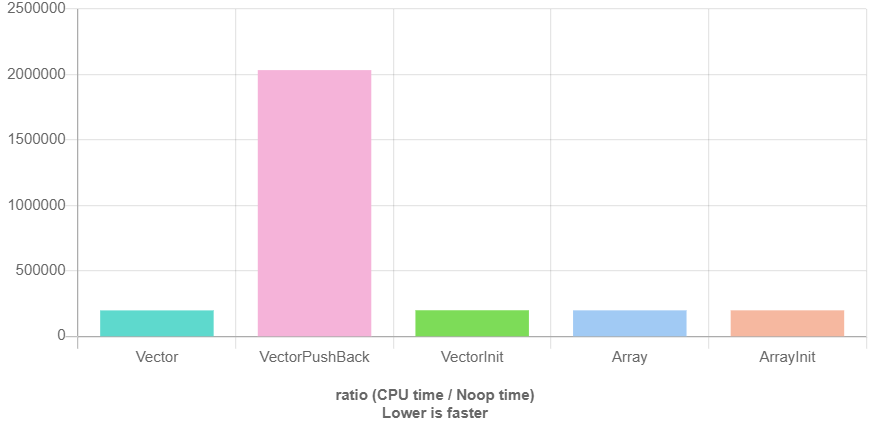
除一個之外的所有變體push_back在運行時幾乎相同。但是載體要安全得多。很容易忘記釋放記憶體(正如您自己演示的那樣)。
uj5u.com熱心網友回復:
第一件事。您立即展示了為什么我們使用RAII型別,例如std::vector:您呼叫new,但從不呼叫delete。即你有記憶體泄漏。也許你會說“但這只是一個演示”。嗯,記憶體泄漏是 C 和 C 中的一個實際大問題,并導致生產代碼中的許多問題。
其次,你的例子沒有多大意義。
std::vector<float> data(N);
將所有值初始化為0.0f
相似的
auto data = new float[N]();
可以默認將所有值初始化為0.0f.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/433857.html
標籤:C