我正在將一系列李克特量表問題繪制為堆積條形圖。它們需要被標記,但有些片段是兩個小片段,并且像下面的示例一樣重疊(下面有示例代碼)。有沒有一種聰明的方法可以只標記足夠大以適合標簽的部分,或者有一種方法可以錯開標簽的呈現方式?
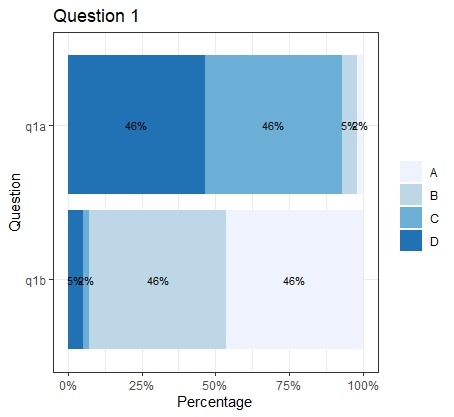
q1a<-rep(c("A", "B", "C", "D"), c(2, 5,45,45))
q1b<-rep(c("A", "B", "C", "D"), c(45,45,2, 5))
data<-data.frame(q1a,q1b)
data %>%
select(q1a:q1b) %>%
pivot_longer(cols = everything(), names_to = "Question") %>%
filter(!is.na(value)) %>%
count(Question, value) %>%
group_by(Question) %>%
mutate(Pct = n / sum(n)) %>%
ggplot(aes(fill = value, x = Pct, y = fct_rev(Question)))
geom_bar(position = "fill", stat = "identity")
geom_text(aes(label = paste0(sprintf("%1.0f", Pct * 100), "%")), position = position_stack(vjust = 0.5), size = 3)
scale_fill_brewer(palette = "Blues")
theme_bw()
scale_x_continuous(labels = scales::percent)
labs(title = "Question 1", y = "Question", x = "Percentage")
theme(legend.title = element_blank())
uj5u.com熱心網友回復:
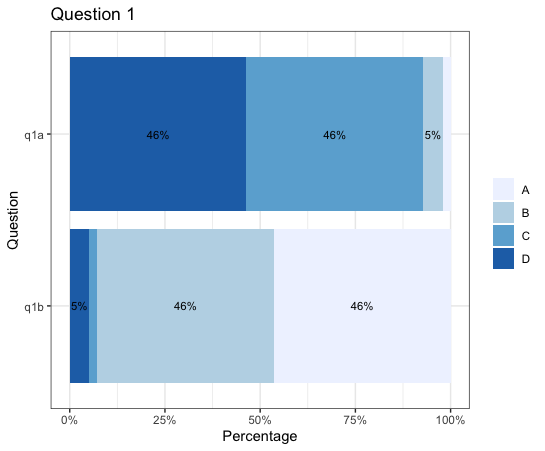
如果我是你,我只會使用in顯示Pct超過 5%的標簽。如果小于 5%,則不顯示任何內容。if_else()geom_text(aes())
另外,由于您的geom_bar位置是fill,您還應該使用position = position_fill()ingeom_text來對齊位置。
library(tidyverse)
data %>%
select(q1a:q1b) %>%
pivot_longer(cols = everything(), names_to = "Question") %>%
filter(!is.na(value)) %>%
dplyr::count(Question, value) %>%
group_by(Question) %>%
mutate(Pct = n / sum(n)) %>%
ggplot(aes(fill = value, x = Pct, y = fct_rev(Question)))
geom_bar(position = "fill", stat = "identity")
geom_text(aes(label = if_else(Pct > 0.05, paste0(sprintf("%1.0f", Pct * 100), "%"), NULL)),
position = position_fill(vjust = 0.5), size = 3)
scale_fill_brewer(palette = "Blues")
theme_bw()
scale_x_continuous(labels = scales::percent)
labs(title = "Question 1", y = "Question", x = "Percentage")
theme(legend.title = element_blank())
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/436092.html