我正在嘗試創建兩個資料的散點圖,但我不知道如何將排序結果指定到圖中。
程式是這樣的:
- 閱讀“data_to_be_chosen.csv”
- 閱讀“data_to_be_plotted.csv”
- 對“data_to_be_chosen.csv”進行排序以找到兩個最上面的值(及其名稱)
- 在“data_to_be_plotted.csv”中找到相應的名稱/列
- 顯示兩者的散點圖
我在第 5 步遇到了問題。
假設 ColumnC和 ColumnA具有兩個最高值。如果我手動將資料設定為繪圖,它將是:
plot(plotted$C, plotted$A)
但是,我希望根據排序順序自動完成。
我認為下面的代碼會起作用:
plot(plotted[names(sort(chosen_list$chosen[1,], decreasing=TRUE)[1])],
plotted[names(sort(chosen_list$chosen[1,], decreasing=TRUE)[2])])
但是,這給了我一個錯誤:
Error in stripchart.default(x1, ...) : invalid plotting method
我也嘗試了這些,但它們也不起作用:
plot(names(sort(chosen_list$chosen[1,], decreasing=TRUE)[1]),
names(sort(chosen_list$chosen[1,], decreasing=TRUE)[2]))
plot(colnames(sort(chosen_list$chosen[1,], decreasing=TRUE)[1]),
colnames(sort(chosen_list$chosen[1,], decreasing=TRUE)[2]))
有沒有辦法將排序結果設定為此圖?
我沒有更多的想法了。
我的 R 版本是 4.1.2(最新版本)。
這是我的資料:
data_to_be_chosen.csv
A,B,C
2.044281,0.757232,2.188617
data_to_be_plotted.csv
A,B,C
0.34503,-0.38781,-0.3506
0.351566,-0.3901,-0.35244
0.351817,-0.39144,-0.35435
0.351222,-0.39138,-0.35394
0.351222,-0.39113,-0.35366
0.350753,-0.39088,-0.35291
0.350628,-0.39041,-0.3531
0.349127,-0.3881,-0.3511
0.346125,-0.38675,-0.34969
0.346594,-0.38719,-0.34963
這是我的代碼:
plotted <- read.csv("data_to_be_plotted.csv")
chosen <- read.csv("data_to_be_chosen.csv")
chosen_list <- list(chosen=chosen)
sort(chosen_list$chosen[1,], decreasing=TRUE)[1:2]
names(sort(chosen_list$chosen[1,], decreasing=TRUE)[1:2])
plotted[names(sort(chosen_list$chosen[1,], decreasing=TRUE)[1:2])]
# Correlation can be calculated with the above data frame
cor(plotted[names(sort(chosen_list$chosen[1,], decreasing=TRUE)[1])],
plotted[names(sort(chosen_list$chosen[1,], decreasing=TRUE)[2])])
# What I want is this plot ... except manually specifying C or A
plot(plotted$C, plotted$A)
# The above data frame can NOT be used to plot / Issues "invalid plotting method"
plot(plotted[names(sort(chosen_list$chosen[1,], decreasing=TRUE)[1])],
plotted[names(sort(chosen_list$chosen[1,], decreasing=TRUE)[2])])
# I also tried, but no luck:
plot(names(sort(chosen_list$chosen[1,], decreasing=TRUE)[1]),
names(sort(chosen_list$chosen[1,], decreasing=TRUE)[2]))
plot(colnames(sort(chosen_list$chosen[1,], decreasing=TRUE)[1]),
colnames(sort(chosen_list$chosen[1,], decreasing=TRUE)[2]))
uj5u.com熱心網友回復:
問題在于,對一行進行子集化給出了一個"data.frame"物件而不是一個"numeric"向量,這可能是您所期望的。你可以用class().
class(chosen_list$chosen[1,])
# [1] "data.frame"
解決方案就是unlist它。
class(unlist(chosen_list$chosen[1,]))
# [1] "numeric"
在下面使用創建物件而不是重復代碼。
(x <- sort(unlist(chosen_list$chosen[1,]), decreasing=TRUE)[1:2])
# C A
# 2.188617 2.044281
(nx <- names(x))
# [1] "C" "A"
(p_df <- plotted[nx])
# C A
# 1 -0.35060 0.345030
# 2 -0.35244 0.351566
# 3 -0.35435 0.351817
# 4 -0.35394 0.351222
# 5 -0.35366 0.351222
# 6 -0.35291 0.350753
# 7 -0.35310 0.350628
# 8 -0.35110 0.349127
# 9 -0.34969 0.346125
# 10 -0.34963 0.346594
要將cor資料幀的兩個向量的關系作為單個值,我們可能需要[, j],因為資料幀有兩個維度。
cor(p_df[, 1], p_df[, 2])
# [1] -0.9029339
檢查(類似于上面):
class(cor(p_df[1], p_df[2]))
# [1] "matrix" "array"
class(cor(p_df[, 1], p_df[, 2]))
# [1] "numeric"
我建議您更新有關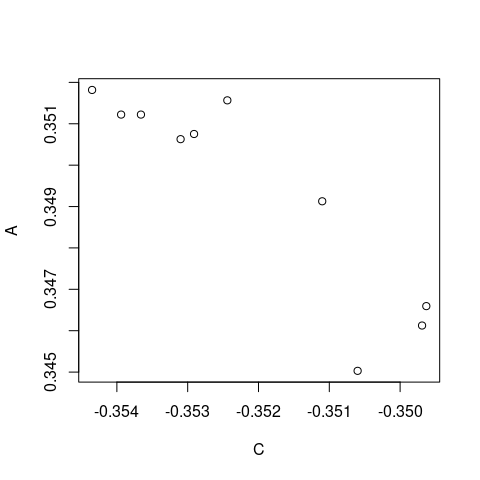
資料:
plotted <- structure(list(A = c(0.34503, 0.351566, 0.351817, 0.351222, 0.351222,
0.350753, 0.350628, 0.349127, 0.346125, 0.346594), B = c(-0.38781,
-0.3901, -0.39144, -0.39138, -0.39113, -0.39088, -0.39041, -0.3881,
-0.38675, -0.38719), C = c(-0.3506, -0.35244, -0.35435, -0.35394,
-0.35366, -0.35291, -0.3531, -0.3511, -0.34969, -0.34963)), class = "data.frame", row.names = c(NA,
-10L))
chosen <- structure(list(A = 2.044281, B = 0.757232, C = 2.188617), class = "data.frame", row.names = c(NA,
-1L))
chosen_list <- list(chosen=chosen)
uj5u.com熱心網友回復:
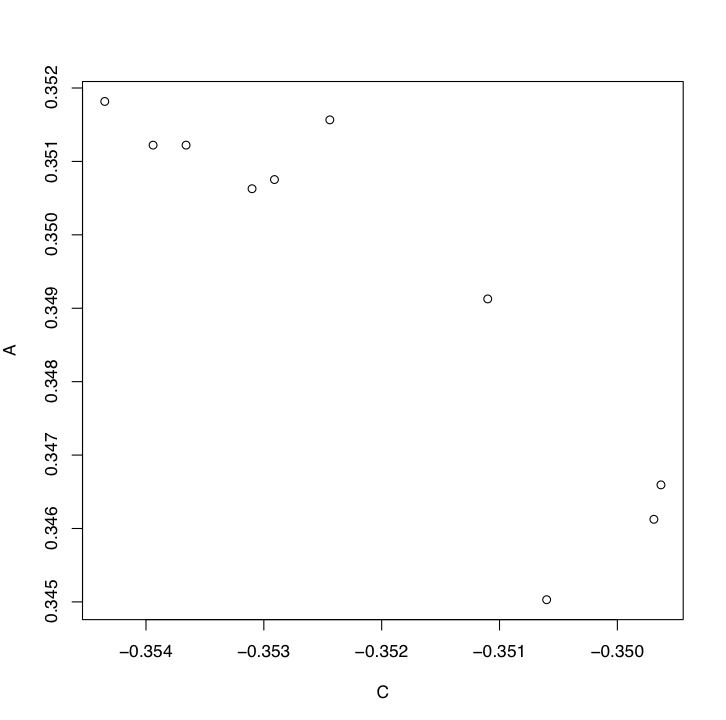
您可以使用 ; 將單行“data_to_be_chosen”df 強制轉換為命名向量unlist;然后排序,獲取前兩個名稱,并使用它們來索引“data_to_be_plotted”:
chosen_vec <- unlist(chosen)
plot(plotted[names(sort(chosen_vec, decreasing = TRUE)[1:2])])
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/437155.html
上一篇:如何對多級串列進行排序