您好,我需要有關此特定站點的幫助:(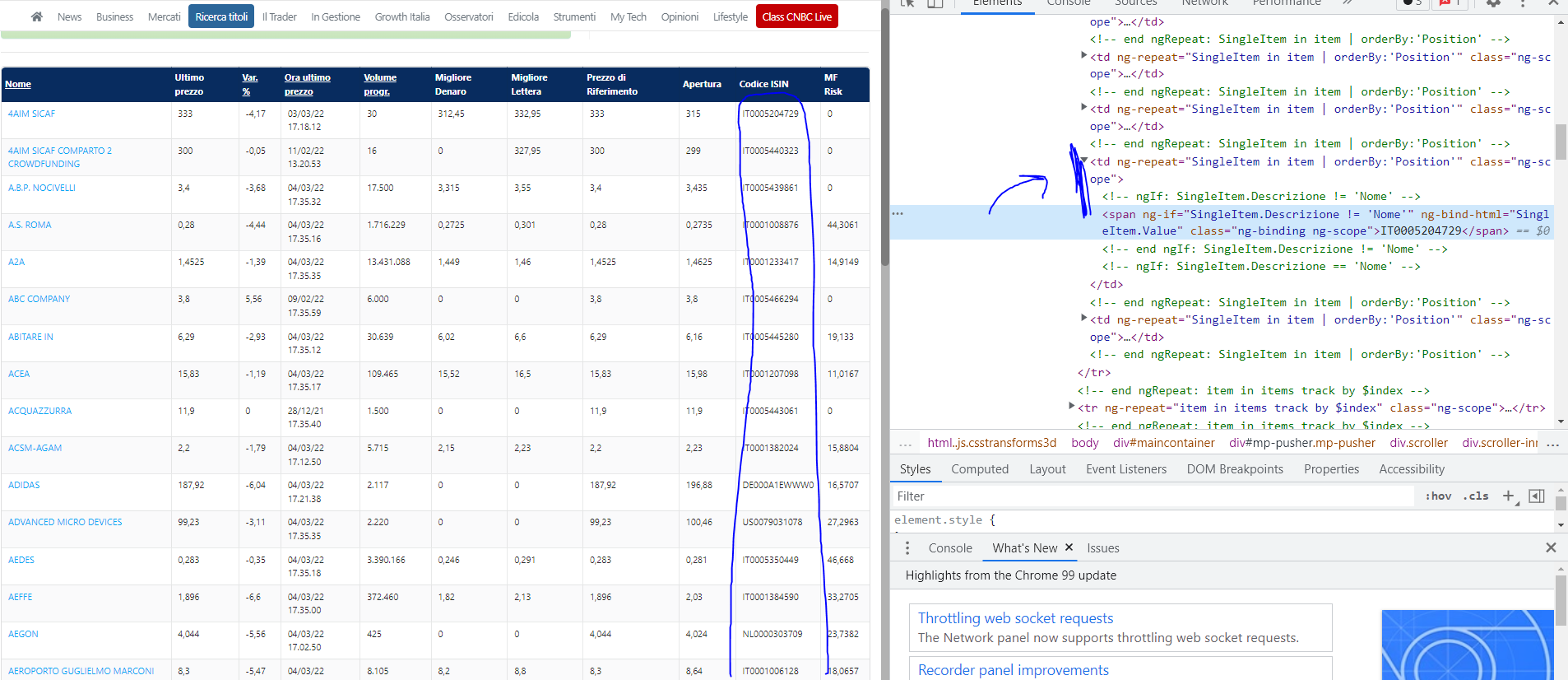
伊辛:
uj5u.com熱心網友回復:
抱歉,我看不到您現有的代碼是如何作業的。
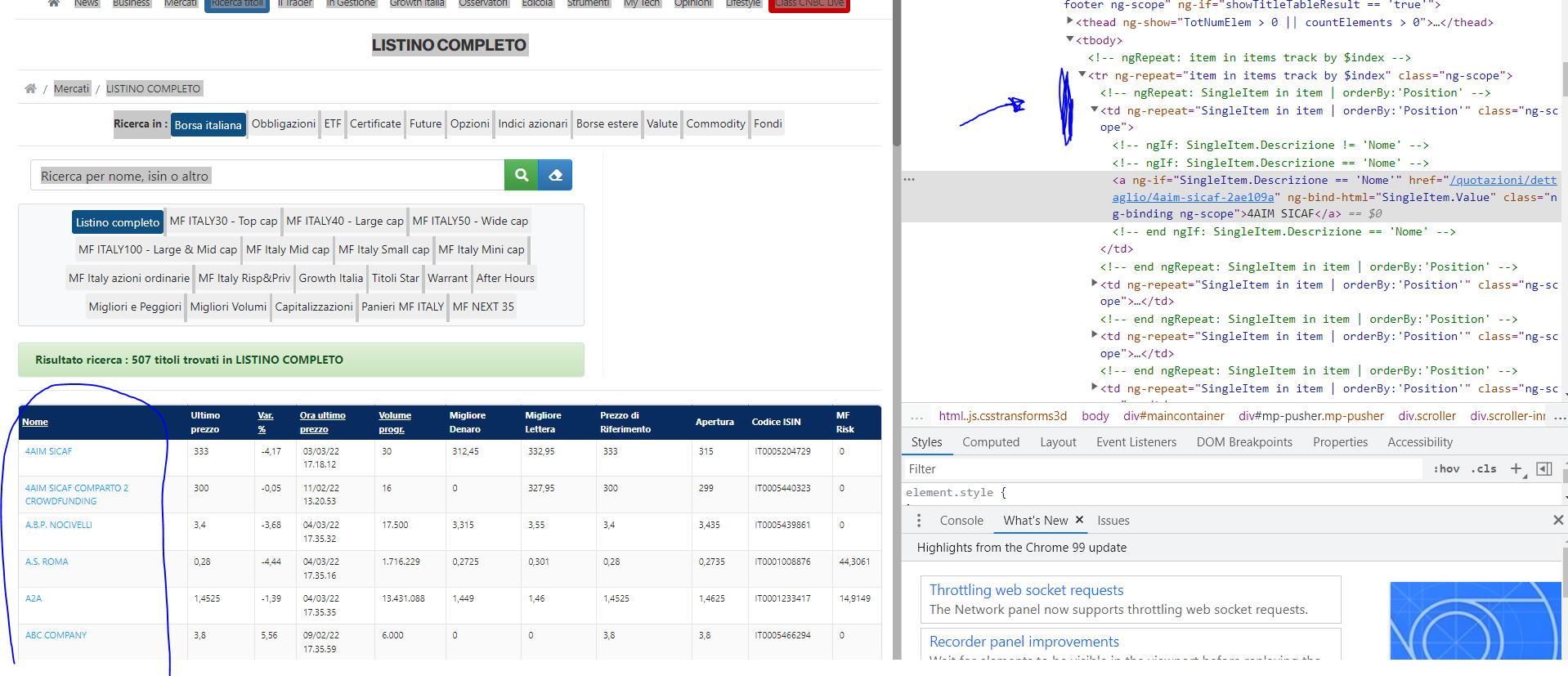
在我這邊,我看到你用來isin匹配什么的定位器。
我在這里更新了定位器。
我建議您永遠不要使用自動創建的定位器。
您在此處提供的代碼也缺少縮進。我希望你的實際代碼有適當的縮進。
請看看這是否會更好:
wd = wd.Chrome()
wd.get('https://www.milanofinanza.it/quotazioni/ricerca/listino-completo-2ae')
company_name = []
isin = []
for n in range(0,15):
time.sleep(10)
tickers = wd.find_elements(By.XPATH,"//table[contains(@class,'celled')]//tbody//tr//td[1]")
isins = wd.find_elements(By.XPATH,"//table[contains(@class,'celled')]//tbody//tr//td[10]")
for el in tickers:
company_name.append(el.text)
for is_el in isins:
isin.append(is_el.text)
l=wd.find_element(By.XPATH,'//nav//button[@ng-click="getDataTableNextClick()"]')
wd.execute_script("arguments[0].click();",l)
uj5u.com熱心網友回復:
我的第一反應是告訴你 selenium 對于你正在做的事情可能有點臃腫。有時您需要一個成熟的瀏覽器,但這不是其中之一。我推薦請求和漂亮的湯(它更適合發出大量請求。)我很感激你運行 javascript 來獲取更多專案(盡管對我來說,重新加載按鈕沒有做任何事情)在那種情況下,有必要。但是,我查看了該網站,發現可以以 JSON 格式(因此不需要 BS)和簡單的獲取請求來檢索您想要的資料。
import requests
data = requests.get("https://www.milanofinanza.it/Mercati/GetDataTabelle?alias=&campoOrdinamento=0002&numElem=30&ordinamento=asc&page=4&url=listino-completo-2ae?refresh_cens")
print(data.text)
或者這樣做,這樣更容易調整引數:
def pack(**kwargs):
return kwargs
data2 = requests.get("https://www.milanofinanza.it/Mercati/GetDataTabelle", params=pack(alias="",campoOrdinamento="0002",numElem=30,ordinamento="asc",page=4,url="listino-completo-2ae",refresh_cens=""))
我沒時間了;如果我得到了錯誤的資料,LMK,我會更正答案。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/438442.html
上一篇:嘗試在Python中使用Selenium登錄Twitter時無法找到電子郵件文本框的元素
下一篇:XPath找不到元素