我有一些資料如下:
| ID | 日期 | 代碼 | 價錢 |
|---|---|---|---|
| 892 | 2022-02-04 | 乙 | 472 |
| 891 | 2022-02-03 | 乙 | 58 |
| 890 | 2022-02-02 | 乙 | 467 |
| 868 | 2022-01-28 | 乙 | 50 |
| 821 | 2022-01-23 | 乙 | 45 |
| 780 | 2022-01-20 | 乙 | 55 |
| 550 | 2022-01-14 | 乙 | 79 |
| 245 | 2022-01-12 | 乙 | 841 |
| 112 | 2022-01-11 | 乙 | 128 |
| 91 | 2022-01-07 | 乙 | 174 |
| 74 | 2022-01-04 | 乙 | 64 |
我想獲得三個記錄的平均價格,從之前的第三行開始,在一個 SQL 查詢中包含到當前行,所以我期待如下:
| ID | 日期 | 代碼 | 價錢 | 平均第三 |
|---|---|---|---|---|
| 892 | 2022-02-04 | 乙 | 472 | ( 467 50 45) 的平均值 |
| 891 | 2022-02-03 | 乙 | 58 | (50 45 55) 的平均值 |
| 890 | 2022-02-02 | 乙 | 467 | (50 45 79) 的平均值 |
| 868 | 2022-01-28 | 乙 | 50 | (45 79 841) 的平均值 |
| 821 | 2022-01-23 | 乙 | 45 | (79 841 128) 的平均值 |
| 780 | 2022-01-20 | 乙 | 55 | (841 128 174) 的平均值 |
| 550 | 2022-01-14 | 乙 | 79 | ... |
| 245 | 2022-01-12 | 乙 | 841 | ... |
| 112 | 2022-01-11 | 乙 | 128 | ... |
| 91 | 2022-01-07 | 乙 | 174 | ... |
| 74 | 2022-01-04 | 乙 | 64 | ... |
我已經嘗試過,使用以下查詢:
SELECT t.id, t.date, t.code, t.price,
format(
CASE WHEN
ROW_NUMBER() OVER (ORDER BY t.date) >=5 THEN
AVG ( t.price ) OVER (ORDER BY t.date
ROWS BETWEEN 4 PRECEDING AND 2 FOLLOWING)
ELSE NULL
END,0) AS average_3th
FROM test t ORDER BY t.id DESC
但是,上面的查詢仍然包括第一個元素作為平均值(它應該從第三個元素開始),所以下面的結果仍然是錯誤的:
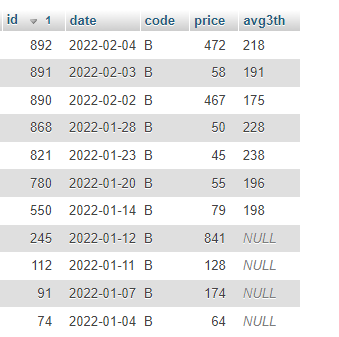
任何想法?
uj5u.com熱心網友回復:
在子查詢中使用行數想法平均值
WITH CTE AS
(SELECT T.*,ROW_NUMBER() OVER (PARTITION BY CODE ORDER BY ID DESC) RN FROM T ),
CTE1 AS
(SELECT T.*,ROW_NUMBER() OVER (PARTITION BY CODE ORDER BY ID DESC) RN FROM T )
SELECT CTE.*,
(SELECT AVG(CTE1.PRICE) FROM CTE1 WHERE CTE1.CODE = CTE.CODE AND CTE1.RN BETWEEN CTE.RN 2 AND CTE.RN 4),
(SELECT GROUP_CONCAT(CTE1.ID) FROM CTE1 WHERE CTE1.CODE = CTE.CODE AND CTE1.RN BETWEEN CTE.RN 2 AND CTE.RN 4)
FROM CTE
ORDER BY CTE.ID DESC
;
https://dbfiddle.uk/?rdbms=mysql_8.0&fiddle=437342579b3165f31292e288e3165bed
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/438531.html
標籤:mysql sql 数据库 phpmyadmin