我只想通過category使用 Xpath獲取資料
頁面鏈接: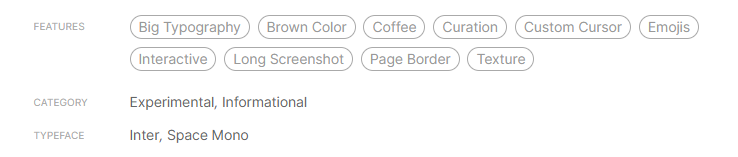
這是我的代碼:
from scrapy.http import Request
import scrapy
class PushpaSpider(scrapy.Spider):
name = 'pushpa'
start_urls = ['https://onepagelove.com/inspiration']
def parse(self, response):
books = response.xpath("//div[@class='thumb-image']//a//@href").extract()
for book in books:
absolute_url = response.urljoin(book)
yield Request(absolute_url, callback=self.parse_book)
def parse_book(self, response):
coordinate = response.xpath("//div[@class='inspo-links']//span[2]//text()").getall()
coordinate = [i.strip() for i in coordinate]
# remove empty strings:s
coordinate = [i for i in coordinate if i]
yield{
'category':coordinate
}
uj5u.com熱心網友回復:
該網站inspo-links在標題內有多個,因此您正在從許多不同型別的資料中提取。
Xpath 版本:
def parse_book(self, response):
xpath_coordinate = response.xpath(
"//span[@class='link-list']")[1].xpath("a/text()").extract()
yield {
'category': xpath_coordinate
}
CSS 版本:
def parse_book(self, response):
content = response.css('div.review-content')
coordinate = header.css("span.link-list")[1].css("a::text").extract()
yield {
'category': coordinate
}
此處的此代碼段將只為您提供類別。
在您的影像示例中,它會給您 ["Experimental", "Informational"]
注意:在您的主要方法中,您會獲得一個額外的鏈接,該鏈接不是書籍并且沒有類別,scrapy 會自動處理錯誤,因此您仍然可以獲得完整的輸出。
這是一個 Xpath 示例,它從影像中獲取所有 3 種型別的資料:
def parse_book(self, response):
xpath_coordinate = response.xpath(
"//span[@class='link-list']")
features = xpath_coordinate[0].xpath("a/text()").extract()
category = xpath_coordinate[1].xpath("a/text()").extract()
typeface = xpath_coordinate[2].xpath("a/text()").extract()
yield {
'feature': features,
'category': category,
'typeface': typeface
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/439591.html
上一篇:如何從抓取的鏈接中洗掉后綴?