我正在嘗試使用 Seaborn 庫繪制資料,其中:
x 軸 - 電影發行年份
y 軸 - 電影評分(0-10,離散)
我目前正在使用散點圖。我的資料在 Pandas 資料框中。
顯然,因為我擁有的評級資料是離散整數,所以它們中的很多都堆疊在一起。如何使每個點的大小與資料集中出現的頻率一致?
例如,如果 2008 年 6/10 評級的數量高于任何其他評級/年份組合,我希望該點大小(或圖中的其他內容)來表明這一點。
我應該使用不同的情節來代替這樣的事情嗎?
uj5u.com熱心網友回復:
我應該使用不同的情節來代替這樣的事情嗎?
我建議將其可視化為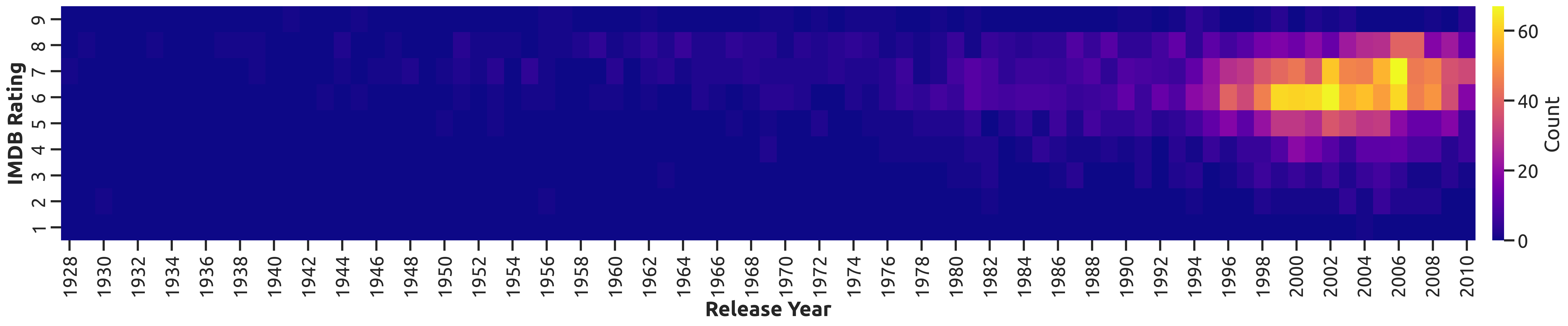
但是,如果您仍然喜歡
參考資料:
url = 'https://raw.githubusercontent.com/vega/vega/main/docs/data/movies.json'
df = pd.read_json(url)[['Title', 'Release Date', 'IMDB Rating']]
df['IMDB Rating'] = df['IMDB Rating'].round().astype('Int8')
df['Release Year'] = pd.to_datetime(df['Release Date']).dt.year
df = df.loc[df['Release Year'] <= 2010]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/447249.html
標籤:Python 熊猫 matplotlib 海运 数据可视化
上一篇:pyplot3dz軸對數圖