我仍在努力尋找一種方法并考慮最好的開始方式。不幸的是,我在互聯網上沒有找到任何可比的東西——也許你可以給我一些建議。
為此,我創建了一個小型示例資料集;初始情況:
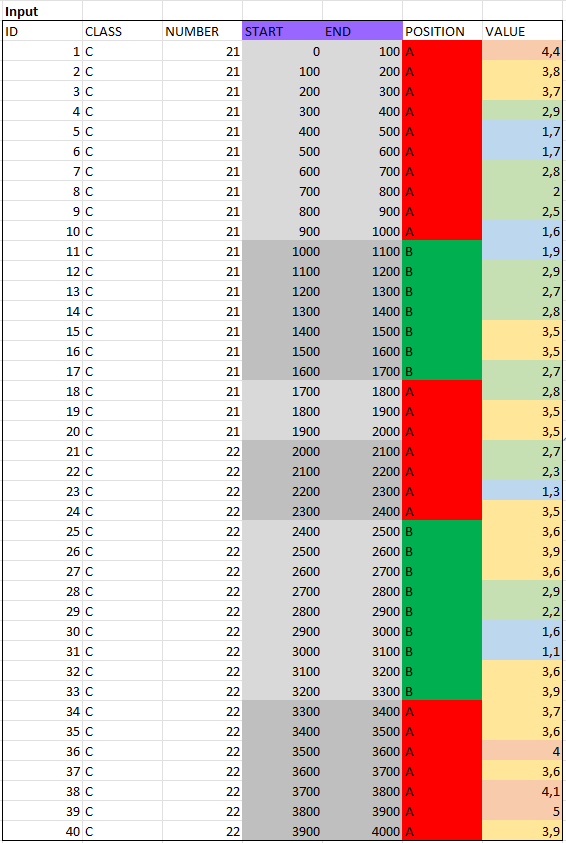
我想以某種方式準備資料,以便連續添加類(C1 到 C4)的長度 - 一方面 POSITION 欄位和另一方面 NUMBER 欄位用作“分隔符”。我認為一張圖片更好地描述了它:
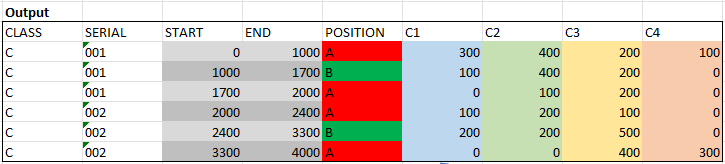
長度由 (END - START) 相應確定。
這是 Excel 檔案:https ://easyupload.io/vb86lh
單擊此處的按鈕(不是其他內容):
到目前為止,這是我的開始:
import pandas as pd
d = {
'ID': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40],
'CLASS': ['C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C'],
'NUMBER': [21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22],
'START': [0, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000, 2100, 2200, 2300, 2400, 2500, 2600, 2700, 2800, 2900, 3000, 3100, 3200, 3300, 3400, 3500, 3600, 3700, 3800, 3900],
'END': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000, 2100, 2200, 2300, 2400, 2500, 2600, 2700, 2800, 2900, 3000, 3100, 3200, 3300, 3400, 3500, 3600, 3700, 3800, 3900, 4000],
'POSITION': ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'A', 'A', 'A', 'A', 'A', 'A', 'A'],
'VALUE': [4.4, 3.8, 3.7, 2.9, 1.7, 1.7, 2.8, 2.0, 2.5, 1.6, 1.9, 2.9, 2.7, 2.8, 3.5, 3.5, 2.7, 2.8, 3.5, 3.5, 2.7, 2.3, 1.3, 3.5, 3.6, 3.9, 3.6, 2.9, 2.2, 1.6, 1.1, 3.6, 3.9, 3.7, 3.6, 4.0, 3.6, 4.1, 5.0, 3.9]
}
df = pd.DataFrame(data=d)
for number in df['NUMBER'].unique().tolist():
print('to do')
As you can see, I am not yet sure how best to approach the whole thing. I'm not sure if I have to work with .groupby() or if I have to iterate through the dataframe, or even both. Do you have any tips?
Im still trying to find an efficient approach. Do you have any advise?
uj5u.com熱心網友回復:
第一個問題是將它分組。
標準groupby("POSITION")inpandas只會創建兩個組:A(with all A) 和B(with all ),并且在更改值B時不能拆分這些組。POSITION而且我沒有看到其他可以提供幫助的專欄。
但itertools.groupby()創建預期組
import pandas as pd
data = {
'ID': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40],
'CLASS': ['C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C'],
'NUMBER': [21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22],
'START': [0, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000, 2100, 2200, 2300, 2400, 2500, 2600, 2700, 2800, 2900, 3000, 3100, 3200, 3300, 3400, 3500, 3600, 3700, 3800, 3900],
'END': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000, 2100, 2200, 2300, 2400, 2500, 2600, 2700, 2800, 2900, 3000, 3100, 3200, 3300, 3400, 3500, 3600, 3700, 3800, 3900, 4000],
'POSITION': ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'A', 'A', 'A', 'A', 'A', 'A', 'A'],
'VALUE': [4.4, 3.8, 3.7, 2.9, 1.7, 1.7, 2.8, 2.0, 2.5, 1.6, 1.9, 2.9, 2.7, 2.8, 3.5, 3.5, 2.7, 2.8, 3.5, 3.5, 2.7, 2.3, 1.3, 3.5, 3.6, 3.9, 3.6, 2.9, 2.2, 1.6, 1.1, 3.6, 3.9, 3.7, 3.6, 4.0, 3.6, 4.1, 5.0, 3.9]
}
df = pd.DataFrame(data)
# it creates only two groups
#for val, grp in df.groupby('POSITION', sort=False):
# print(val)
import itertools
for (position, number), group in itertools.groupby(df.iterrows(), key=lambda item:(item[1]['POSITION'], item[1]['NUMBER']) ):
rows = (item[1] for item in group)
new_df = pd.DataFrame(rows)
print(new_df)
print('---')
給
ID CLASS NUMBER START END POSITION VALUE
0 1 C 21 0 100 A 4.4
1 2 C 21 100 200 A 3.8
2 3 C 21 200 300 A 3.7
3 4 C 21 300 400 A 2.9
4 5 C 21 400 500 A 1.7
5 6 C 21 500 600 A 1.7
6 7 C 21 600 700 A 2.8
7 8 C 21 700 800 A 2.0
8 9 C 21 800 900 A 2.5
9 10 C 21 900 1000 A 1.6
---
ID CLASS NUMBER START END POSITION VALUE
10 11 C 21 1000 1100 B 1.9
11 12 C 21 1100 1200 B 2.9
12 13 C 21 1200 1300 B 2.7
13 14 C 21 1300 1400 B 2.8
14 15 C 21 1400 1500 B 3.5
15 16 C 21 1500 1600 B 3.5
16 17 C 21 1600 1700 B 2.7
---
ID CLASS NUMBER START END POSITION VALUE
17 18 C 21 1700 1800 A 2.8
18 19 C 21 1800 1900 A 3.5
19 20 C 21 1900 2000 A 3.5
---
ID CLASS NUMBER START END POSITION VALUE
20 21 C 22 2000 2100 A 2.7
21 22 C 22 2100 2200 A 2.3
22 23 C 22 2200 2300 A 1.3
23 24 C 22 2300 2400 A 3.5
---
ID CLASS NUMBER START END POSITION VALUE
24 25 C 22 2400 2500 B 3.6
25 26 C 22 2500 2600 B 3.9
26 27 C 22 2600 2700 B 3.6
27 28 C 22 2700 2800 B 2.9
28 29 C 22 2800 2900 B 2.2
29 30 C 22 2900 3000 B 1.6
30 31 C 22 3000 3100 B 1.1
31 32 C 22 3100 3200 B 3.6
32 33 C 22 3200 3300 B 3.9
---
ID CLASS NUMBER START END POSITION VALUE
33 34 C 22 3300 3400 A 3.7
34 35 C 22 3400 3500 A 3.6
35 36 C 22 3500 3600 A 4.0
36 37 C 22 3600 3700 A 3.6
37 38 C 22 3700 3800 A 4.1
38 39 C 22 3800 3900 A 5.0
39 40 C 22 3900 4000 A 3.9
---
下一步是計算“顏色”,VALUE但如果我用C1, C2, C3, . 創建新列會更簡單C4。
df['COLOR'] = 'C0' # default value at start
df.loc[ (4 <= df['VALUE']), 'COLOR'] = 'C4'
df.loc[ (3 <= df['VALUE']) & (df['VALUE'] < 4), 'COLOR' ] = 'C3'
df.loc[ (2 <= df['VALUE']) & (df['VALUE'] < 3), 'COLOR' ] = 'C2'
df.loc[ (df['VALUE'] < 2), 'COLOR' ] = 'C1'
ID CLASS NUMBER START END POSITION VALUE COLOR
0 1 C 21 0 100 A 4.4 C4
1 2 C 21 100 200 A 3.8 C3
2 3 C 21 200 300 A 3.7 C3
3 4 C 21 300 400 A 2.9 C2
4 5 C 21 400 500 A 1.7 C1
5 6 C 21 500 600 A 1.7 C1
6 7 C 21 600 700 A 2.8 C2
7 8 C 21 700 800 A 2.0 C2
8 9 C 21 800 900 A 2.5 C2
9 10 C 21 900 1000 A 1.6 C1
10 11 C 21 1000 1100 B 1.9 C1
11 12 C 21 1100 1200 B 2.9 C2
12 13 C 21 1200 1300 B 2.7 C2
13 14 C 21 1300 1400 B 2.8 C2
14 15 C 21 1400 1500 B 3.5 C3
15 16 C 21 1500 1600 B 3.5 C3
16 17 C 21 1600 1700 B 2.7 C2
17 18 C 21 1700 1800 A 2.8 C2
18 19 C 21 1800 1900 A 3.5 C3
19 20 C 21 1900 2000 A 3.5 C3
20 21 C 22 2000 2100 A 2.7 C2
21 22 C 22 2100 2200 A 2.3 C2
22 23 C 22 2200 2300 A 1.3 C1
23 24 C 22 2300 2400 A 3.5 C3
24 25 C 22 2400 2500 B 3.6 C3
25 26 C 22 2500 2600 B 3.9 C3
26 27 C 22 2600 2700 B 3.6 C3
27 28 C 22 2700 2800 B 2.9 C2
28 29 C 22 2800 2900 B 2.2 C2
29 30 C 22 2900 3000 B 1.6 C1
30 31 C 22 3000 3100 B 1.1 C1
31 32 C 22 3100 3200 B 3.6 C3
32 33 C 22 3200 3300 B 3.9 C3
33 34 C 22 3300 3400 A 3.7 C3
34 35 C 22 3400 3500 A 3.6 C3
35 36 C 22 3500 3600 A 4.0 C4
36 37 C 22 3600 3700 A 3.6 C3
37 38 C 22 3700 3800 A 4.1 C4
38 39 C 22 3800 3900 A 5.0 C4
39 40 C 22 3900 4000 A 3.9 C3
接下來我可以計算每組中的顏色并乘以 100
在組中我可以添加START和END(和其他值)
result = pd.DataFrame()
for (position, number), group in itertools.groupby(df.iterrows(), key=lambda item:(item[1]['POSITION'], item[1]['NUMBER']) ):
rows = (item[1] for item in group)
new_df = pd.DataFrame(rows)
#print(new_df)
count = new_df['COLOR'].value_counts()*100
count['CLASS'] = 'C'
count['POSITION'] = position
count['START'] = new_df['START'].min()
count['END'] = new_df['END'].max()
count['SERIAL'] = number % 10
#print(count)
result = result.append(count, ignore_index=True)
#print('---')
創建result后需要填充空白處,設定int列的型別和更改順序
# fill empty cell
result = result.fillna(0)
# set type `int`
result[['C1','C2','C3','C4','START','END','SERIAL']] = result[['C1','C2','C3','C4','START','END','SERIAL']].astype(int)
# change columns order
result = result[['CLASS','SERIAL','START','END','POSITION','C1','C2','C3','C4']]
print(result)
最后結果:
CLASS SERIAL START END POSITION C1 C2 C3 C4
0 C 1 0 1000 A 300 400 200 100
1 C 1 1000 1700 B 100 400 200 0
2 C 1 1700 2000 A 0 100 200 0
3 C 2 2000 2400 A 100 200 100 0
4 C 2 2400 3300 B 200 200 500 0
5 C 2 3300 4000 A 0 0 400 300
如果end - start可以不同于 100,那么您可以創建列
df['LENGTH'] = df['END'] - df['START']
and later group by COLOR and sum LENGTH
count = new_df.groupby('COLOR')['LENGTH'].sum()
EDIT: I added this to code.
Full code:
import pandas as pd
import itertools
data = {
'ID': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40],
'CLASS': ['C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C'],
'NUMBER': [21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22],
'START': [0, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000, 2100, 2200, 2300, 2400, 2500, 2600, 2700, 2800, 2900, 3000, 3100, 3200, 3300, 3400, 3500, 3600, 3700, 3800, 3900],
'END': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000, 2100, 2200, 2300, 2400, 2500, 2600, 2700, 2800, 2900, 3000, 3100, 3200, 3300, 3400, 3500, 3600, 3700, 3800, 3900, 4000],
'POSITION': ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'A', 'A', 'A', 'A', 'A', 'A', 'A'],
'VALUE': [4.4, 3.8, 3.7, 2.9, 1.7, 1.7, 2.8, 2.0, 2.5, 1.6, 1.9, 2.9, 2.7, 2.8, 3.5, 3.5, 2.7, 2.8, 3.5, 3.5, 2.7, 2.3, 1.3, 3.5, 3.6, 3.9, 3.6, 2.9, 2.2, 1.6, 1.1, 3.6, 3.9, 3.7, 3.6, 4.0, 3.6, 4.1, 5.0, 3.9]
}
df = pd.DataFrame(data)
#for val, grp in df.groupby('POSITION', sort=False):
# print(val)
df['COLOR'] = 'C0' # default value at start
df.loc[ (df['VALUE'] < 2), 'COLOR' ] = 'C1'
df.loc[ (2 <= df['VALUE']) & (df['VALUE'] < 3), 'COLOR' ] = 'C2'
df.loc[ (3 <= df['VALUE']) & (df['VALUE'] < 4), 'COLOR' ] = 'C3'
df.loc[ (4 <= df['VALUE']), 'COLOR'] = 'C4'
df['LENGTH'] = df['END'] - df['START']
#print(df)
result = pd.DataFrame()
for (position, number), group in itertools.groupby(df.iterrows(), key=lambda item:(item[1]['POSITION'], item[1]['NUMBER']) ):
rows = (item[1] for item in group)
new_df = pd.DataFrame(rows)
#print(new_df)
#count = new_df['COLOR'].value_counts()*100
count = new_df.groupby('COLOR')['LENGTH'].sum()
count['CLASS'] = 'C'
count['POSITION'] = position
count['START'] = new_df['START'].min()
count['END'] = new_df['END'].max()
count['SERIAL'] = number % 10
#print(count)
result = result.append(count, ignore_index=True)
#print('---')
# fill empty cells
result = result.fillna(0)
# set type `int`
result[['C1','C2','C3','C4','START','END','SERIAL']] = result[['C1','C2','C3','C4','START','END','SERIAL']].astype(int)
# change columns order
result = result[['CLASS','SERIAL','START','END','POSITION','C1','C2','C3','C4']]
print(result)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/448415.html