我目前有兩個資料框,看起來有點像這樣,但要大得多。資料框 1:
| 第一季度 | 第二季度 | 第三季度 | 第四季度 | Q5 | Q6 |
|---|---|---|---|---|---|
| 一種 | b | C | d | e | F |
資料框 2:
| 第一季度 | 第二季度 | 第三季度 | 第四季度 |
|---|---|---|---|
| 一種 | b | d | F |
因此,資料幀 2 與資料幀 1 相同,但缺少資料幀 1 中的 Q3 和 Q5。資料幀 2 中的 Q3 相當于資料幀 1 中的 Q4,資料幀 2 中的 Q4 與資料幀 1 中的 Q6 相同。我想將這兩個表合并在一起,看起來像這樣:
| 第一季度 | 第二季度 | 第三季度 | 第四季度 | Q5 | Q6 |
|---|---|---|---|---|---|
| 一種 | b | C | d | e | F |
| 一種 | b | 空值 | d | 空值 | F |
實際上,我的表要大得多,并且第二個表中的列和缺少的問題比此示例中顯示的要多得多。所以我只是想知道是否有人有辦法這樣做,這樣我就不必手動重命名和填充所有列。謝謝你。
uj5u.com熱心網友回復:
我認為您所描述的操作pd.concat正如@sammywemmy 所說。
import pandas as pd
df1 = pd.DataFrame({'Q1': ['a'], 'Q2': ['b'], 'Q3': ['c'], 'Q4': ['d'], 'Q5': ['e'], 'Q6': ['f']})
df2 = pd.DataFrame({'Q1': ['a'], 'Q2': ['b'], 'Q3': ['d'], 'Q4': ['f']})
print(pd.concat([df1, df2]))
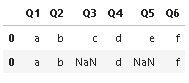
輸出:
Q1 Q2 Q3 Q4 Q5 Q6
0 a b c d e f
0 a b d f NaN NaN
uj5u.com熱心網友回復:
采用:
nind1 = df2.columns.values.copy()
nind2 = np.unique(np.append(nind1, qindf1notdf2))
deff = len(nind2)-len(nind1)
for i, x in enumerate(nind2):
if x in qindf1notdf2:
nind2[nind2>=x] = [re.sub('\d', lambda s: str(int(s.group(0)) 1), y) for y in nind2[nind2>=x]]
ncols = nind2[:-deff]
df2.columns = ncols
pd.concat([df1, df2])
輸出:
uj5u.com熱心網友回復:
您可以撰寫一個輔助函式來自動重命名第二個資料幀。您需要知道的只是缺失問題的串列。我在這里df1用作名稱的來源,但您也可以使用連續的“Q1”、“Q2”...“Qn”的生成器。
def rename(df, skip=[], ref=df1):
skip = set(skip)
cols = (c for c in ref.columns if c not in skip)
return df.rename(columns=dict(zip(df.columns, cols)))
pd.concat([df1, rename(df2, skip=['Q3', 'Q5'])], ignore_index=True)
輸出:
Q1 Q2 Q3 Q4 Q5 Q6
0 a b c d e f
1 a b NaN d NaN f
帶有 Qx 生成器的輔助函式
這個完全依賴于位置,所以如果名稱不完美,即使在 df1 中也可以使用它
def rename(df, skip=[]):
skip = set(skip)
cols = (f'Q{i}' for i in range(1, len(df.columns) len(skip) 1)
if i not in skip)
return df.set_axis(cols, axis=1)
pd.concat([rename(df1), rename(df2, skip=[3,5])], ignore_index=True)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/455908.html
上一篇:使用Python打開CSV串列并將列unixtime修改為datetime-它錯誤
下一篇:如何從某一列中減去選定的列?