我正在嘗試從此頁面中提取一些文本
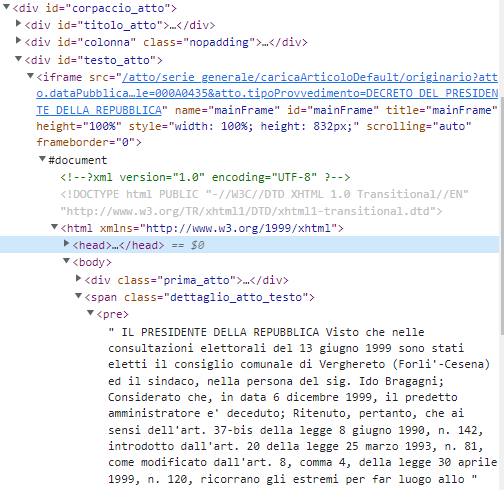
特別是我想提取標簽之間的文本。我正在使用 Selenium 和以下代碼,但即使物件被識別,文本也是一個空字串。下面是我正在使用的代碼:
testo = driver.find_element_by_xpath('/html/body/span/pre[1]').text
你認為這可能是什么問題?
uj5u.com熱心網友回復:
<pre>標簽內的文本在一個<iframe>
因此,要提取所需的文本,您必須:
誘導WebDriverWait使所需的幀可用并切換到它。
誘導WebDriverWait使所需元素成為可點擊的。
您可以使用以下任一定位器策略:
使用CSS_SELECTOR:
WebDriverWait(driver, 20).until(EC.frame_to_be_available_and_switch_to_it((By.CSS_SELECTOR,"iframe#mainFrame"))) print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "span.dettaglio_atto_testo"))).get_attribute("innerHTML"))使用XPATH:
WebDriverWait(driver, 20).until(EC.frame_to_be_available_and_switch_to_it((By.XPATH,"//iframe[@id='mainFrame']"))) print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//span[@class='dettaglio_atto_testo']/pre"))).text)
注意:您必須添加以下匯入:
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC
uj5u.com熱心網友回復:
首先,您應該切換到iframe. 然后你可以使用.getText()方法。
如果它不起作用,你可以試試這個:.getAttribute("innerText")
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/460067.html
上一篇:嘗試使用beautifulsoup抓取2個標簽并將它們放在同一個csv中
下一篇:從動態網頁中抓取不可互動的表格