字串匹配基礎(中)—— BM演算法
- Ⅰ 前言
- Ⅱ BM 演算法核心思想
- Ⅲ BM 演算法原理分析
- 1. 壞字符規則
- 2. 好后綴規則
- Ⅳ BM 演算法代碼實作
- 1. 壞字符規則
- 2. 好后綴規則
- 3. 代碼完整實作
- Ⅴ BM 演算法的性能分析及優化
Ⅰ 前言
文本編輯器的查找替換功能相信大家都不陌生,很多 IDE 像 Eclipse,IntelliJ,包括 Word,都有這個功能,把一個詞統一替換成另一個,那這個功能是如何實作的呢?
如果用前一篇文章里的 BF 演算法和 RK 演算法,當然可以實作這個功能,但是在某些極端情況下,BF 演算法性能會退化得比較嚴重,而 RK 演算法需要用到哈希演算法,但是設計出一個可以應對各種型別字符的哈希演算法并不簡單,
對于工業級的軟體開發來說,我們希望演算法盡可能的高效,并且在極端情況下,性能也不要退化得太嚴重,那么,對于查找功能是重要功能的軟體來說,比如一些文本編輯器,它們的查找功能都是用哪種演算法來實作的呢?有沒有比 BF 演算法和 RK 演算法更加高效的字串匹配演算法呢?
這就引出了我們這篇文章要講的一個演算法,BM(Boyer-Moore) 演算法,它是一種非常高效的字串匹配演算法,有實驗統計,它的性能是著名的 KMP 演算法的 3 到 4 倍,BM 演算法的原理很復雜,比較難懂,我會在王爭老師的課程的基礎,再加上我的理解,希望能把這個演算法講得更清楚一點,
如果對 BF 演算法和 RK 演算法還不熟悉的同學,如果有興趣,可以跳轉到下面的鏈接去看看,
【資料結構與演算法】->演算法->字串匹配基礎(上)->BF 演算法 & RK 演算法
Ⅱ BM 演算法核心思想
我們把模式串和主串的匹配程序,看作模式串在主串中不停地往后滑動,當遇到不匹配的字符時,BF 演算法和 RK 演算法的做法是,模式串往后滑動一位,然后從模式串的第一個字符開始重新匹配,如下面的這張圖👇
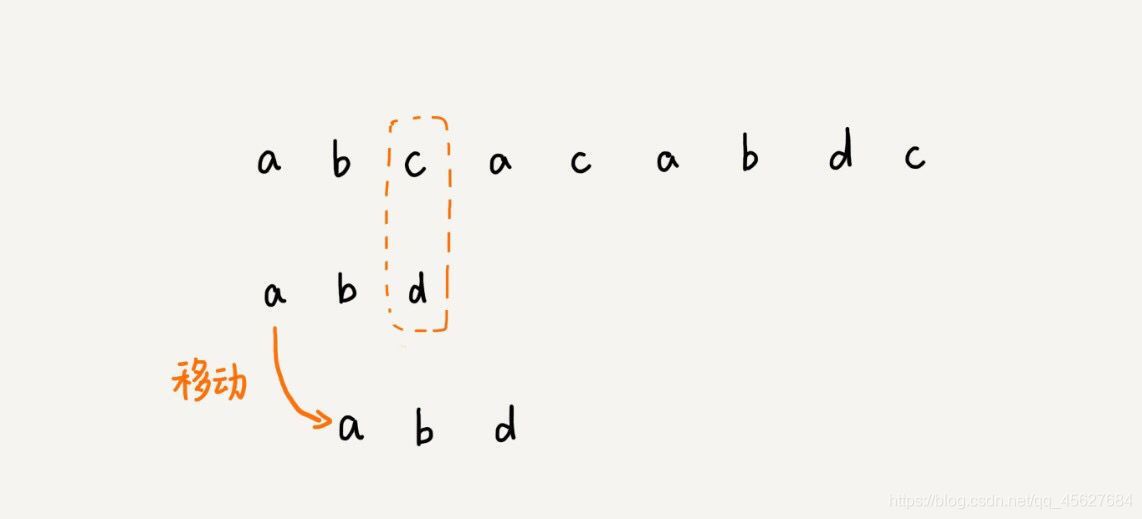
在這個例子里,主串中的 c ,在模式串中是不存在的,所以,模式串向后滑動的時候,只要 c 與模式串有重合,肯定無法匹配,所以,我們可以一次性把模式串往后多滑動幾位,把模式串移動到 c 的后面,
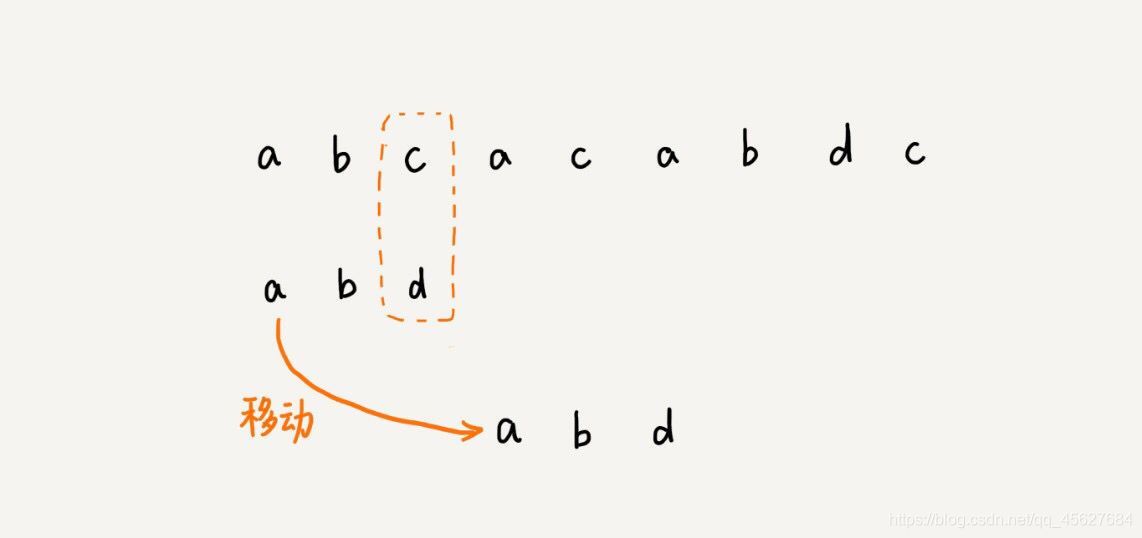
所以,當遇到不匹配的字符時,有什么固定的規律,可以將模式串往后多滑動幾位呢?這樣移動地越快,匹配的效率就更高了,
BM 演算法本質上其實就是在尋找這種規律,借助這種規律,在模式串與主串匹配的程序中,當模式串和主串某個字符不匹配的時候,能夠跳過一些肯定不會匹配的情況,將模式串往后多滑動幾位,
Ⅲ BM 演算法原理分析
BM 演算法包括兩部分,分別是 壞字符規則(bad character rule) 和 好后綴規則(good suffix shift),我們分別來看一看,
1. 壞字符規則
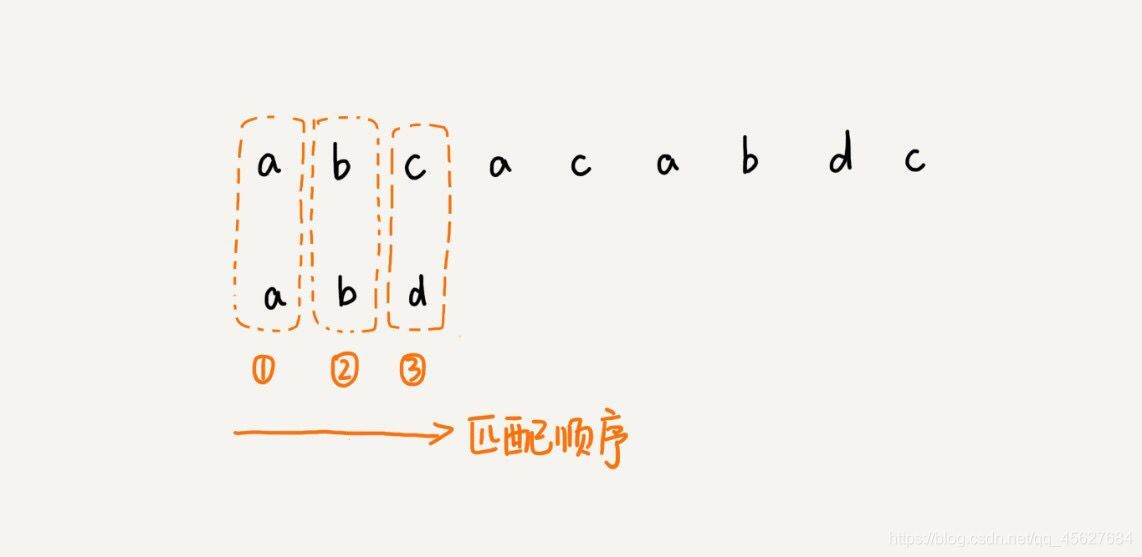
前面講的 BF 演算法和 RK 演算法,在匹配的程序中,都是按照模式串的下標從小到大的順序,依次與主串中的字符進行匹配的,這種匹配順序比較符合我們的思維習慣,但是 BM 演算法的匹配順序很特別,它是按照模式串下標從大到小,倒著匹配的,
BF 演算法👇
BM 演算法👇
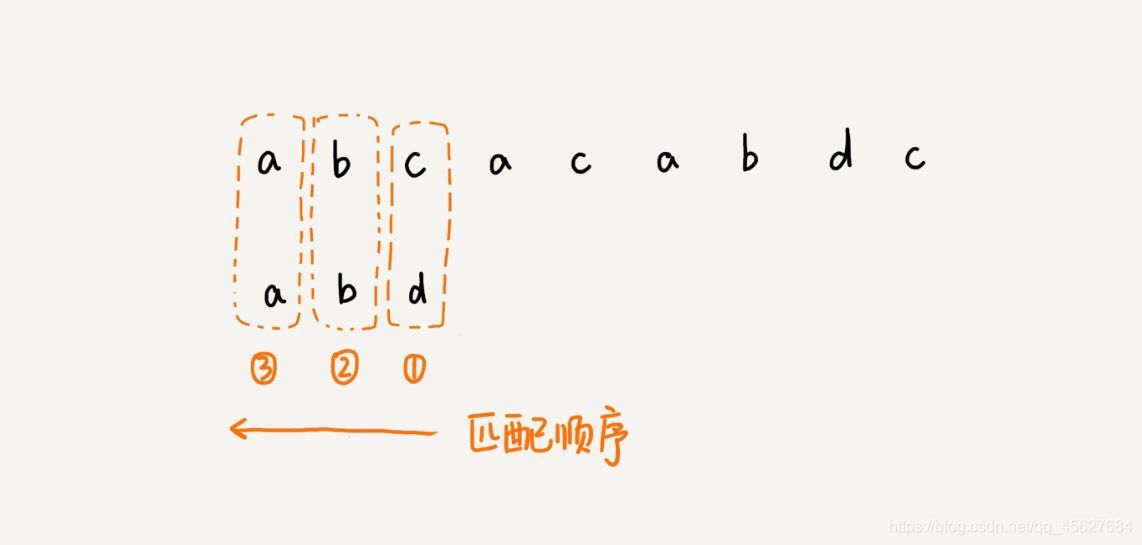
我們從模式串的末尾倒著匹配,當我們發現某個字符沒法匹配的時候,我們把這個字符叫作 壞字符(主串中的字符),
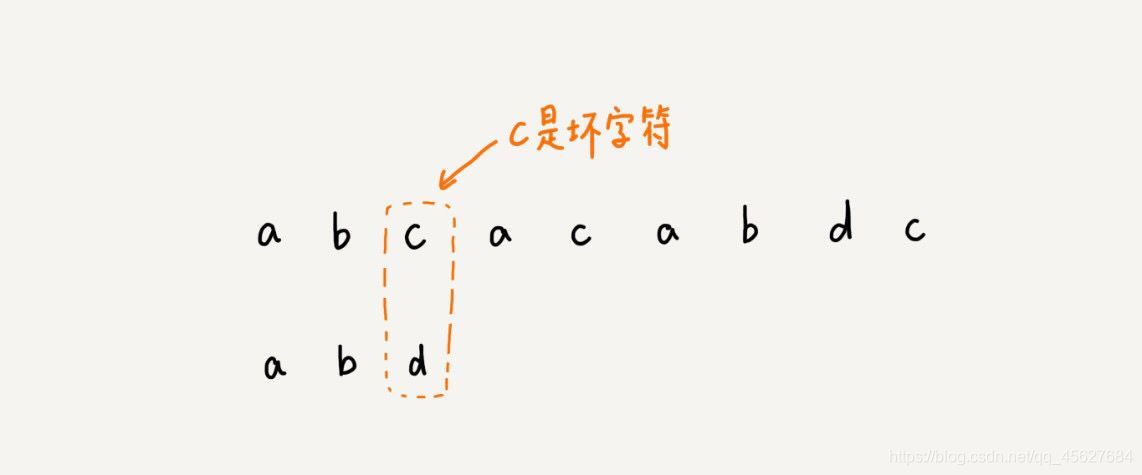
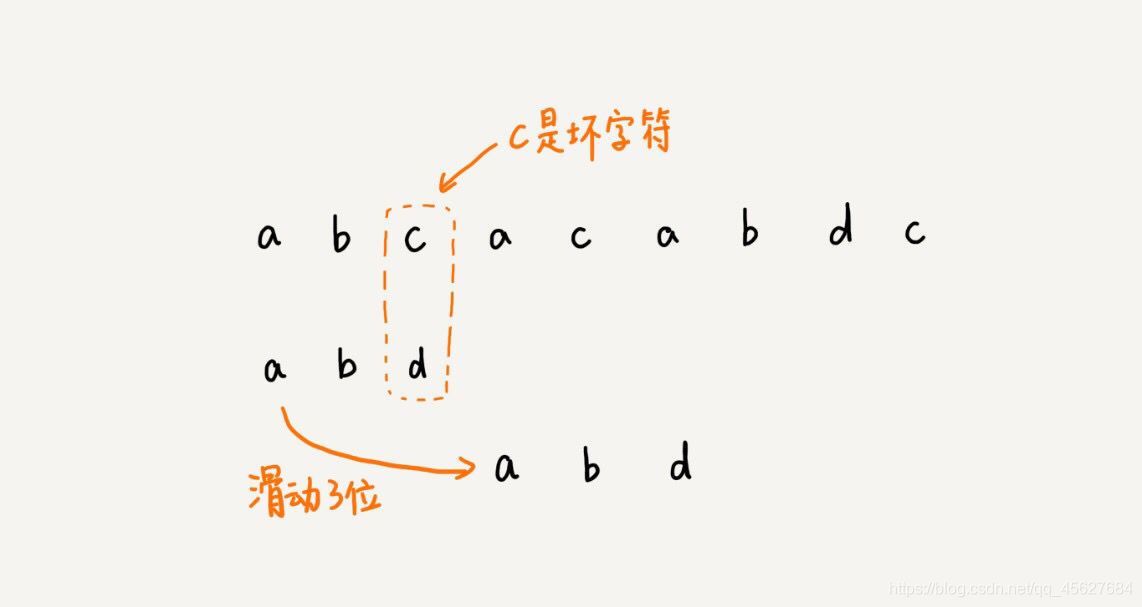
我們拿壞字符 c 在模式串中查找,發現模式串中并不存在這個字符,也就是說,字符 c 與模式串中的任何字符都不可能匹配,這個時候,我們可以將模式串直接往后滑動三位,將模式串滑動到 c 后面的位置,再從模式串的末尾字符開始比較,
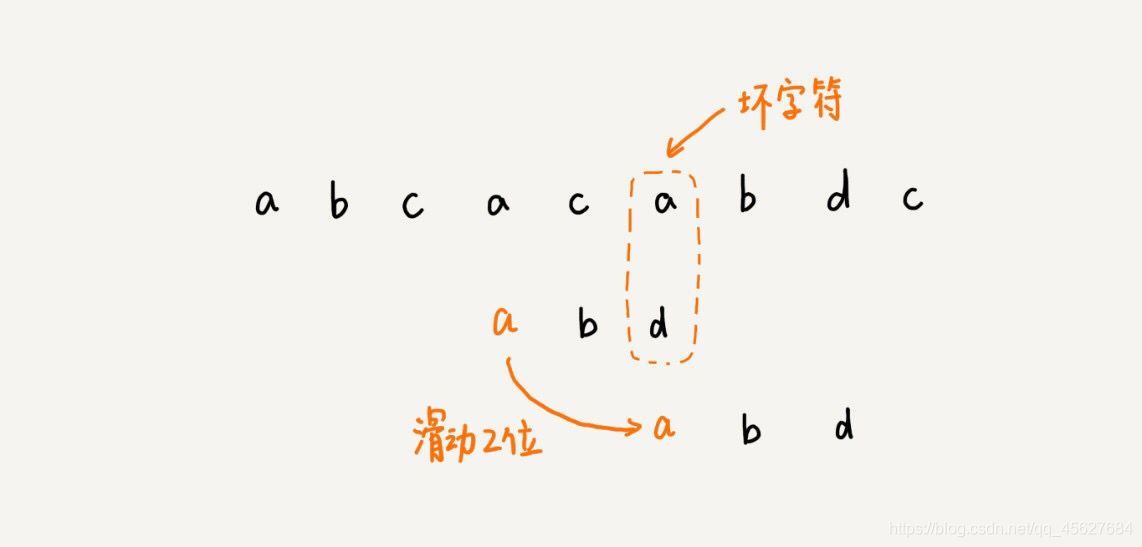
這個時候,我們發現,模式串中最后一個字符 d,還是無法和主串中的 a 匹配,這個時候,還能將模式串往后滑動三位嗎?答案是不行的,因為這個時候,壞字符 a 在模式串中是存在的,模式串中下標是 0 的位置也是字符 a,這種情況下,我們可以將模式串往后滑動兩位,讓兩個 a 上下對齊,然后再從模式串的末尾字符開始,重新匹配,
第一次匹配的時候,我們滑動了三位,第二次匹配的時候,我們滑動了兩位,那具體滑動多少位,是不是可以總結出一個規律來?
當發生不匹配的時候,我們把壞字符對應的模式串中的字符下標記作 si,如果壞字符在模式串中存在,我們把這個壞字符在模式串中的下標記作 xi,如果不存在,我們把 xi 記作 -1,那么,模式串往后移動的位數就等于 si-xi,
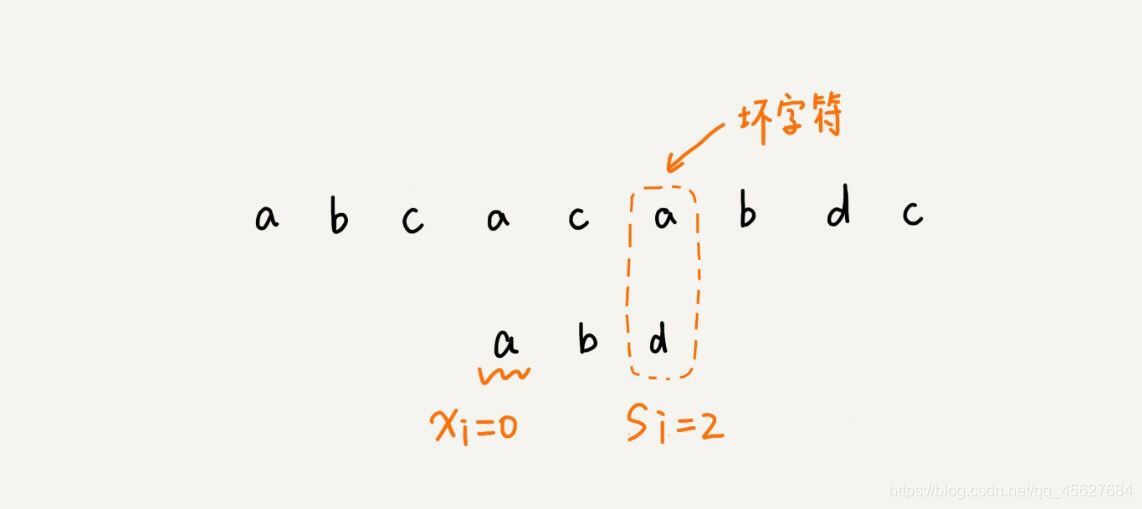
這里還有一點需要注意,就是如果壞字符在模式串里多次出現,那我們在計算 xi 的時候,選擇最靠后的那個,因為這樣就不會讓模式串滑動過多,導致本來可能匹配的情況被滑動略過,
利用壞字符規則,BM 演算法在最好情況下的時間復雜度非常低,是 O(n/m) ,比如,主串是 aaabaaabaaabaaab,模式串是 aaaa,每次比對,模式串都可以直接后移四位,所以,匹配具有類似特點的模式串和主串的時候,BM 演算法非常高效,
不過,單純使用壞字符規則還不夠,因為 si - xi 計算出來的移動位數,有可能是負數,比如主串是 aaaaaaaaaaaaaa,模式串是 baaa,第一次比對, si 也就是壞字符對應的模式串中的字符下標,所以就是 0(b 是壞字符);xi 就是壞字符在模式串中的下標,也就是 3(字符多次出現,取靠后的),因而 si - xi = -3 ,
利用壞字符規則,BM 演算法在最好情況下時間復雜度非常低,是 O(n/m),比如,主串是 aaabaaabaaabaaab,模式串是 aaaa,每次比對,模式串都可以直接后移四位,所以,匹配具有類似特點的的模式串和主串的時候,BM 演算法非常高效,
不過,單純使用壞字符規則還是不夠的,因為根據 si - xi 計算出來的移動次數,有可能是負數,不但不會向后滑動模式串,還有可能倒退,所以,BM 演算法還需要用到 “好后綴規則”,
2. 好后綴規則
好后綴規則實際上跟壞字符規則的思路很類似,比如下面這張圖,當模式串滑動到圖中的位置的時候,模式串和主串有 2 個字符是匹配的,倒數第 3 個字符發生了不匹配的情況,
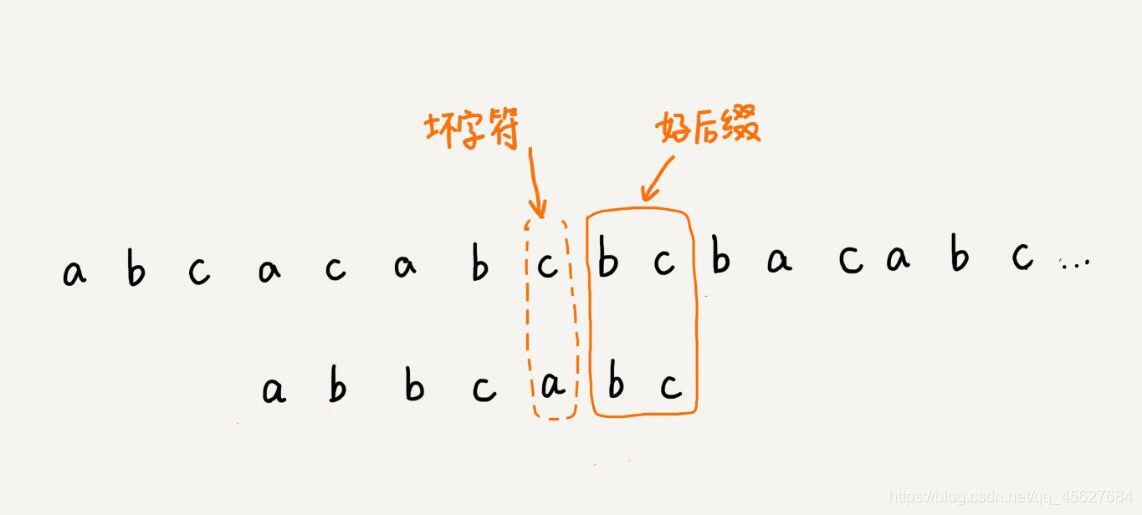
這個時候該如何滑動字串呢?當然,我們還可以利用壞字符規則來計算模式串的滑動位數,但是壞字符規則正如我們上面所說不是時時刻刻都有效的,所以我們還需要使用好后綴規則,兩個配合使用,
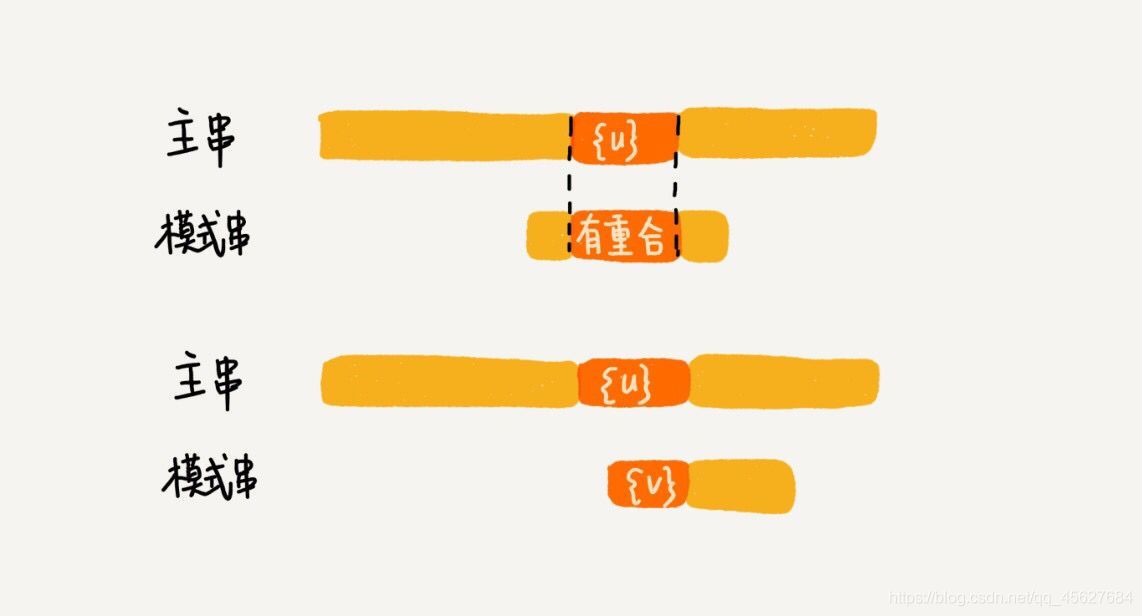
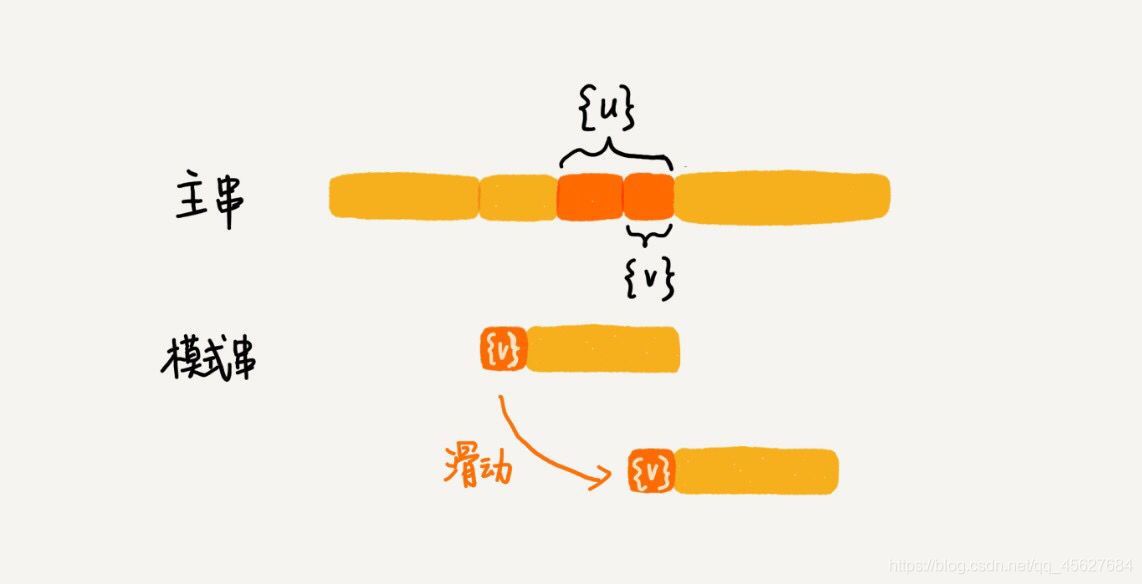
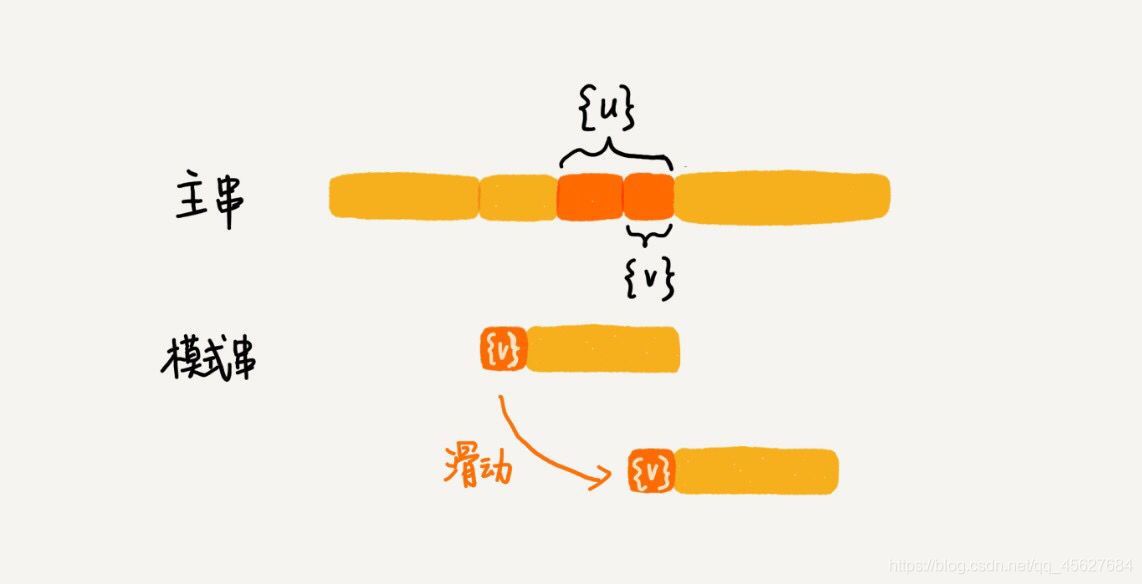
我們把已經匹配好的 b c 叫作好后綴,記作 {u},我們拿它在模式串中查找,如果找到了另一個跟 {u} 相匹配的子串 {u*},那我們就將模式串滑動到子串 {u*} 與主串中 {u} 對齊的位置,
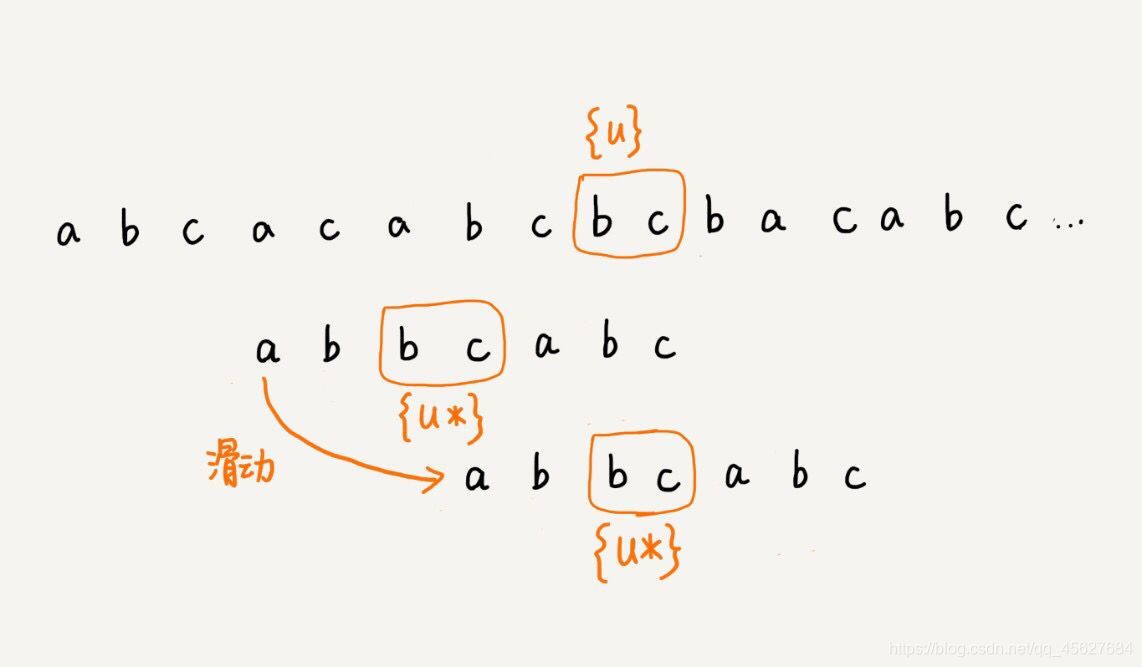
如果在模式串中找不到另一個等于 {u} 的子串,我們就直接將模式串滑動到主串中 {u} 的后面,因為之前的任何一次往后滑動,都沒有匹配主串中 {u} 的情況,
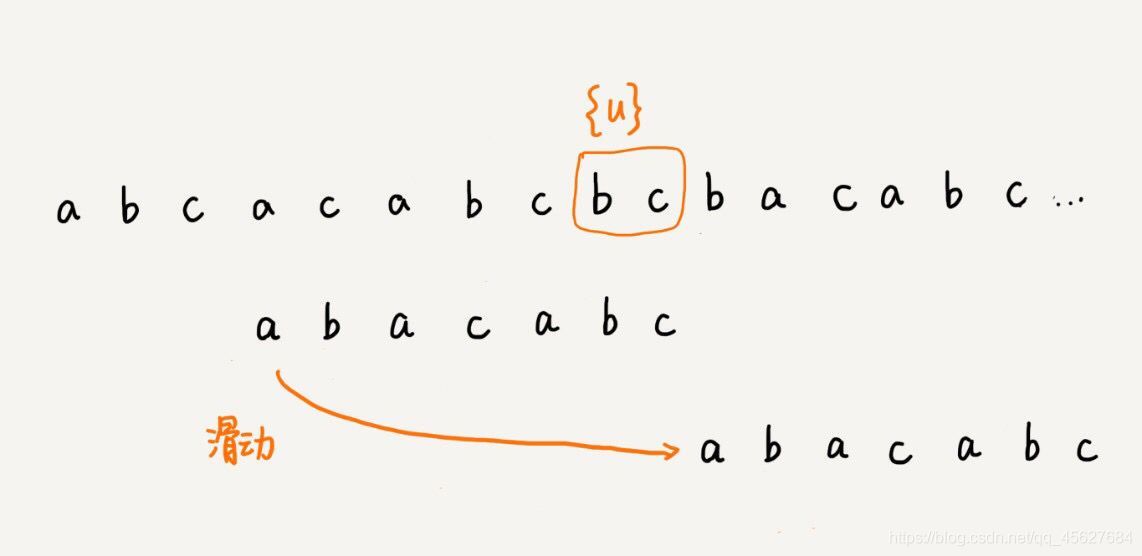
不過,當模式串中不存在等于 {u} 的子串的時候,我們直接將模式串滑動到主串 {u} 的后面,這樣做會不會跳過頭呢?我們看下面這種情況,這里面 b c 是好后綴,盡管在模式串中沒有另外一個相匹配的子串 {u*},但是如果我們將模式串移動到好后綴的后面,那就會錯過模式串和主串可以匹配的情況,
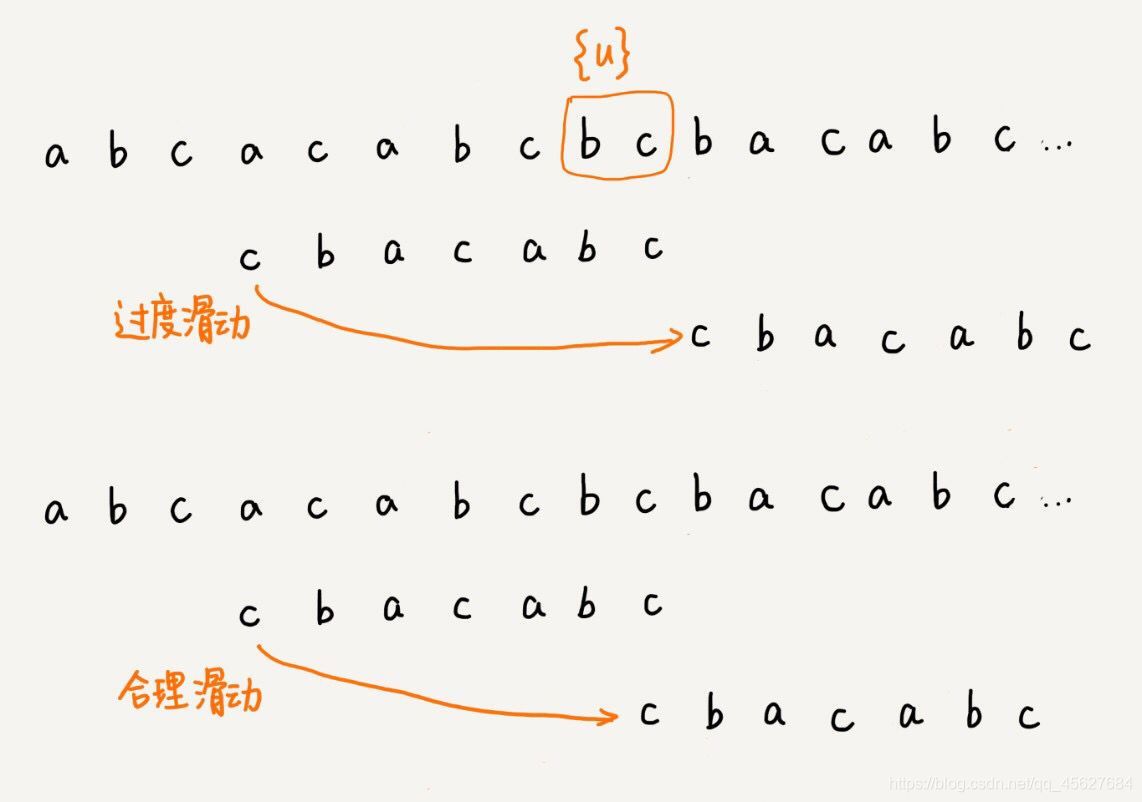
如果好后綴在模式串中不存在可匹配的子串,那在我們一步一步往后滑動模式串的程序中,只要主串中 {u} 與模式串有重合,那就肯定無法完全匹配,但是當模式串滑動到前綴與主串中的 {u} 的后綴有部分重合的時候,并且重合的部分相等的時候,就有可能會存在完全匹配的情況,
這個說起來比較復雜,大家看圖可能就明白了,
再進一步解釋就是,在上一次配比的時候,已經發現了模式串中沒有和主串好后綴可以匹配的子串,那模式串就要向后移動,這時候有個情況就是,模式串的中間的一部分和主串的好后綴重合了,那肯定是無法匹配的,因為模式串的頭尾肯定和主串的子串不匹配,所以這種情況的重合就意義不大,
但什么情況下模式串的一部分和主串的后綴有重合才有意義呢?就是模式串的前綴子串和好后綴的后綴字串重合,這樣如果后面也匹配的話,就是真的匹配了,就像我們上圖舉的合理滑動的例子,這個邏輯大家看看圖仔細想想就可以想通了,
所以,針對這種情況,我們不僅要看好后綴在模式串中,是否有另一個匹配的子串,我們還要考察好后綴的后綴子串,是否存在跟模式串的前綴子串匹配的,
為了避免歧義,這里我再解釋一下什么是前綴后綴子串,比如說有個字串 s ,它的后綴子串就是最后一個字符和 s 對齊的子串,比如 abc 的后綴子串就是 c,bc,所謂前綴子串,就是起始字符和 s 對齊的子串,比如 abc 的前綴子串就是 a,ab,
我們要從好后綴的后綴子串中,找一個最長的并且能夠跟模式串的前綴子串匹配的,假設是 {v},然后將模式串滑動到如圖所示的位置👇
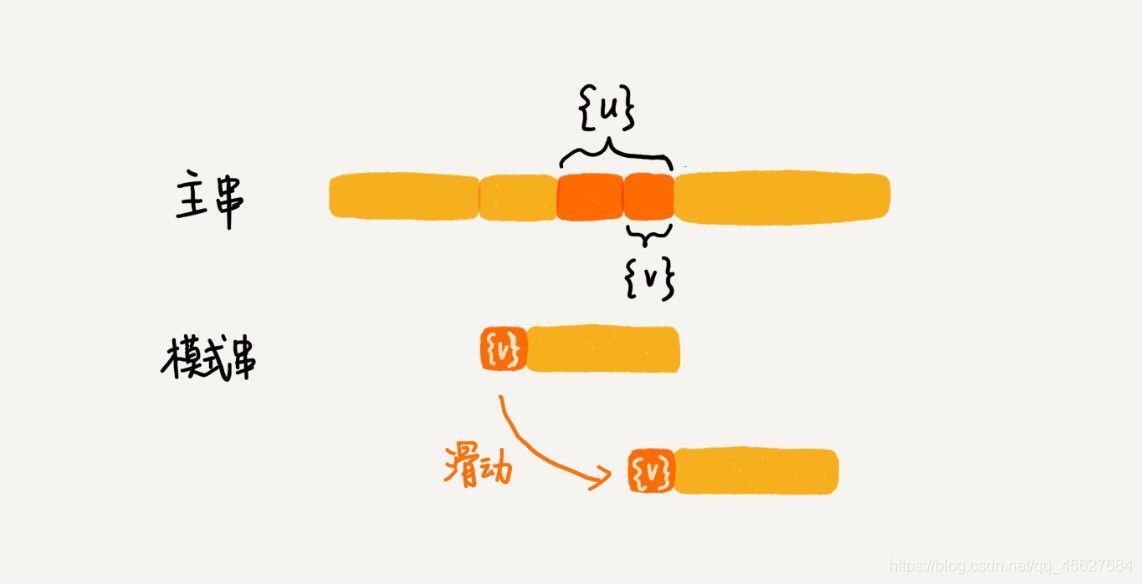
這就是好后綴規則的基本原理,
那么模式串和主串中的某個字符不匹配的時候,如何選擇用好后綴規則還是壞字符規則,來計算模式串往后滑動的位數呢?
我們前面說過,壞字符的移動位數可能會出現負數,除了這個情況意外,其他的移動都是安全的,這個安全就是指移動了以后,不會錯過正確的字串匹配,好后綴同樣,也是安全的,所以在選擇的時候,我們有一個處理原則,就是壞字符規則和好后綴規則的移動位數都進行一個計算,然后取兩個數中最大的那個,因為按照我們最基本的思路,要使得每次出現不匹配字符時模式串移動的位數更大,這樣查找起來就會更快,
因為好后綴規則不會出現移動位數是負數的情況,所以即使用壞字符規則算出來移動位數是負數,最后取得的移動位數也是正的,模式串會繼續向后移動,
Ⅳ BM 演算法代碼實作
基礎的思想和原理相信你看到這里已經明白了,現在我們就來實作 BM 演算法,
我們一部分一部分來,先來實作壞字符規則,
1. 壞字符規則
壞字符規則本身并不難理解,當遇到壞字符時,要計算往后移動的位數 si - xi,其中 xi 的計算是重點,那我們如何求得 xi ,也就是壞字符在模式串中出現的位置呢?
如果我們拿壞字符,在模式串中順序遍歷查找,這樣就會比較低效,勢必影響這個演算法的性能,為了追求更高的效率,我們可以用散串列,
對散串列有疑惑的同學可以跳轉去看我的這篇文章👇
【資料結構與演算法】->資料結構->散串列(上)->散串列的思想&散列沖突的解決
我們可以將模式串中的每個字符及其下標都存到散串列中,這樣就可以快速找到壞字符在模式串的位置下標了,
關于這個散串列,我們只實作一種最簡單的情況,假設字串的字符集不是很大,每個字符長度是 1 位元組,我們用大小為 256 的陣列,來記錄每個字符在模式串中出現的位置,陣列的下標對應字符的 ASCII 碼值,陣列中存盤這個字符在模式串中出現的位置,
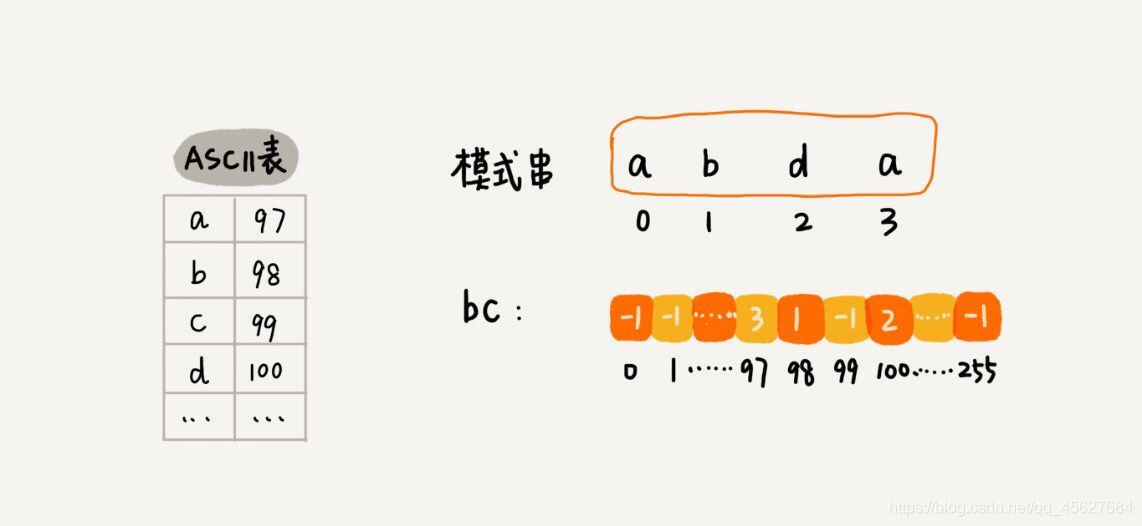
如果將上面的程序寫成代碼,就是下面這個樣子👇
private static final int SIZE = 256; //ASCII碼數
/**
* 借助散串列,存盤字符以及其在模式串中的位置
* 如果是同樣的字符出現多次,就記錄它在模式串中最后出現的位置
* @param patternString 模式串
* @param badChar 壞字符集
*/
private void generateBadChar(char[] patternString, int[] badChar) {
for (int i = 0; i < SIZE; i++) {
badChar[i] = -1; //初始化badChar陣列
}
for (int i = 0; i < patternString.length; i++) {
int ascii = (int) patternString[i];
badChar[ascii] = i; //記錄模式串中同一個字符最后出現的位置
}
}
badChar就是上面說的散串列,我們要借助它快速找到壞字符在模式串中的位置,
這里我再解釋一下第二個 for 回圈,我們遍歷模式串,然后在badChar中記錄字符出現在模式串中的下標,大家可以看到,如果是同樣一個字符第二次出現,就會把上一次記錄的位置覆寫掉,這樣最后就記錄的是這個字符在模式串中最后出現的位置,這也是為了安全性考慮,如果記錄的是前面出現的位置,那移動的位數就會很大,就會有錯過正確字串匹配的風險,大家仔細想想應該可以想明白,
掌握了壞規則之后,我們先把 BM 演算法的框架寫好,只完成壞字符規則的部分,先不考慮好后綴規則和壞字符規則 si - xi 計算得到的移動位數可能為負數的情況,代碼如下👇
/**
* BM演算法實作字串匹配
* @param mainString 主串
* @param patternString 模式串
* @return 模式串在主串中的位置
*/
public static int boyerMoore(char[] mainString, char[] patternString) {
int[] badChar = new int[SIZE];
generateBadChar(patternString, badChar); //構建壞字符哈希表
int mainLength = mainString.length;
int patternLength = patternString.length;
int i = 0;
while (i <= mainLength - patternLength) {
int j;
for (j = mainLength-1; j >= 0; j--) { //模式串從后向前匹配
if (mainString[i+j] != patternString[j]) { //壞字符對應模式串中的下標位置為 j
break;
}
}
if (j < 0) {
return i; //匹配成功,回傳下標i
}
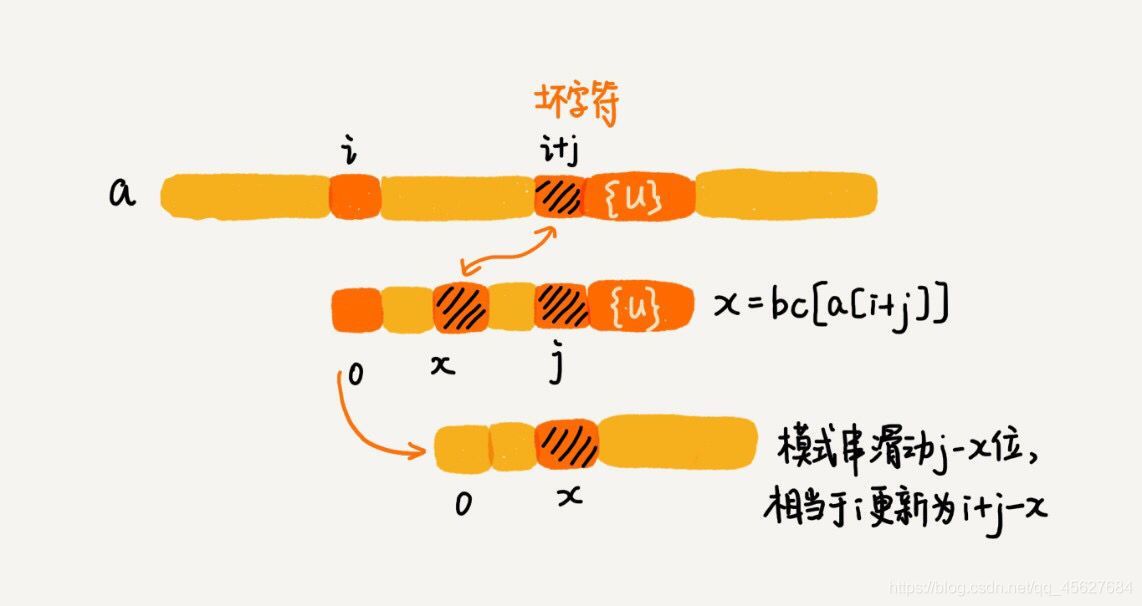
//等同于將模式串往后滑動 si-xi 也就是 (j - badChar[(int) mainString[i+j]])位
i = i + (j - badChar[(int) mainString[i+j]]);
}
return -1;
}
壞字符規則理解起來是容易點的,大家可以對著注釋看看代碼,應該就可以明白了,我再給出一張圖,方便大家理解,
至此,我們已經實作了包含壞字符規則的 BM 演算法,現在只需要再將好后綴規則填充進這個框架里,
2. 好后綴規則
根據上面的講述,我們知道好后綴的處理規則中有兩個最核心的內容:
- 在模式串中,查找跟好后綴匹配的另一個子串;
- 在好后綴的后綴子串中,查找最長的、能跟模式串前綴子串匹配的后綴子串,
我再來對這兩條做一個解釋,
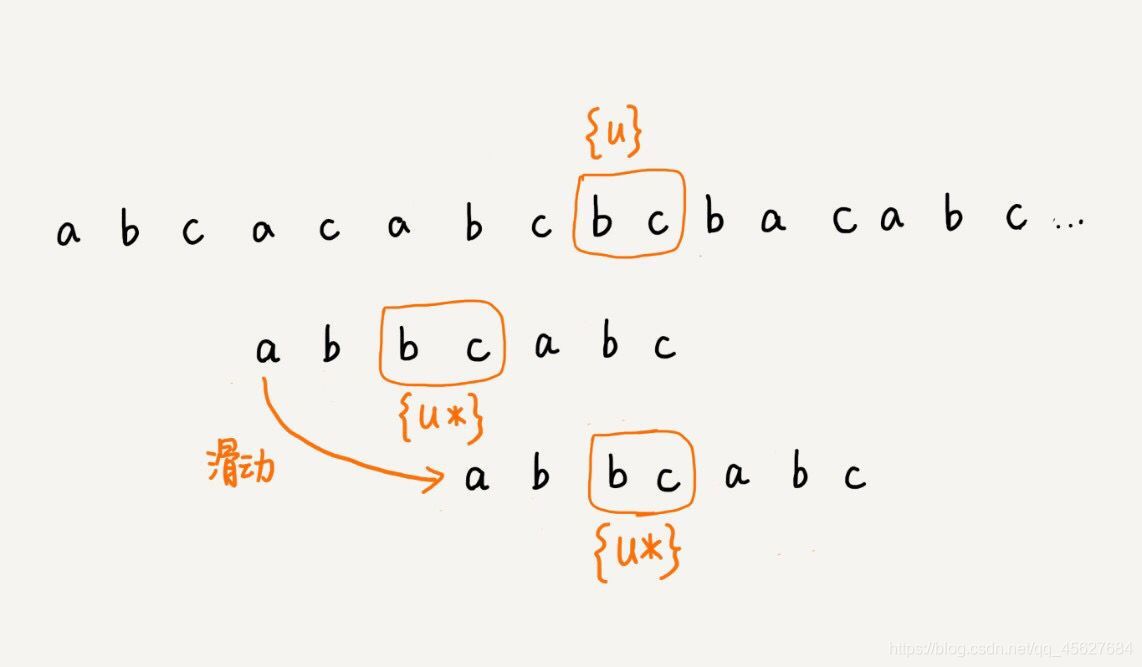
我們前面講好后綴規則的時候,說的第一種情況,就是模式串中有和好后綴可以配對的子串,這個其實很容易繞進去,我們先明確一個事情,就是好后綴意味了什么,能有好后綴,一定代表了配對的時候模式串的后綴子串和主串的一個子串重合了,就是下圖中模式串最后兩位的 b c ,
所以我們要再在模式串中找的可以和后綴子串配對的子串,是除了現在模式串中已經和主串的一個字串配對的后綴子串以外,要再找一個相同的子串,我們要找的是模式串中圈起來的這個 b c,
這就是第一條核心的意思,配合之前的圖,大家再做一個理解,
然后再來看第二條核心對應的另一種情況,就是我們要找前面的 b c ,但是模式串中已經沒有了,那怎么辦?這時候我們就找好后綴的后綴子串和模式串的前綴子串,有沒有匹配的,找到的越長,能跳躍的就越多,
在不考慮效率的情況下,這兩個操作可以用很“暴力”的匹配查找方式解決,但是,如果想要 BM 演算法的效率很高,這部分就不能太低效,那我們要如何做呢?
因為好后綴也是模式串本身的后綴子串,所以,我們可以在模式串和主串正式匹配之前,通過預處理模式串,預先計算好模式串的每個后綴子串,對應的另一個可匹配子串的位置,這個預處理程序比較有技巧,很容易繞進去,是這篇文章中最難的一部分了,
我們先來看看,如何表示模式串中不同的后綴子串呢?因為后綴子串的最后一個字符的位置的固定的,下標為 m - 1,(m 為模式串的長度),所以我們只需要記錄長度就可以了,通過長度,我們可以確定出唯一的后綴子串,
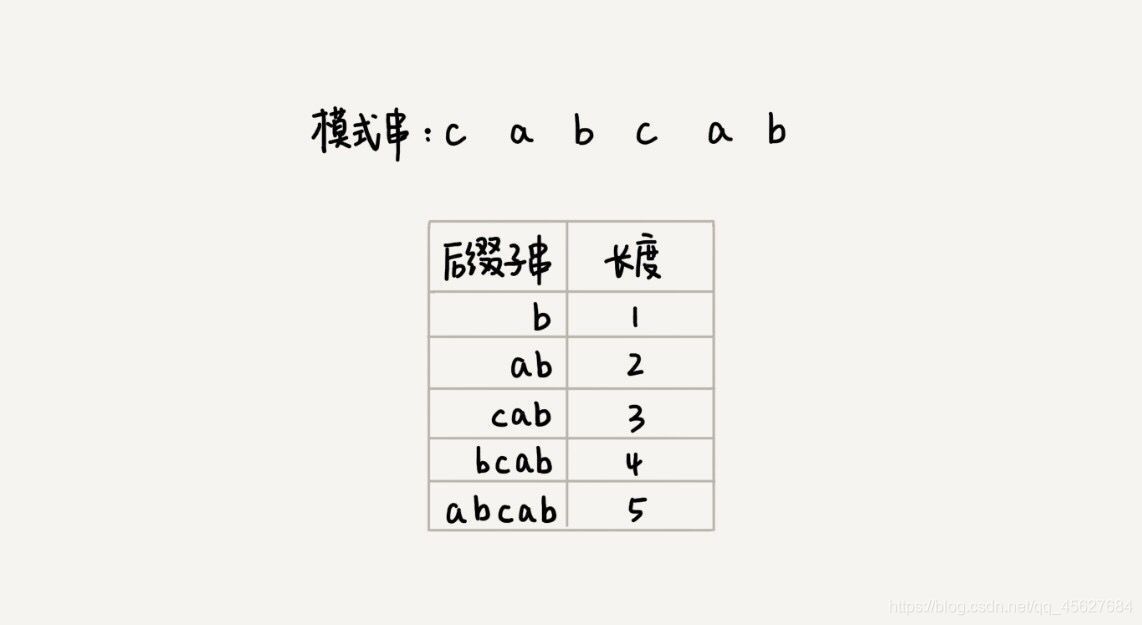
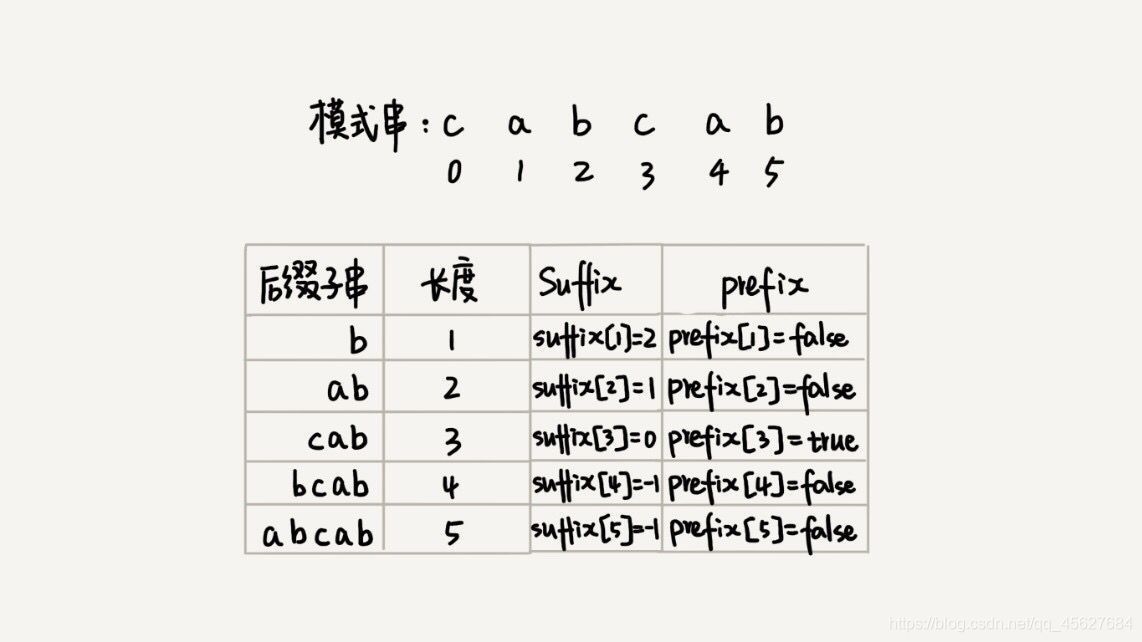
現在我們要引入最關鍵的變數 suffix 陣列 ,這個陣列是用來存放后綴子串的,suffix 陣列的下標 k 表示后綴子串的長度為 k,下標對應的陣列值存盤的是,在模式串中跟好后綴 {u} 相匹配的子串 {u*} 的起始下標值,
這就對應著我們前面說的第一個核心,我用一個例子來做個說明,
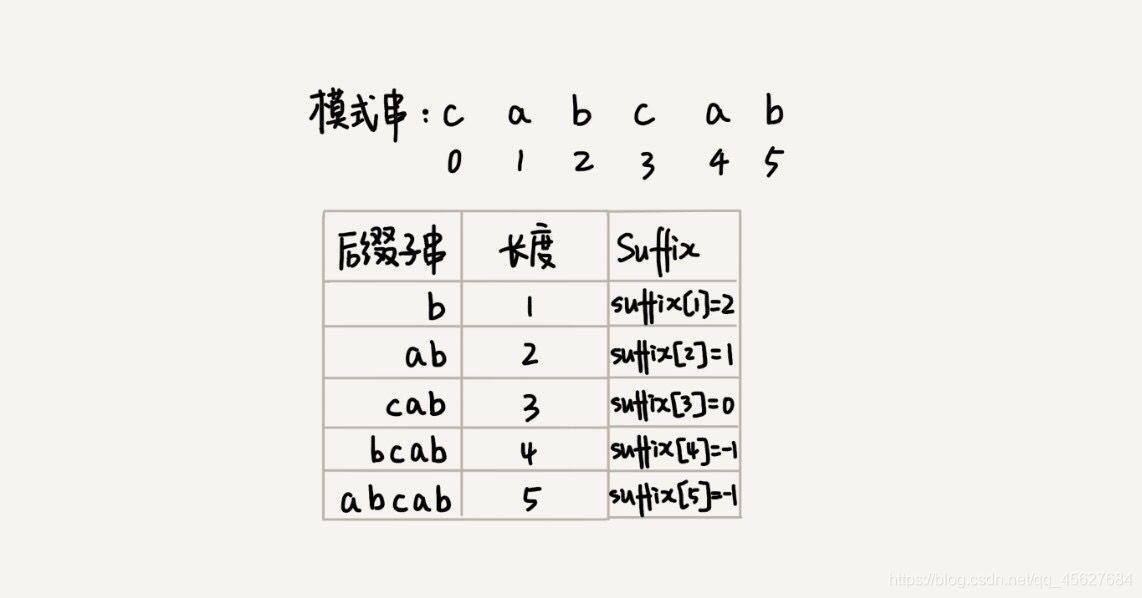
再強調一下,我們在模式串中找的是和后綴子串相配的子串,不是找模式串的后綴子串的位置,前面我們已經說過了,既然有后綴子串,就說明后幾位已經配對上了,所以找的是其他位置的子串,因為我們是要通過這個位置來往后移動,使得模式串中的這個子串走到和好后綴相對應的地方,所以上圖中的 suffix[4] 和 suffix[5] 都是 -1,因為除了已經和好后綴配對的后綴子串外,模式串里已經沒有另一個可以配對的子串了,
那么,如果模式串中有多個(大于 1 個)子串跟后綴子串 {u} 匹配,那 suffix 陣列中該存盤哪個子串的起始位置呢?為了避免模式串往后滑動得過頭了,我們肯定要存盤模式串中最靠后的那個子串的起始位置,也就是下標最大的那個子串的起始位置,這和我們的壞字符的處理是一樣的,還記得嗎?都是為了防止滑動過大,所以出現了同樣的字符或字串,都取靠后的那個,
for (int i = 0; i < patternString.length; i++) {
int ascii = (int) patternString[i];
badChar[ascii] = i; //記錄模式串中同一個字符最后出現的位置
}
如果這么說還不夠清晰的話,我再舉個例子,比如我們有一個模式串如下👇
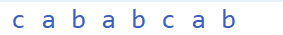
這個就比上面多了個 a b ,我還是和上面一樣做個簡單的分析
| 后綴子串 | 長度 | Suffix |
|---|---|---|
| b | 1 | suffix[1] = 4 |
| ab | 2 | suffix[2] = 3 |
| cab | 3 | suffix[3] = 0 |
那我們這樣處理就足夠了嗎?如果有多個子串和后綴子串 {u} 匹配的話,
實際上,僅僅是選最靠后的字串片段來存盤是不夠的,我們再次回憶一下好后綴規則,
我們不僅要在模式串中,查找跟好后綴匹配的另一個子串,還要在好后綴的后綴子串中,查找最長的能跟模式串前綴子串匹配的后綴子串,
其實對應的還是這張圖,我們在前面說過,如果是模式串的一個子串和好后綴重合,那一定不是匹配的,只有當模式串的前綴子串和好后綴的后綴子串重合,才有可能匹配,
我們如果只記錄剛剛定義的 suffix,實際上,只能處理規則的前半部分,也就是在模式串中,查找跟好后綴匹配的另一個子串,所以,除了 suffix 陣列之外,我們還需要一個 boolean 型別的 prefix 陣列,來記錄模式串的后綴子串是否能匹配模式串的前綴子串,
看了前面的講解,我相信你已經理解了為什么只有 prefix[3] = true,像后綴字串是 ab,這時候 ab 雖然有可以配對的子串,就是下標為 1 開始的那個 ab,但是模式串的前綴子串是 ca,和 ab 不匹配,就為 false,因而只有 prefix[3] = true ,
現在,我們就來看看如何計算并填充這兩個陣列的值,這個計算程序也非常巧妙,
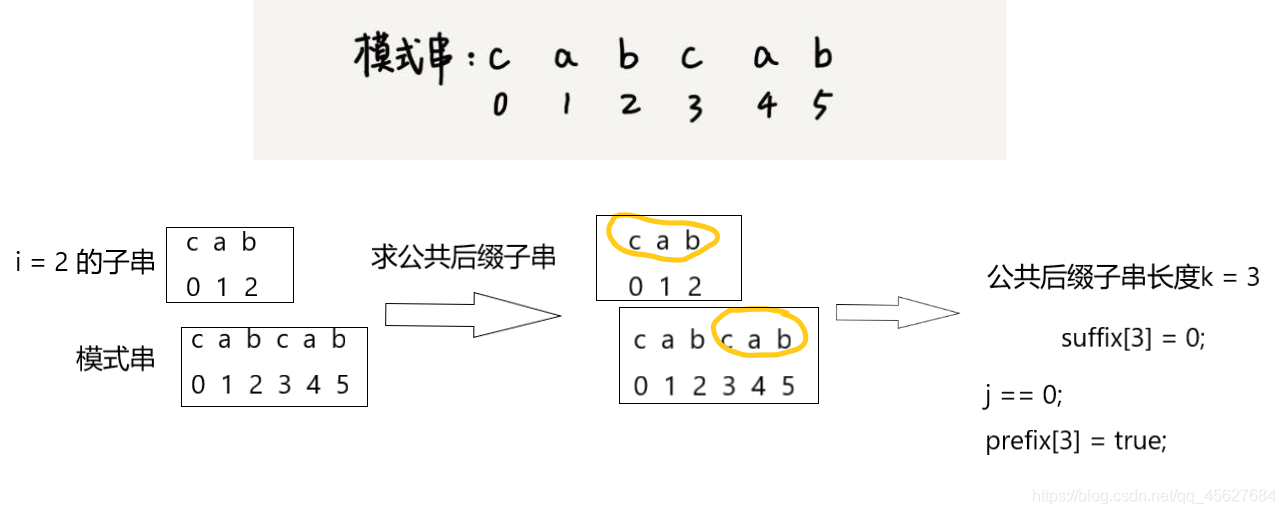
我們拿下標從 0 到 i 的子串(i 可以是 0 到 m-2)與整個模式串,求公共后綴子串,如果公共后綴子串的長度是 k,那我們就記錄 suffix[k] = j(j 表示公共后綴子串的起始下標),如果 j == 0,也就是說,公共后綴子串也是模式串的前綴子串,我們就記錄 prefix[k] = true,
這個邏輯是什么意思呢?我再進一步地講解一下,
我們現在的目的是要求能跟模式串后綴子串匹配的前綴子串,如果整個模式串的長度為 m,那么模式串的下標就是 [0, m-1],這個我相信大家都理解,那么,模式串的最大前綴子串就是 [0, m-2],所以 i 的取值范圍就是 0 到 m-2 ,
比如我們把 i = 2 時的子串拿出來,和整個模式串求公共后綴子串,這樣求出來的就和上面我們的例子中一樣,為了便于說明,我再用上面的例子畫個圖,
現在我們把 suffix 陣列和 prefix 陣列的計算程序,用代碼實作,大家可以做一個對照,
/**
* 初始化 suffix、prefix陣列
* @param patternString 模式串
* @param suffix
* @param prefix
*/
private static void generateGoodSuffix(char[] patternString,
int[] suffix, boolean[] prefix) {
int patternLength = patternString.length;
for (int i = 0; i < patternLength; i++) {
suffix[i] = -1;
prefix[i] = false;
}
for (int i = 0; i < patternLength-1; i++) { //取出一個[0, i]的子串和模式串找公共后綴子串
int j = i;
int k = 0;
while (j >= 0 && patternString[j] == patternString[patternLength-1-k]) {
j--;
k++;
suffix[k] = j + 1;
}
if (j == -1) { //表示公共后綴子串也是模式串的前綴子串
prefix[k] = true;
}
}
}
同樣的,如果大家對這段代碼覺得有些混亂的話,可以對著代碼做一遍變數跟蹤,再結合著我的決議,相信應該還是可以理解的,
有了這兩個陣列之后,我們現在來看,模式串跟主串匹配的程序中,遇到不能匹配的字符時,如何根據好后綴規則,計算模式串往后滑動的位數,
假設好后綴的長度是 k ,我們先拿好后綴,在 suffix 陣列中查找其匹配的子串,如果 suffix[k] 不等于 -1 (-1 表示不存在匹配的子串),那我們就將模式串往后移動 j - suffix[k] + 1 位 (j 表示壞字符對應的模式串中的字符下標),
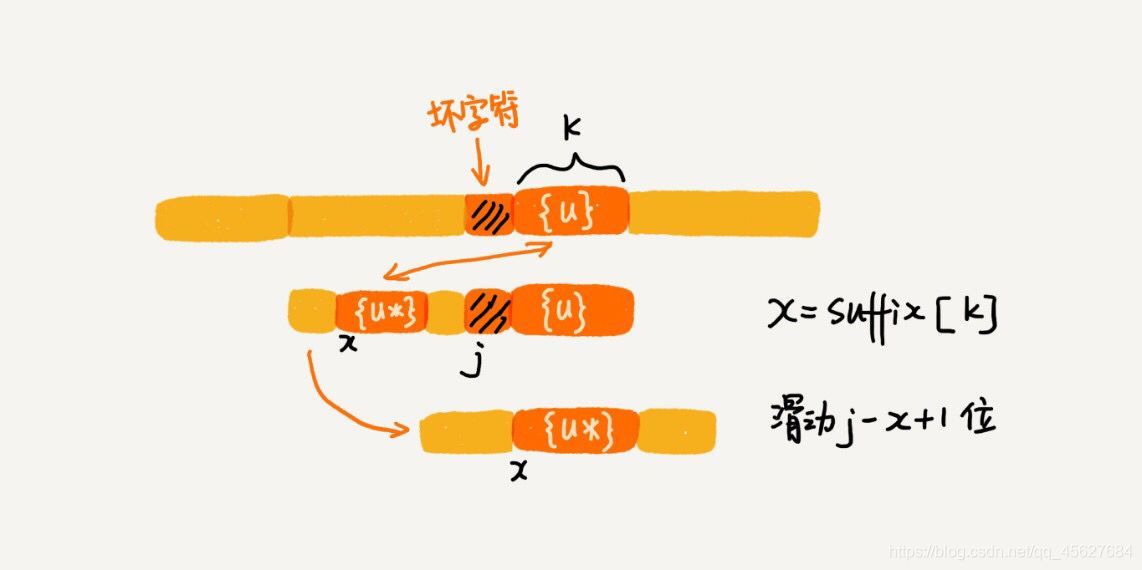
如果 suffix[k] 等于 -1,表示模式串中不存在另一個跟好后綴匹配的子串片段,我們可以用下面這條規則來處理,
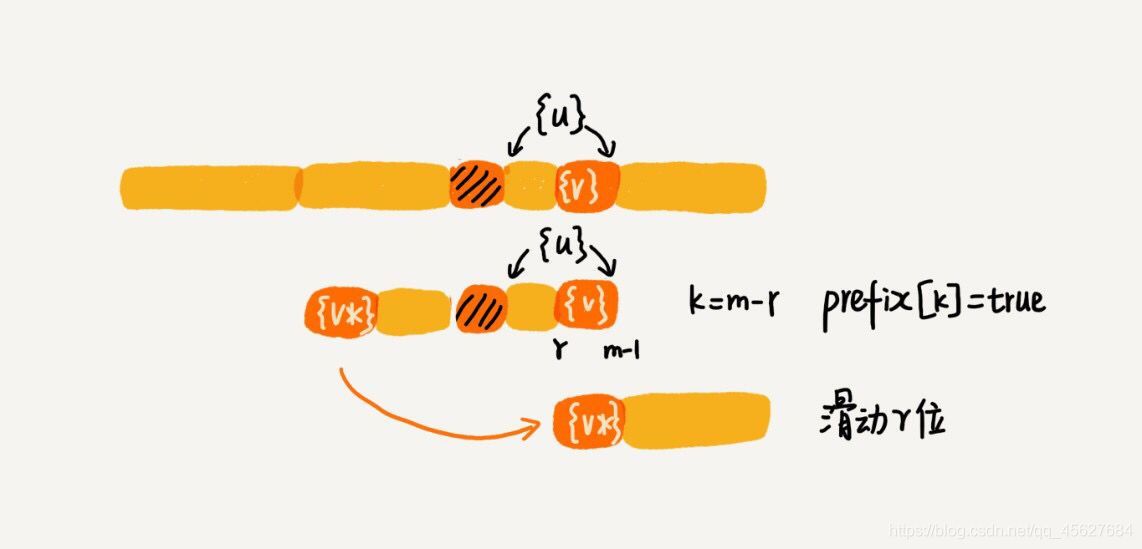
好后綴的后綴子串 b[r, m-1](其中,r 取值從 j+2 到 m-1)的長度 k = m-r,如果 prefix[k] 等于 true,表示長度為 k 的后綴子串,有可匹配的前綴子串,這樣我們可以把模式串后移 r 位,
關于 r 的取值,我這里要再多說一句,當時我學的時候覺得就很迷惑,這個取值是怎么來的,好半會都沒反應過來,在前面我們說,j 是壞字符對應的模式串中的字符下標,也就是說,在 j 的下一個字符,就是好后綴了,那我們要求好后綴的后綴子串,就要再往后走一格,因為后綴子串是包含第一個字符的,不然就不是后綴了,所以 r 的取值是從 j+2 開始的,
這個情況就對應了我們前面講的,需要找和好后綴的后綴子串配對的模式串中的最大前綴子串,我們需要將這個前綴子串后移到和好后綴的后綴子串對應的位置上,如下圖所示👇
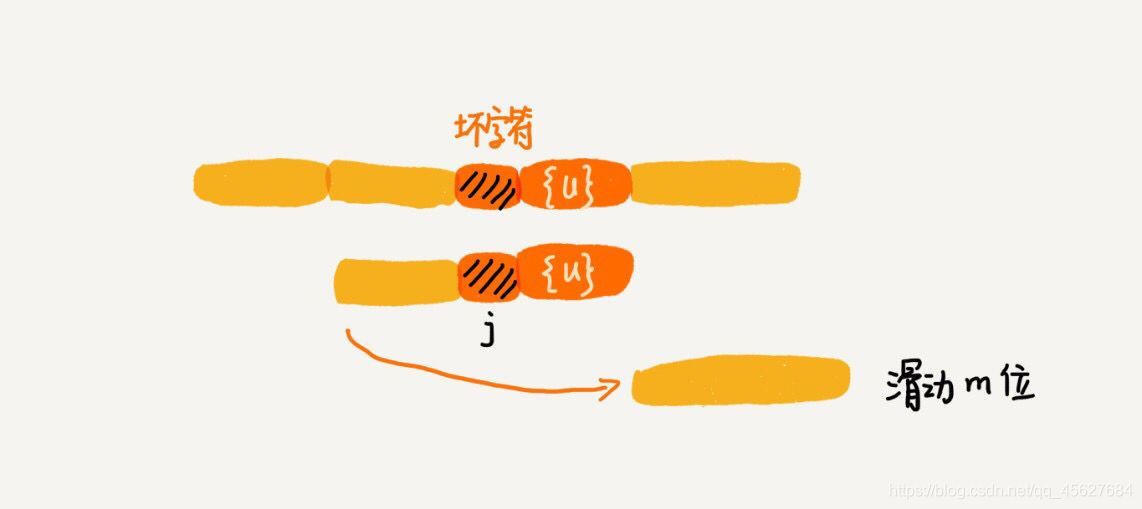
如果這兩條規則都沒有找到可以匹配好后綴或者其后綴子串的子串,就說明這是我們講的好后綴的第一種情況,可以直接向后移動整個模式串的位數,
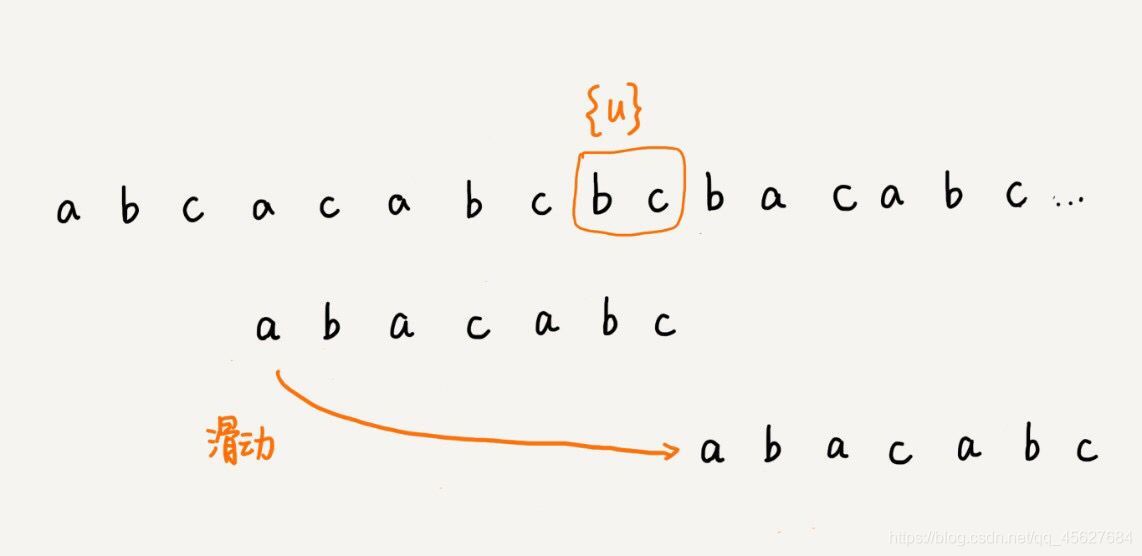
至此,好后綴規則的代碼思路我們也理清了,可以直接把好后綴規則的代碼加到前面我們寫的 BM 演算法的框架中去,這樣就得到了 BM 演算法的完整實作,
3. 代碼完整實作
package com.tyz.string_matching.core;
/**
* 用BM演算法實作字串匹配
* @author Tong
*/
public class BoyerMoore {
private static final int SIZE = 256; //ASCII碼數
public BoyerMoore() {}
/**
* 借助散串列,存盤字符以及其在模式串中的位置
* 如果是同樣的字符出現多次,就記錄它在模式串中最后出現的位置
* @param patternString 模式串
* @param badChar 壞字符集
*/
private static void generateBadChar(char[] patternString, int[] badChar) {
for (int i = 0; i < SIZE; i++) {
badChar[i] = -1; //初始化badChar陣列
}
for (int i = 0; i < patternString.length; i++) {
int ascii = (int) patternString[i];
badChar[ascii] = i; //記錄模式串中同一個字符最后出現的位置
}
}
/**
* 初始化 suffix、prefix陣列
* @param patternString 模式串
* @param suffix
* @param prefix
*/
private static void generateGoodSuffix(char[] patternString,
int[] suffix, boolean[] prefix) {
int patternLength = patternString.length;
for (int i = 0; i < patternLength; i++) {
suffix[i] = -1;
prefix[i] = false;
}
for (int i = 0; i < patternLength-1; i++) { //取出一個[0, i]的子串和模式串找公共后綴子串
int j = i;
int k = 0;
while (j >= 0 && patternString[j] == patternString[patternLength-1-k]) {
j--;
k++;
suffix[k] = j + 1;
}
if (j == -1) { //表示公共后綴子串也是模式串的前綴子串
prefix[k] = true;
}
}
}
/**
* 用好后綴規則計算模式串移動位數
* @param j 壞字符對應的模式串中的字符下標
* @param patternLength 模式串長度
* @param suffix
* @param prefix
* @return 好后綴規則計算出的移動位數
*/
private static int moveByGoodString(int j, int patternLength,
int[] suffix, boolean[] prefix) {
int k = patternLength - 1 - j; //好后綴長度
if (suffix[k] != -1) {
return j - suffix[k] + 1; //模式串里有和好后綴相配的子串
}
for (int r = j+2; r <= patternLength-1; r++) {
if (prefix[patternLength-r] == true) {
return r; //模式串有可以和好后綴的后綴子串相配的前綴子串
}
}
return patternLength; //模式串里只有后綴子串和好后綴相配
}
/**
* BM演算法實作字串匹配
* @param mainString 主串
* @param patternString 模式串
* @return 模式串在主串中的位置
*/
public static int boyerMoore(char[] mainString, char[] patternString) {
int[] badChar = new int[SIZE];
generateBadChar(patternString, badChar); //構建壞字符哈希表
int mainLength = mainString.length;
int patternLength = patternString.length;
int[] suffix = new int[patternLength];
boolean[] prefix = new boolean[patternLength];
generateGoodSuffix(patternString, suffix, prefix);
int i = 0;
while (i <= mainLength - patternLength) {
int j;
for (j = patternLength-1; j >= 0; j--) { //模式串從后向前匹配
if (mainString[i+j] != patternString[j]) { //壞字符對應模式串中的下標位置為 j
break;
}
}
if (j < 0) {
return i; //匹配成功,回傳下標i
}
int x = j - badChar[(int) mainString[i+j]];
int y = 0;
if (j < patternLength-1) { //壞字符不在最后一位,說明存在好后綴
y = moveByGoodString(j, patternLength, suffix, prefix);
}
//將模式串向后移動好后綴規則和壞字符規則計算出的移動位數最大的那個
i = i + Math.max(x, y);
}
return -1;
}
}
我覺得我的注釋已經寫得很詳細了,大家可以結合我的注釋以及前面的講解,來理解這里的代碼,
Ⅴ BM 演算法的性能分析及優化
我們先來分析 BM 演算法的記憶體消耗,整個演算法用到了額外的三個陣列,其中 badChar陣列的大小跟字符集大小有關,suffix陣列和 prefix陣列的大小跟模式串長度 m 有關,
如果我們處理字符集很大的字串匹配問題,badChar陣列對記憶體的消耗會比較多,因為好后綴和壞字符規則是獨立的,如果我們對運行的環境對記憶體要求嚴苛,可以只是用好后綴規則,不使用壞字符規則,這樣就可以避免 badChar陣列過多的記憶體消耗,不過,單純地使用好后綴規則,BM 演算法的效率就會下降一些了,
實際上,我們講的這個 BM 演算法是個初級版本,基于這個初級的版本,在極端情況下,預處理計算 suffix 陣列、prefix 陣列的性能會比較差,
比如模式串是 aaaaaaa 這種包含很多重復的字符的模式串,預處理的時間復雜度就是 O(m2),當然,大部分情況下,時間復雜度不會這么差,
BM 演算法的時間復雜度分析起來非常復雜,這篇論文 “A new proof of the linearity of the Boyer-Moore string searching algorithm” 證明了在最壞情況下,BM 演算法的比較次數上限是 5n,這篇論文“Tight bounds on the complexity of the Boyer-Moore string matching algorithm” 證明了在最壞情況下,BM 演算法的比較次數上限是 3n,
若對 KMP 演算法有興趣的同學,可以繼續看我的下一篇文章👇
【資料結構與演算法】->演算法->字串匹配基礎(下)->KMP 演算法
另,這篇文章的主要內容來源于極客時間王爭的《資料結構與演算法之美》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/46093.html
標籤:其他
上一篇:What Does BERT Look At? An Analysis of BERT’s Attention 論文總結