我有一個由多個類別和月份組成的資料框。每行都是參與者的 1 次互動,所以我想通過熱圖按月份和不同類別顯示他們全年的互動次數。總共 490 萬行,這意味著全年共有 490 萬次互動。
我嘗試使用輸入來指示列名并嘗試被動更改 X 軸,但它似乎不起作用。
library(shiny)
library (igraph)
library (tidygraph)
library (ggraph)
library (plotly)
interaction <- readRDS("participant_interaction.rds")
# Define UI for application that draws a histogram
ui <- fluidPage(
# Application title
titlePanel("Social Network Interaction"),
# Sidebar with a slider input for number of bins
sidebarLayout(
sidebarPanel(
helpText(" Visualise the Social Network Interaction of the Population
in Ohio"),
selectInput(inputId = "Category",
label = "Choose a Category",
choices = c( "Household Size" = "Household_Size",
"Have Kids" = "Have_Kids",
"Education Level" = "Education_Level",
"Interest Group" = "Interest_Group",
"Age Group" = "Age_Group"
),
selected = "Household_Size")
),
# Show a plot of the generated distribution
mainPanel(
plotOutput("heatmapPlot")
)
)
)
server <- function(input, output, session) {
dataset <- reactive({
interaction %>%
group_by(Month,input$Category)%>%
summarise(InteractionCount = n()) %>%
ungroup
})
output$heatmapPlot <- renderPlot({
ggplot(dataset(),aes(x= input$Category,y = Month,fill = InteractionCount))
geom_tile()
})
}
# Run the application
shinyApp(ui = ui, server = server)
期望的輸出:
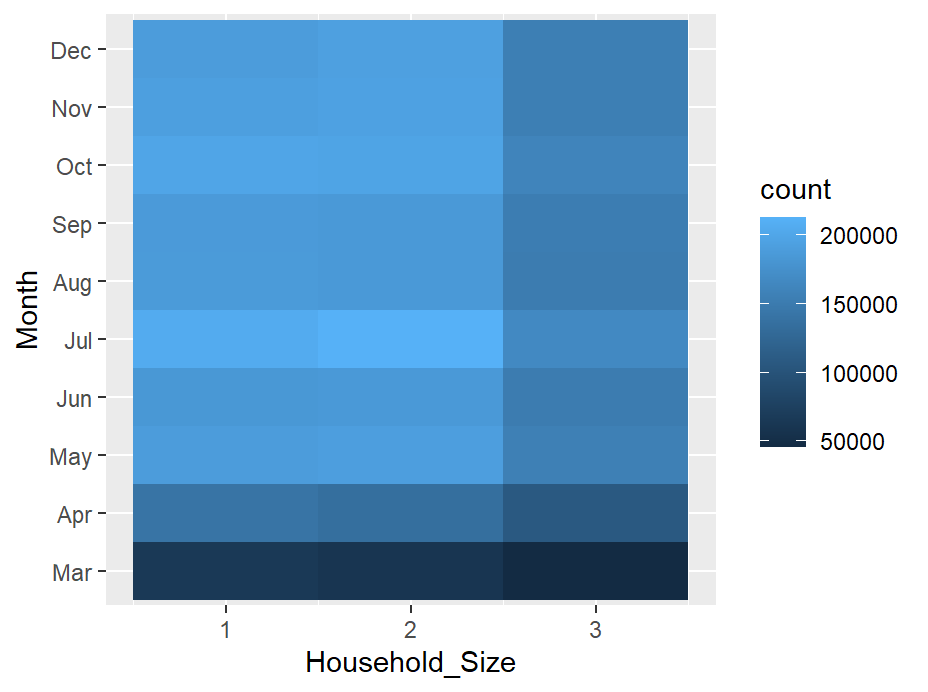
電流輸出:
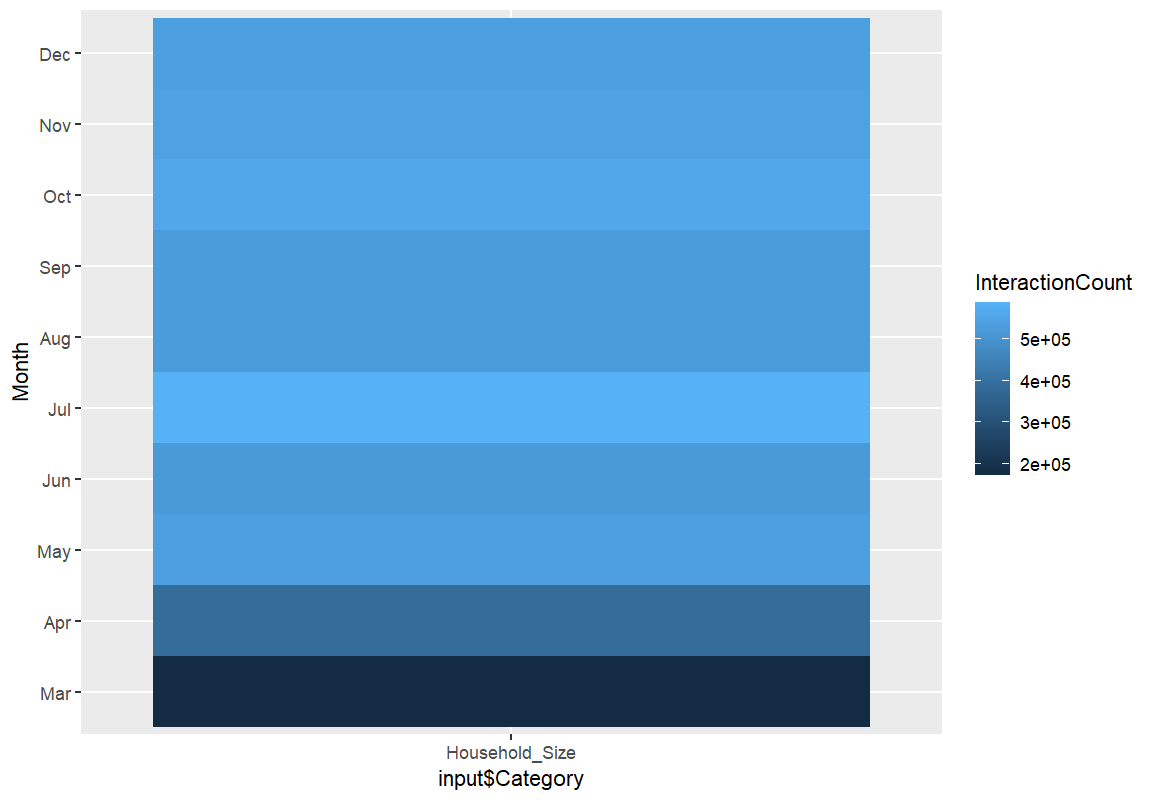
我的 RDS 檔案的隨機 20(dput):
structure(list(Participant_ID = c(374, 167, 899, 299, 443, 889,
997, 521, 953, 436, 218, 422, 4, 227, 126, 12, 57, 386, 255,
307), Month = structure(c(7L, 8L, 9L, 9L, 6L, 10L, 11L, 7L, 4L,
6L, 10L, 11L, 8L, 12L, 7L, 8L, 7L, 11L, 7L, 10L), .Label = c("Jan",
"Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct",
"Nov", "Dec"), class = c("ordered", "factor")), Income = c(37891.66,
50156.67, 59877.49, 56393.02, 27899.58, 61258.05, 60728.21, 44858.08,
36665.14, 27970.52, 27803.1, 63058.55, 135076.17, 46147.7, 30712.52,
93774.11, 168620.22, 82925.21, 29451.88, 40328.79), Expenses = c(-26931.38,
-32313.29, -25363.68, -23341.46, -24747.06, -18336.36, -17067.74,
-22054.58, -23258.78, -22504.3, -23833.48, -17322.96, -28322.98,
-16633.05, -23661.04, -21135.57, -20642.13, -23707.51, -26028.96,
-30125.43), Household_Size = c(2, 2, 2, 3, 1, 2, 1, 3, 1, 1,
1, 1, 3, 1, 2, 3, 3, 2, 3, 3), Have_Kids = c(FALSE, FALSE, FALSE,
TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE,
TRUE, FALSE, FALSE, TRUE, TRUE, FALSE, TRUE, TRUE), Age = c(57,
49, 59, 35, 56, 19, 48, 39, 45, 36, 38, 27, 43, 59, 26, 34, 56,
39, 59, 38), Education_Level = c("High School or College", "High School or College",
"Graduate", "High School or College", "High School or College",
"Bachelors", "Graduate", "High School or College", "Graduate",
"High School or College", "High School or College", "Graduate",
"Bachelors", "High School or College", "High School or College",
"High School or College", "Graduate", "Graduate", "High School or College",
"Graduate"), Interest_Group = c("F", "F", "B", "I", "F", "A",
"I", "I", "G", "J", "B", "D", "H", "H", "A", "D", "A", "H", "H",
"H"), Joviality = c(0.85417223, 0.846680285, 0.544405537, 0.5149016,
0.758121962, 0.126644557, 0.128853966, 0.477456741, 0.846871205,
0.949412047, 0.971074532, 0.647441392, 0.857396691, 0.490213553,
0.72895287, 0.241615182, 0.422849796, 0.479804894, 0.852187763,
0.962210067), Age_Group = structure(c(9L, 7L, 9L, 4L, 9L, 1L,
7L, 5L, 6L, 5L, 5L, 3L, 6L, 9L, 3L, 4L, 9L, 5L, 9L, 5L), .Label = c("20 & Below",
"21-25", "26-30", "31-35", "36-40", "41-45", "46-50", "51-55",
"56-60"), class = "factor")), row.names = c(1970773L, 932225L,
4348108L, 1549925L, 2381951L, 4296595L, 4822673L, 2808545L, 4594431L,
2337980L, 1146486L, 2241290L, 16905L, 1187579L, 697338L, 71056L,
302316L, 2012670L, 1319716L, 1594018L), class = "data.frame")
uj5u.com熱心網友回復:
input$Category是一個字串,但是dplyr動詞和aes期望是一個符號。有一些較舊的答案推薦aes_string或手動將字串轉換為符號。
但是,現在推薦的選項是使用.data代詞,請參閱dplyr檔案和掌握閃亮的書。
在您的情況下,它將是:
group_by(Month, .data[[input$Category]])
和
aes(x = .data[[input$Category]], y = Month, fill = InteractionCount)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/493124.html
上一篇:R:如何在情節中修改圖例?