在此示例資料中:
data = [{'source': ' Off-grid energy'},
{'source': 'off-grid generation'},
{'source': 'Off grid energy '},
{'source': 'OFFGRID energy'},
{'source': 'apple sauce'},
{'source': 'green energy'},
{'source': 'Green electricity '},
{'source': 'tomato sauce'},
{'source': 'BIOMASS as an energy source'},
{'source': 'produced heat (biogas).'}]
我想根據條件創建一個新列:
my_conditions = {
"green": df["source"].str.contains("green"),
"bio-gen": df["source"].str.contains("bio"),
"off-grid": df["source"].str.contains("off-grid")
}
我通過小寫 df["source"] 進行預處理:
df['source'] = df["source"].str.lower()
然后使用 Numpy 的選擇:
df['category-lower'] = np.select(my_conditions.values(),\
my_conditions.keys(),\
default="other")
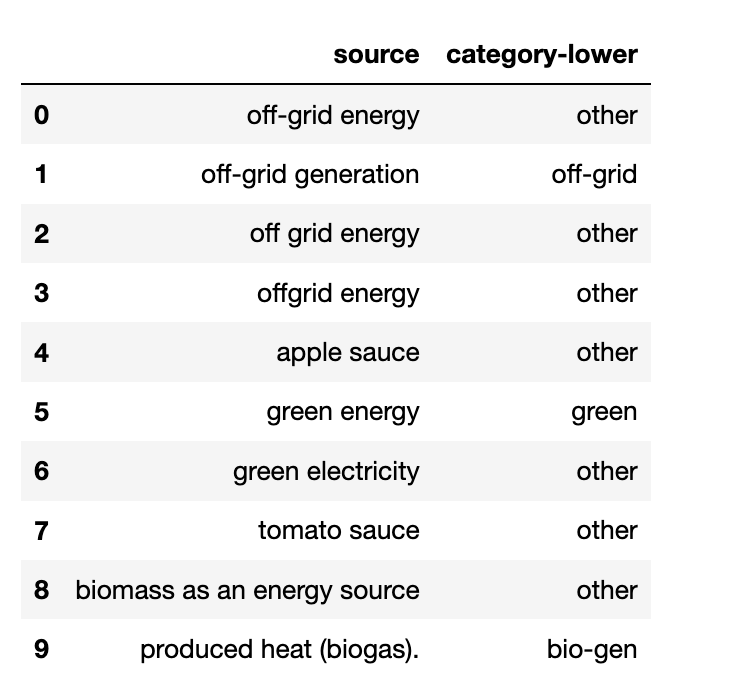
我不知道為什么無法識別小寫字母(參見第 0、6、8 行)
uj5u.com熱心網友回復:
您可能已經在構建.str.lower()后申請了my_condition。請嘗試:
import re
# apply .str.lower() here, or use flags=re.I (ignorecase in .str.contains)
# df['source'] = df["source"].str.lower()
my_conditions = {
"green": df["source"].str.contains("green", flags=re.I),
"bio-gen": df["source"].str.contains("bio", flags=re.I),
"off-grid": df["source"].str.contains("off-grid", flags=re.I),
}
df["category-lower"] = np.select(
my_conditions.values(), my_conditions.keys(), default="other"
)
print(df)
印刷:
source category-lower
0 Off-grid energy off-grid
1 off-grid generation off-grid
2 Off grid energy other
3 OFFGRID energy other
4 apple sauce other
5 green energy green
6 Green electricity green
7 tomato sauce other
8 BIOMASS as an energy source bio-gen
9 produced heat (biogas). bio-gen
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/511852.html
標籤:熊猫麻木的字典多重条件
上一篇:用另一個獲取引數重寫查詢字串