資料集是這樣的(原來會有重復的行):
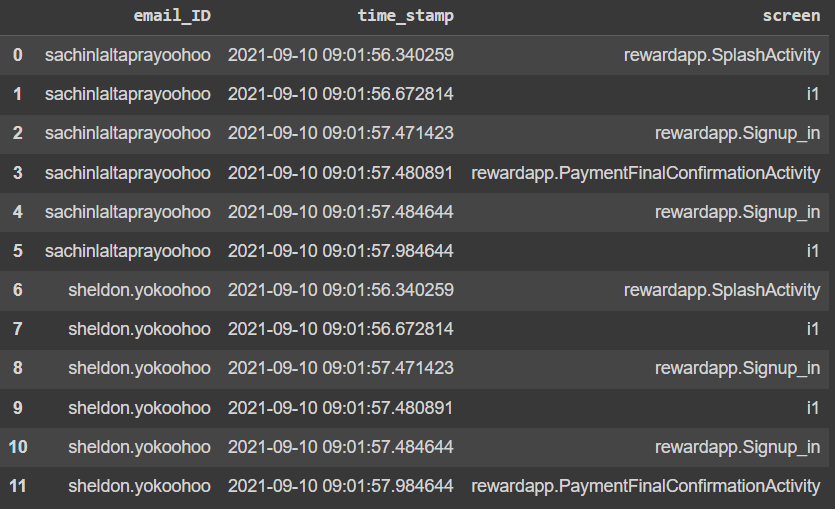
代碼:
import pandas as pd
df_in = pd.DataFrame({'email_ID': {0: 'sachinlaltaprayoohoo',
1: 'sachinlaltaprayoohoo',
2: 'sachinlaltaprayoohoo',
3: 'sachinlaltaprayoohoo',
4: 'sachinlaltaprayoohoo',
5: 'sachinlaltaprayoohoo',
6: 'sheldon.yokoohoo',
7: 'sheldon.yokoohoo',
8: 'sheldon.yokoohoo',
9: 'sheldon.yokoohoo',
10: 'sheldon.yokoohoo',
11: 'sheldon.yokoohoo'},
'time_stamp': {0: '2021-09-10 09:01:56.340259',
1: '2021-09-10 09:01:56.672814',
2: '2021-09-10 09:01:57.471423',
3: '2021-09-10 09:01:57.480891',
4: '2021-09-10 09:01:57.484644',
5: '2021-09-10 09:01:57.984644',
6: '2021-09-10 09:01:56.340259',
7: '2021-09-10 09:01:56.672814',
8: '2021-09-10 09:01:57.471423',
9: '2021-09-10 09:01:57.480891',
10: '2021-09-10 09:01:57.484644',
11: '2021-09-10 09:01:57.984644'},
'screen': {0: 'rewardapp.SplashActivity',
1: 'i1',
2: 'rewardapp.Signup_in',
3: 'rewardapp.PaymentFinalConfirmationActivity',
4: 'rewardapp.Signup_in',
5: 'i1',
6: 'rewardapp.SplashActivity',
7: 'i1',
8: 'rewardapp.Signup_in',
9: 'i1',
10: 'rewardapp.Signup_in',
11: 'rewardapp.PaymentFinalConfirmationActivity'}})
df_in['time_stamp'] = df_in['time_stamp'].astype('datetime64[ns]')
df_in
輸出應該是這樣的:
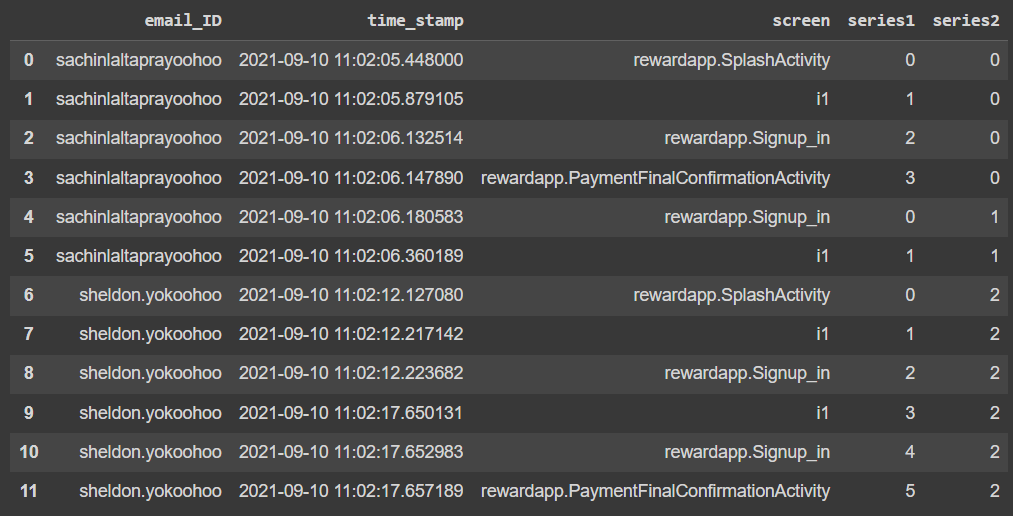
代碼:
import pandas as pd
df_out = pd.DataFrame({'email_ID': {0: 'sachinlaltaprayoohoo',
1: 'sachinlaltaprayoohoo',
2: 'sachinlaltaprayoohoo',
3: 'sachinlaltaprayoohoo',
4: 'sachinlaltaprayoohoo',
5: 'sachinlaltaprayoohoo',
6: 'sheldon.yokoohoo',
7: 'sheldon.yokoohoo',
8: 'sheldon.yokoohoo',
9: 'sheldon.yokoohoo',
10: 'sheldon.yokoohoo',
11: 'sheldon.yokoohoo'},
'time_stamp': {0: '2021-09-10 09:01:56.340259',
1: '2021-09-10 09:01:56.672814',
2: '2021-09-10 09:01:57.471423',
3: '2021-09-10 09:01:57.480891',
4: '2021-09-10 09:01:57.484644',
5: '2021-09-10 09:01:57.984644',
6: '2021-09-10 09:01:56.340259',
7: '2021-09-10 09:01:56.672814',
8: '2021-09-10 09:01:57.471423',
9: '2021-09-10 09:01:57.480891',
10: '2021-09-10 09:01:57.484644',
11: '2021-09-10 09:01:57.984644'},
'screen': {0: 'rewardapp.SplashActivity',
1: 'i1',
2: 'rewardapp.Signup_in',
3: 'rewardapp.PaymentFinalConfirmationActivity',
4: 'rewardapp.Signup_in',
5: 'i1',
6: 'rewardapp.SplashActivity',
7: 'i1',
8: 'rewardapp.Signup_in',
9: 'i1',
10: 'rewardapp.Signup_in',
11: 'rewardapp.PaymentFinalConfirmationActivity'},
'series1': {0: 0,
1: 1,
2: 2,
3: 3,
4: 0,
5: 1,
6: 0,
7: 1,
8: 2,
9: 3,
10: 4,
11: 5},
'series2': {0: 0,
1: 0,
2: 0,
3: 0,
4: 1,
5: 1,
6: 2,
7: 2,
8: 2,
9: 2,
10: 2,
11: 2}})
df_out['time_stamp'] = df['time_stamp'].astype('datetime64[ns]')
df_out
'series1' 列值以 0、1、2 等逐行開始,但在以下情況下重置為 0:
- “email_ID”列值更改。
- 'screen' 列值 == 'rewardapp.PaymentFinalConfirmationActivity'
'series2' 列值從 0 開始,每當 'series1' 重置時遞增 1。
我的進步:
series1 = [0]
x = 0
for index in df[1:].index:
if ((df._get_value(index - 1, 'email_ID')) == df._get_value(index, 'email_ID')) and (df._get_value(index - 1, 'screen') != 'rewardapp.PaymentFinalConfirmationActivity'):
x = 1
series1.append(x)
else:
x = 0
series1.append(x)
df['series1'] = series1
df
series2 = [0]
x = 0
for index in df[1:].index:
if df._get_value(index, 'series1') - df._get_value(index - 1, 'series1') == 1:
series2.append(x)
else:
x = 1
series2.append(x)
df['series2'] = series2
df
我認為上面的代碼是有效的,我會在幾個小時內測驗回答的代碼并選擇最好的,謝謝。
uj5u.com熱心網友回復:
我們試試看
m = (df_in['email_ID'].ne(df_in['email_ID'].shift().bfill()) |
df_in['screen'].shift().eq('rewardapp.PaymentFinalConfirmationActivity'))
df_in['series1'] = df_in.groupby(m.cumsum()).cumcount()
df_in['series2'] = m.cumsum()
print(df_in)
email_ID time_stamp screen series1 series2
0 sachinlaltaprayoohoo 2021-09-10 09:01:56.340259 rewardapp.SplashActivity 0 0
1 sachinlaltaprayoohoo 2021-09-10 09:01:56.672814 i1 1 0
2 sachinlaltaprayoohoo 2021-09-10 09:01:57.471423 rewardapp.Signup_in 2 0
3 sachinlaltaprayoohoo 2021-09-10 09:01:57.480891 rewardapp.PaymentFinalConfirmationActivity 3 0
4 sachinlaltaprayoohoo 2021-09-10 09:01:57.484644 rewardapp.Signup_in 0 1
5 sachinlaltaprayoohoo 2021-09-10 09:01:57.984644 i1 1 1
6 sheldon.yokoohoo 2021-09-10 09:01:56.340259 rewardapp.SplashActivity 0 2
7 sheldon.yokoohoo 2021-09-10 09:01:56.672814 i1 1 2
8 sheldon.yokoohoo 2021-09-10 09:01:57.471423 rewardapp.Signup_in 2 2
9 sheldon.yokoohoo 2021-09-10 09:01:57.480891 i1 3 2
10 sheldon.yokoohoo 2021-09-10 09:01:57.484644 rewardapp.Signup_in 4 2
11 sheldon.yokoohoo 2021-09-10 09:01:57.984644 rewardapp.PaymentFinalConfirmationActivity 5 2
uj5u.com熱心網友回復:
您可以使用:
m = df_in['screen']=='rewardapp.PaymentFinalConfirmationActivity'
df_in['pf'] = np.where(m, 1, np.nan)
df_in.loc[m, 'pf'] = df_in[m].cumsum()
grouper = df_in.groupby('email_ID')['pf'].bfill()
df_in['series1'] = df_in.groupby(grouper).cumcount()
df_in['series2'] = df_in.groupby(grouper.fillna(0), sort=False).ngroup()
df_in.drop('pf', axis=1, inplace=True)
列印(df_in):
email_ID time_stamp \
0 sachinlaltaprayoohoo 2021-09-10 09:01:56.340259
1 sachinlaltaprayoohoo 2021-09-10 09:01:56.672814
2 sachinlaltaprayoohoo 2021-09-10 09:01:57.471423
3 sachinlaltaprayoohoo 2021-09-10 09:01:57.480891
4 sachinlaltaprayoohoo 2021-09-10 09:01:57.484644
5 sachinlaltaprayoohoo 2021-09-10 09:01:57.984644
6 sheldon.yokoohoo 2021-09-10 09:01:56.340259
7 sheldon.yokoohoo 2021-09-10 09:01:56.672814
8 sheldon.yokoohoo 2021-09-10 09:01:57.471423
9 sheldon.yokoohoo 2021-09-10 09:01:57.480891
10 sheldon.yokoohoo 2021-09-10 09:01:57.484644
11 sheldon.yokoohoo 2021-09-10 09:01:57.984644
screen series1 series2
0 rewardapp.SplashActivity 0 0
1 i1 1 0
2 rewardapp.Signup_in 2 0
3 rewardapp.PaymentFinalConfirmationActivity 3 0
4 rewardapp.Signup_in 0 1
5 i1 1 1
6 rewardapp.SplashActivity 0 2
7 i1 1 2
8 rewardapp.Signup_in 2 2
9 i1 3 2
10 rewardapp.Signup_in 4 2
11 rewardapp.PaymentFinalConfirmationActivity 5 2
解釋:
- 首先找到 'screen' 為 'PaymentFinalConfirmationActivity' 的行,然后使用它
cumsum()來識別它們的編號。這是通過以下方式完成的:
df_in['pf'] = np.where(m, 1, np.nan)
df_in.loc[m, 'pf'] = df_in[m].cumsum()
- 然后使用
bfill“螢屏”顯示“PaymentFinalConfirmationActivity”的位置回填 NaN 值。這將確保上述行屬于同一組,但按 email_ID 執行。這是通過以下方式完成的:
grouper = df_in.groupby('email_ID')['pf'].bfill()
- 然后很容易看到,一旦定義了 grouper,就可以使用
cumcount來獲取series1列。這是通過以下方式完成的:
df_in['series1'] = df_in.groupby(grouper).cumcount()
- 然后
series2通過使用獲取列ngroup()。但請確保 groupby 已完成sort=False。完成:
df_in['series2'] = df_in.groupby(grouper.fillna(0), sort=False).ngroup()
- 最后洗掉不需要的列
pf。
df_in.drop('pf', axis=1, inplace=True)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/511876.html
上一篇:scipy.cumtrapz和np.trapz給出不同的答案
下一篇:Pandas-計算均值和方差