這是資料框,原始有一百萬行,因此解決方案需要高效:
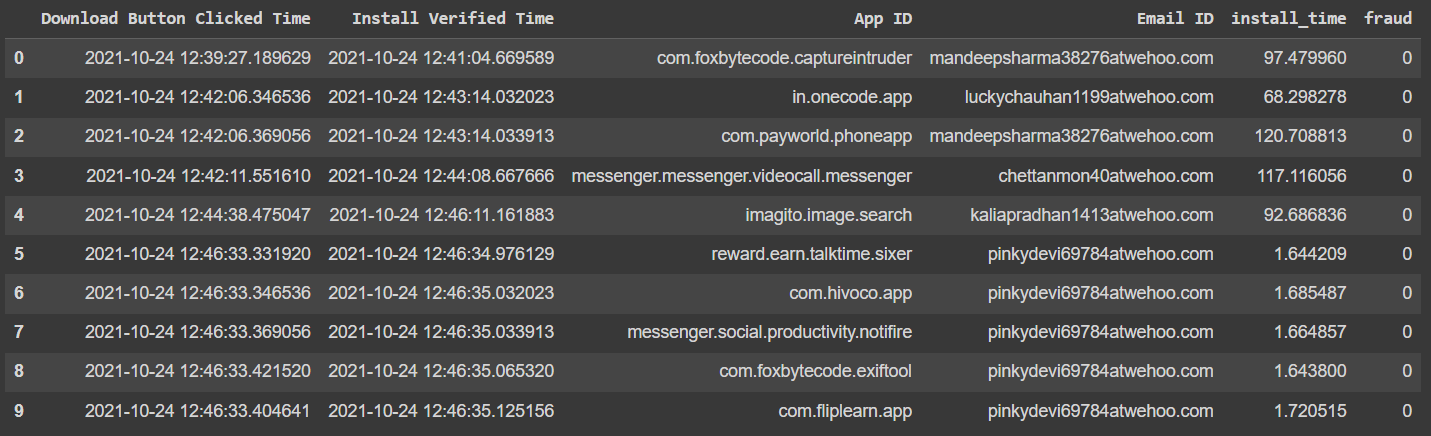
代碼:
import pandas as pd
df_temp = pd.DataFrame({'Download Button Clicked Time': {0: '2021-10-24 12:39:27.189629',
1: '2021-10-24 12:42:06.346536',
2: '2021-10-24 12:42:06.369056',
3: '2021-10-24 12:42:11.551610',
4: '2021-10-24 12:44:38.475047',
5: '2021-10-24 12:46:33.331920',
6: '2021-10-24 12:46:33.346536',
7: '2021-10-24 12:46:33.369056',
8: '2021-10-24 12:46:33.421520',
9: '2021-10-24 12:46:33.404641'},
'Install Verified Time': {0: '2021-10-24 12:41:04.669589',
1: '2021-10-24 12:43:14.032023',
2: '2021-10-24 12:43:14.033913',
3: '2021-10-24 12:44:08.667666',
4: '2021-10-24 12:46:11.161883',
5: '2021-10-24 12:46:34.976129',
6: '2021-10-24 12:46:35.032023',
7: '2021-10-24 12:46:35.033913',
8: '2021-10-24 12:46:35.065320',
9: '2021-10-24 12:46:35.125156'},
'App ID': {0: 'com.foxbytecode.captureintruder',
1: 'in.onecode.app',
2: 'com.payworld.phoneapp',
3: 'messenger.messenger.videocall.messenger',
4: 'imagito.image.search',
5: 'reward.earn.talktime.sixer',
6: 'com.hivoco.app',
7: 'messenger.social.productivity.notifire',
8: 'com.foxbytecode.exiftool',
9: 'com.fliplearn.app'},
'Email ID': {0: 'mandeepsharma38276atwehoo.com',
1: 'luckychauhan1199atwehoo.com',
2: 'mandeepsharma38276atwehoo.com',
3: 'chettanmon40atwehoo.com',
4: 'kaliapradhan1413atwehoo.com',
5: 'pinkydevi69784atwehoo.com',
6: 'pinkydevi69784atwehoo.com',
7: 'pinkydevi69784atwehoo.com',
8: 'pinkydevi69784atwehoo.com',
9: 'pinkydevi69784atwehoo.com'},
'install_time': {0: 97.47996,
1: 68.29827800000001,
2: 120.708813,
3: 117.116056,
4: 92.686836,
5: 1.644209,
6: 1.6854870000000002,
7: 1.664857,
8: 1.6438000000000001,
9: 1.720515},
'fraud': {0: 0, 1: 0, 2: 0, 3: 0, 4: 0, 5: 0, 6: 0, 7: 0, 8: 0, 9: 0}})
df_temp
輸出應該只有最后五個“欺詐”行作為一個,但當前輸出是這樣的:
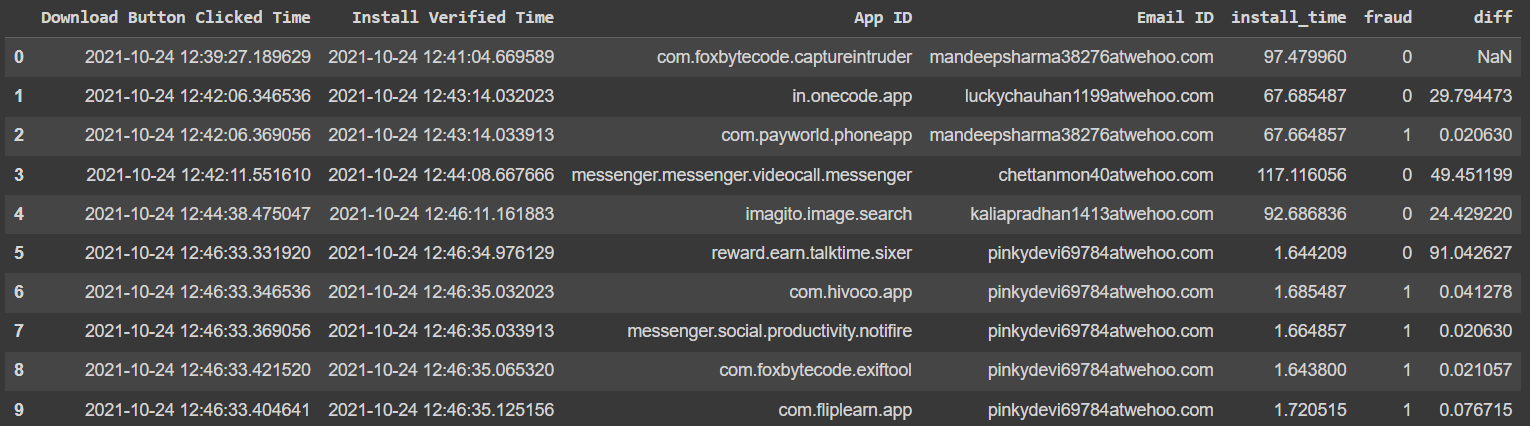
我用來檢測欺詐并獲得此輸出的代碼是這樣的:
df_temp['Download Button Clicked Time'] = df_temp['Download Button Clicked Time'].astype('datetime64[ns]')
df_temp['Install Verified Time'] = df_temp['Install Verified Time'].astype('datetime64[ns]')
df_temp['install_time'] = df_temp['Install Verified Time'] - df_temp['Download Button Clicked Time']
df_temp['install_time'] = df_temp['install_time'].dt.total_seconds()
df_temp['diff'] = df_temp.install_time.diff().abs()
def fraud_time(row):
fraud = 0
if row['install_time'] < 0.5:
fraud = 1
elif row['diff'] < 0.1:
fraud = 1
return fraud
df_temp['fraud'] = df_temp.apply(fraud_time, axis=1)
df_temp
我正在使用安裝驗證時間,似乎比下載按鈕單擊時間更明智。如您所見,不應將第三行標記為 1,因為第二行和第三行電子郵件不同。此外,最后五行而不是四行也應標記為 1。
TL;博士
僅當最后兩個電子郵件地址不同時,才使用 pandas.DataFrame.diff 檢測欺詐(可能是通過)。
編輯:對于相同的電子郵件,欺詐將具有非常小的時間差值(例如 0.02 秒),而不是不同的電子郵件。兩個不同的用戶在 2 毫秒內安裝兩個不同的應用程式是有意義的,同一個用戶這樣做沒有意義。
uj5u.com熱心網友回復:
關鍵是通過電子郵件對條目進行分組以進行連續安裝:
# I assume you have done this already
df['Install Verified Time'] = pd.to_datetime(df['Install Verified Time'])
df['fraud'] = (df['install_time'] < 0.5) | (
df.groupby('Email ID', as_index=False)['Install Verified Time'].diff()['Install Verified Time'] < pd.Timedelta(seconds=0.1)
)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/511897.html
上一篇:如何獲取百分比列以及值/計數列