在爬取豆瓣電影的地區時,被一個問題困擾住了。
我用的scrapy+xpath,可以取到的內容包括標簽之間的文本text和標簽里的屬性href,
不過這種兩個標簽的文本不會取,希望大佬給解決一下。
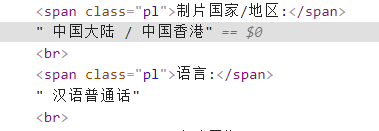
我想爬取的是“中國大陸/中國香港”。
uj5u.com熱心網友回復:
python嗎,為什么不試一下beautifulsoup呢,挺好用的,可以參考下我博客https://blog.csdn.net/qq_40832960/article/details/103854145uj5u.com熱心網友回復:
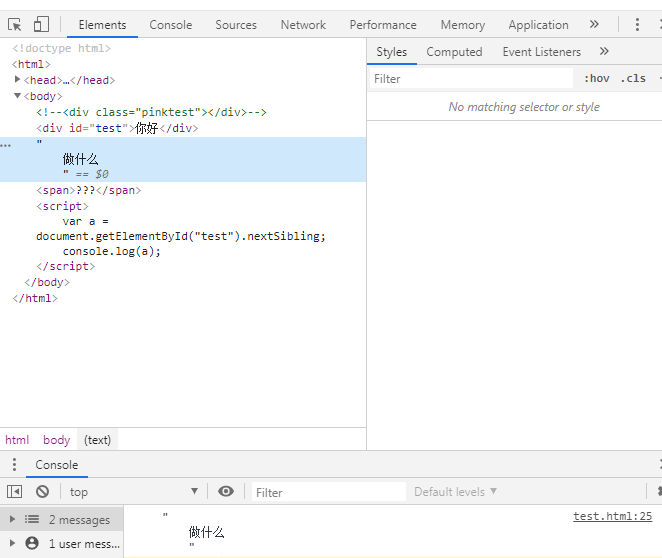
不就是型別獲取dom元素一樣嗎,獲取到document.getElementsByClassName("p1").nextSibling;不就行了
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/62598.html
標籤:HTML(CSS)
上一篇:求助帖 前端如何讓小程式官方生成的二維碼顯示到頁面上
下一篇:釘釘的第三方登錄接入。