Hadoop作為大資料的支撐,那么我們會有一些疑問,什么是Hadoop,Hadoop能夠做些什么,它的優點是什么,它是如何進行海量資料的操作的,相信這些疑問,一定在此時困擾著你,不要擔心,下面我們一步一步的去認識Hadoop這個神奇的的小象!
起源
從1946年開始計算機的誕生,再到如今的2020年人工智能大資料時代,我們的資料一直在呈現級數似的增長,在過去的十幾年來看,可能不是特別的明顯,但是近幾年的資料量,我們稱之為海量資料都感覺無法定義它的龐大了,特別是在今年的疫情面前,我們人類,我們中國的大資料的作用,為我們的疫情防控做出來凸出的貢獻,相信大家無論是在新聞還是網路上面都是特別的清楚——人工智能——大資料——AI這些新時代下的科技產物,造福者我們每一個人類!
然而在從基礎的檔案資料開始再到現在的資料倉庫,我們的進步無時無刻都在激勵著我們一代又一代的IT之人才,2011年5月提出了“大資料”的概念,
大資料的幾個特點:
1.資料量大
2.資料型別多
3.處理速度低(1秒定律)
4.價值密度低:比如教室里面的監控器,每一天都在開啟,但是真正的發揮作用的時候,也就只有在發現“美好的事物”之后,才會有所價值,
Google的“三駕馬車”改變了傳統的認知
依靠Google公司的三篇論文,GFS,MapReduce,BigTab,神奇的火花就這樣碰撞的產生了,為我們的大資料技術奠定了有力的基礎,具有劃時代的意義,
GFS思想
分布式檔案系統有兩個基本的組成部分,一個是客戶端,一個是服務端,我們發現服務端的硬碟和安全性不夠明顯,這個時候我們的GFS就解決了這個問題,
我們會增加一個管理節點,去管理這些存放資料的主機,存放資料的主機我們稱之為資料節點,而上傳的檔案會按照固定的大小進行分塊,資料節點上保存的資料塊,而非獨立的檔案,資料塊的冗余默認為3.
上傳檔案時,客戶端會首先連接管理節點,管理節點會生成資料塊的資訊,包括檔案名,大小,上傳時間,資料塊的位置資訊等,這些資訊成為檔案的元資料,它會保存在管理節點,客戶端獲取了這些元資料之后,就會開始把資料塊一個一個的上傳,客戶端把資料塊先上傳到第一個資料節點,然后在管理節點的管理下,通過水平復制,復制和分配到其他節點(主機),最終就達到了,冗余度的要求,
資料塊
存盤在hdfs中的最小單位
默認大小128M
元資料
查看fsimage
整個檔案系統命名空間(包括塊到檔案和檔案系統屬性的映射)
hdfs oiv -i 要查看的檔案名 -o輸出的檔案名 -p XML
查看edites
檔案系統元資料發生的每個更改
hdfs oev -i 要查看的檔案名 -o輸出的檔案名
namenode啟動程序
加載fsimage
加載edites
進行檢查點保存
等待datanode匯報塊資訊
datanode啟動后
掃描本地塊的資訊
匯報給namenode
心跳機制
GFS Master與每個服務器通信(保證它是活的),這樣就滿足了最大化資料的可靠性和可用性
MapReduce思想
主要介紹它的“分而治之”的思想,首先我們介紹一個網頁級別,對于多個網頁(幾億份),作為一個矩陣的運算已經無法滿足了,那么怎么辦了,我們就采用對每個小的矩陣塊進行計算,之后這樣的不斷的疊加,最后的運算和匯總結果,其實這個思想比較的具有時代化的超越性,不管是在計算機的運用里面,還是在我們日常的學習和生活中“分散任務,匯總結果”是最實用的,
BigTable思想
igTable 最基本的思想是把所有的資料都存入一張表,BigTable 的思想,利于海量資料的檢索,在大資料時代可以顯著提高資料的查詢效率,但是對資料的新增,修改,洗掉是不利的,
HDFS
HDFS是Hadoop專案的核心子專案,是分布式計算中的儲存管理的基礎,
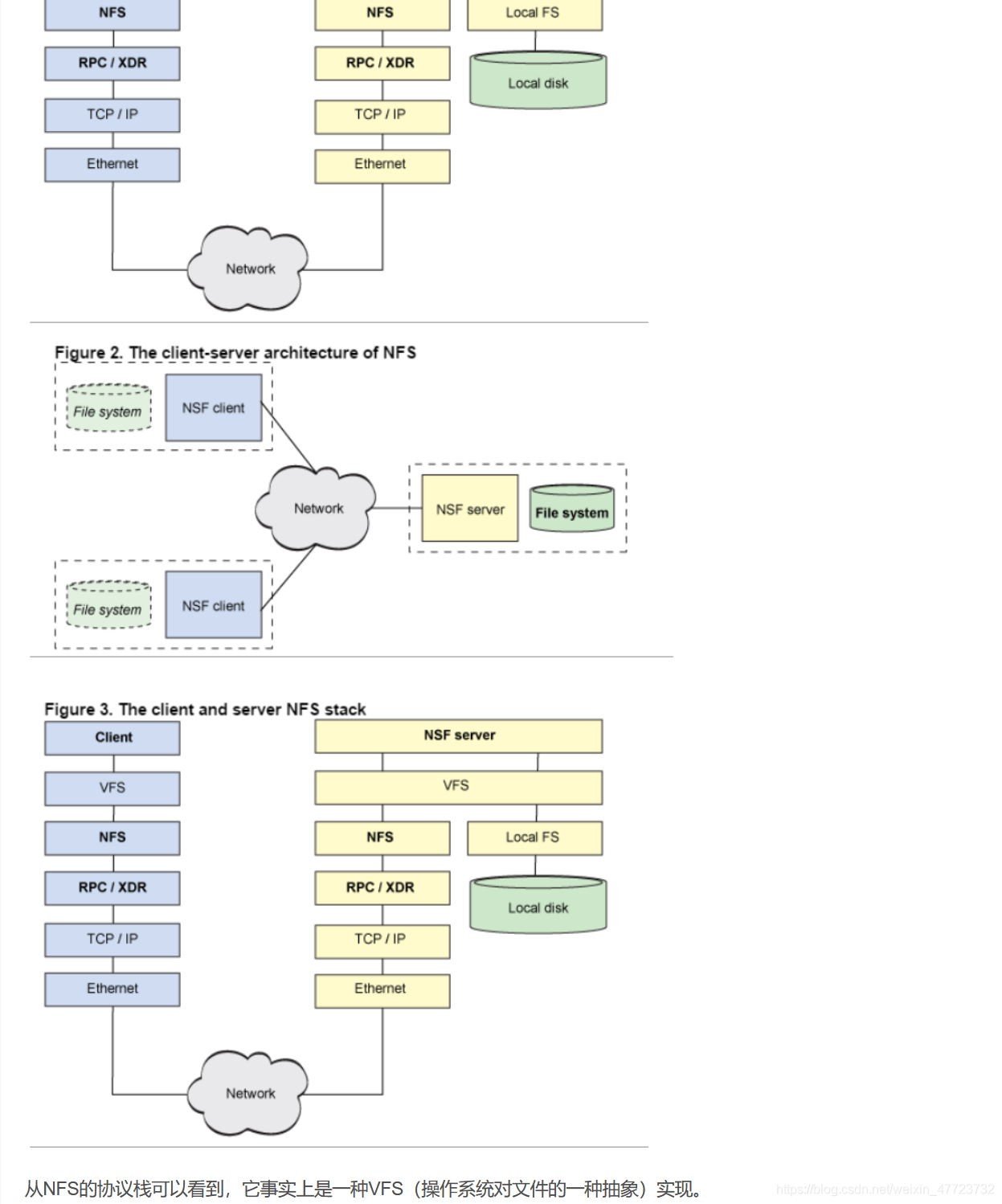
HDFS,是Hadoop Distributed File System的簡稱,是Hadoop抽象檔案系統的一種實作,Hadoop抽象檔案系統可以與本地系統、Amazon S3等集成,甚至可以通過Web協議(webhsfs)來操作,HDFS的檔案分布在集群機器上,同時提供副本進行容錯及可靠性保證,例如客戶端寫入讀取檔案的直接操作都是分布在集群各個機器上的,沒有單點性能壓力,
對于機架感與副本冗余儲存策略:比如我們的副本一保存在機架1上,處于安全考慮我們的副本2會和副本一保存在不同的機架上,這里我們保存在機架2上,對于副本三我們應該保存在和副本二一樣的機架上面,這個是處于效率的考慮,假設我們的副本二損壞了,那么就近原則從同一個機架的其他主機獲取,
Hadoop的特點
1.高可靠性
2.高擴展性
3.高效性
4.高容錯性
Hadoop生態圈
Hadoop的核心組件是HDFS、MapReduce,隨著處理任務不同,各種組件相繼出現,豐富Hadoop生態圈,目前生態圈結構大致如圖所示:

根據服務物件和層次分為:資料來源層、資料傳輸層、資料存盤層、資源管理層、資料計算層、任務調度層、業務模型層,
Hadoop生態圈的詳細介紹
Hadoop不適合應用于實時查詢的事件
Hadoop的安裝和環境搭建配置
這里提供一個安裝資料全套指導
HDFS(分布式檔案系統)
HDFS是整個hadoop體系的基礎,負責資料的存盤與管理,HDFS有著高容錯性(fault-tolerant)的特點,并且設計用來部署在低廉的(low-cost)硬體上,而且它提供高吞吐量(high throughput)來訪問應用程式的資料,適合那些有著超大資料集(large data set)的應用程式,
client:切分檔案,訪問HDFS時,首先與NameNode互動,獲取目標檔案的位置資訊,然后與DataNode互動,讀寫資料
DataNode:slave節點,存盤實際資料,并匯報狀態資訊給NameNode,默認一個檔案會備份3份在不同的DataNode中,實作高可靠性和容錯性,
Secondary NameNode:輔助NameNode,實作高可靠性,定期合并fsimage和fsedits,推送給NameNode;緊急情況下輔助和恢復NameNode,但其并非NameNode的熱備份,
安裝好之后,我們先啟動Hadoop
start-all.sh
等待之后輸入
jps
查看即可,就會出現上面的不同運行機制
HDFS不適合的應用型別
1) 低延時的資料訪問
對延時要求在毫秒級別的應用,不適合采用HDFS,HDFS是為高吞吐資料傳輸設計的,因此可能犧牲延時HBase更適合低延時的資料訪問,
2)大量小檔案
檔案的元資料(如目錄結構,檔案block的節點串列,block-node mapping)保存在NameNode的記憶體中, 整個檔案系統的檔案數量會受限于NameNode的記憶體大小,
經驗而言,一個檔案/目錄/檔案塊一般占有150位元組的元資料記憶體空間,如果有100萬個檔案,每個檔案占用1個檔案塊,則需要大約300M的記憶體,因此十億級別的檔案數量在現有商用機器上難以支持,
3)多方讀寫,需要任意的檔案修改
HDFS采用追加(append-only)的方式寫入資料,不支持檔案任意offset的修改,不支持多個寫入器(writer),
這里只是簡單的介紹一下Hadoop里面的HDFS,后期我們詳細的介紹的,
每文一語
只要選擇了開始,就不要停止腳步,沿途的風景再美好,也無法和終點的景色相媲美!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/66094.html
標籤:其他
上一篇:linux-day02