爬蟲的基本流程
1. 向網頁發起請求
2. 獲取獲取網頁原始碼
3. 通過正則或者Xpath運算式提取規律資訊
4. 獲取資料
以本人剛學爬蟲時寫的代碼為案例
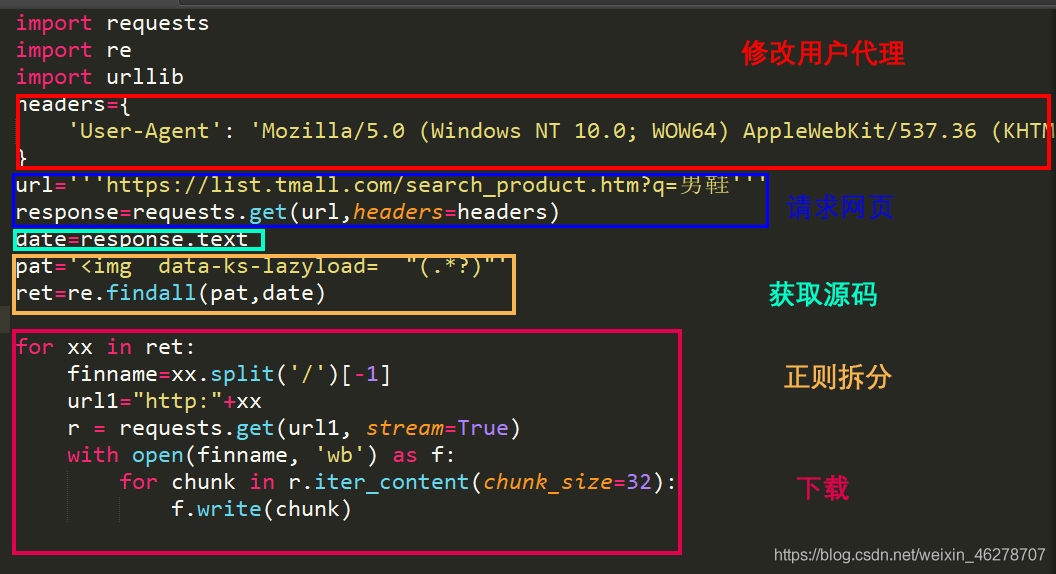
運行基本流程
- 請求網址:爬蟲通過請求網址獲取網頁原始碼 , 圖中藍色部分表示請求網站并獲取其原始碼 獲取的源檔案就為網頁右鍵——查看源檔案 中的代碼一致
- 拆分原始碼:在爬取出的原始碼中找出自己想要的規律資訊,如下圖獲取網頁圖片資訊:
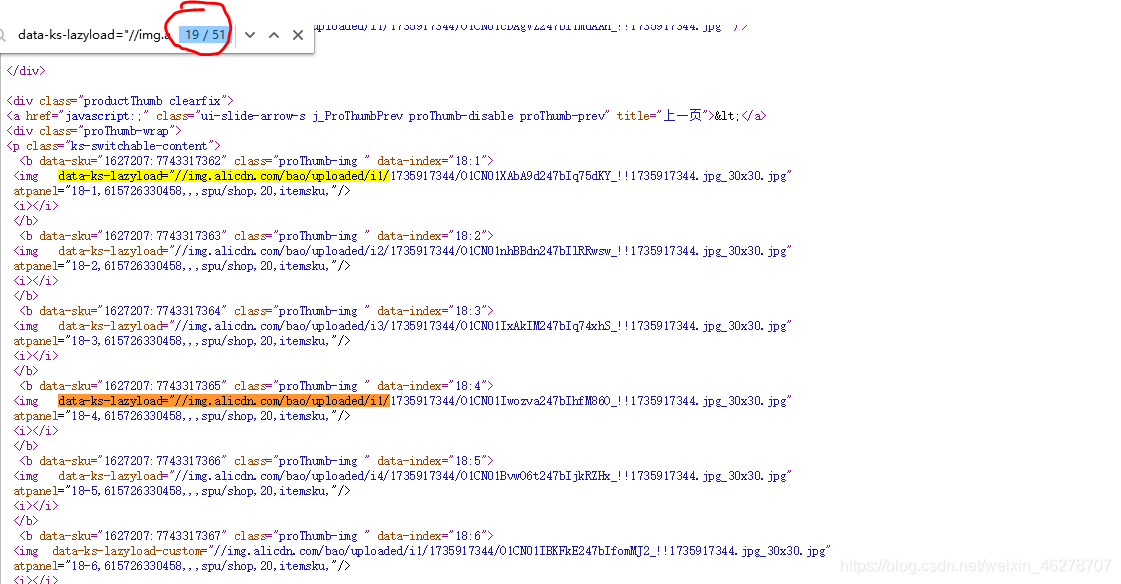
- 獲取資料:獲取資料后可以將資料保存到資料庫,制作圖表進行資料分析,或者批量下載圖片等等,后續有時間都會持續更新
代碼如下(示例):
import requests
import re
import urllib
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'
}
url='''https://list.tmall.com/search_product.htm?q=男鞋'''
response=requests.get(url,headers=headers)
date=response.text
pat='<img data-ks-lazyload= "(.*?)"'
ret=re.findall(pat,date)
for xx in ret:
finname=xx.split('/')[-1]
url1="http:"+xx
r = requests.get(url1, stream=True)
with open(finname, 'wb') as f:
for chunk in r.iter_content(chunk_size=32):
f.write(chunk)
總結
一句話總結:就是下載網頁原始碼,然后找出自己想要的資料,然后對資料進行操作,
以上是最基本的爬取網址流程,后面會牽涉到 用戶代理IP,抓包分析scrapy框架等等一些東西等著我們去學習 ,最后希望你能夠邁入學習爬蟲的門,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/81596.html
標籤:其他
下一篇:Python運算子